So many changes and bug fixes we made a curated list but we recommend you. Remember, it is an alpha, so you might find ghosts despite us having beaten the code as much as possible! Please use the forum and not GitHub for bug reports on TB2.
If you have 1h to check the folder examples/1-learning-examples we can cover a lot of ground there. I will also make a showcase of a few more things… and answer questions should you have any!
A few notes:
Keep your version of TB1 RC1. The TB2 download has everything, but is from another (much more daring) branch of development. We should have fixed all the bugs but we are not certain it is gig ready!
The many, many interface break should moan in your CCE window. The most important one is that datasets do not need a fixed size as argument, so most arguments have disappeared from objects. This is a lot more flexible as you will discover.
New stuff:
As requested, we have commented the tutorials in Max - the SC people should read them too (they will be translated soon) as it is simple Max yet introduce interesting database concepts with links to scikitlearn documentation.
Quite Improved:
Helpfiles - most of them are great, some ok, a few stubs but in those cases the learning examples are there to help
so many bugs fixed! Gazillions!
New possibilities:
dimensionality reduction algorithms (PCA and MDS (with 7 metrics)
making subsets of dataset via datasetquery
new buffer manipulation utilities in Max
weighted KNN classification / regression
dumping datasets (dump is all as json, print is a useful sample as string)
New behaviours:
the said weighted KNN classification / regression is now default
major interface unification inspired by scikit learn’s syntax to help tap into their learning resources
SC specific:
Redesign of language classes and server plugin so that Dataset, Labelset and the various models (KDTree etc) persist for the whole server lifetime, and don’t vanish on cmd+.
Dataset and Labelset will now throw an exception if you try and create two instances with the same name. However, all instances are cached, similar to Buffer, and there are now class level ‘at’ functions so you can retrieve an extant instance using its name.
Work on a much streamlined approach for populating and querying without so much back and forth between language and server is ongoing, and will be our main focus in the next alpha. Experimental approaches are currently at the promising-but-dangerous stage.
Known Issues:
Max: we have not got autocompletion working for the new objects yet, nor documentation. (You will get some JS errors with the help files because of that, no worries)
We hope to have the next alpha quite soon, and it should be bug fixing in Max, and SC workflow heavy. Send along compliments, critiques, bugs, questions… and keep some for Friday!
Still working my way through the examples, but loving the dict tie-ins!
And the corpus-maker will save so much time…
I imagine this is in the cards for the future, but being able to select/configure the segmentation and descriptor subpatches would really put it over the top.
There’s a definite CAGE-ness to it all, which is great!
Wow, this all looks super exiting.
I can’t even imagine how much work has gotten into it from @tremblap@weefuzzy@groma. And I can already see that many discussion points from the entire group have made their way into the decision making. I love this particular group dynamic and community.
No I will dive into as much as I can today to have questions for tomorrow.
Ok, instead of collecting all my questions for tomorrow, I’m writing them as I go.
What is the intended use-case difference between folder_iteration.maxpat and folder_iteration_2passes.maxpat ? They seem to create the same output. the 2passes version is way faster
the only reason it is there is that the first one is a first, intuitive, linear approach to the problem. The second is a second iteration once the problems are solved but in an expensive manner. We musicians tend to be good at the first… but sharing my 2 versions once I was tired of waiting for the loading show that a little knowledge sharing goes far…
In other words: loading files in a buffer can be done in one pass, and the cost is reallocating the buffer so the longer it is, the more expensive it becomes. so checking what you need first (total size in channels and frames) then allocating once then copying just the loaded bits saves tremendous amount of time.
This was useful to me to understand that memory allocation is expensive, and therefore that multithreading (which needs to copy stuff around all the time) is at times more expensive than single threading… so I left it there. I hope it helps someone to think differently about their own optimisation problems.
Don’t know if it’s a file count thing, but after around hanging for 10minutes I got a prepend: stack overflow error (from the prepend deststartframe near the bottom of the patch).
This was for 1057 files.
That was for the vanilla version of the folder iteration.
The 2passes one also gives me a stack overflow (this time complaining for the buffer~ with prepend replace above it. It just gave me the error message much faster.
Is this slowness intrinsic to buffer~s or how fluid.bufcompose~ works with buffers? Granted, I’ve not often tried to load a bunch of files into a single buffer~, but I do a lot with polybuffer~ and that’s pretty fast. Even for my 3k file library it takes no more than 10s. I guess the individual buffer~s inside a polybuffer~ are different in that they aren’t getting resized over and over, but one would still presume that they are being sized to fit each time you load a file into them.
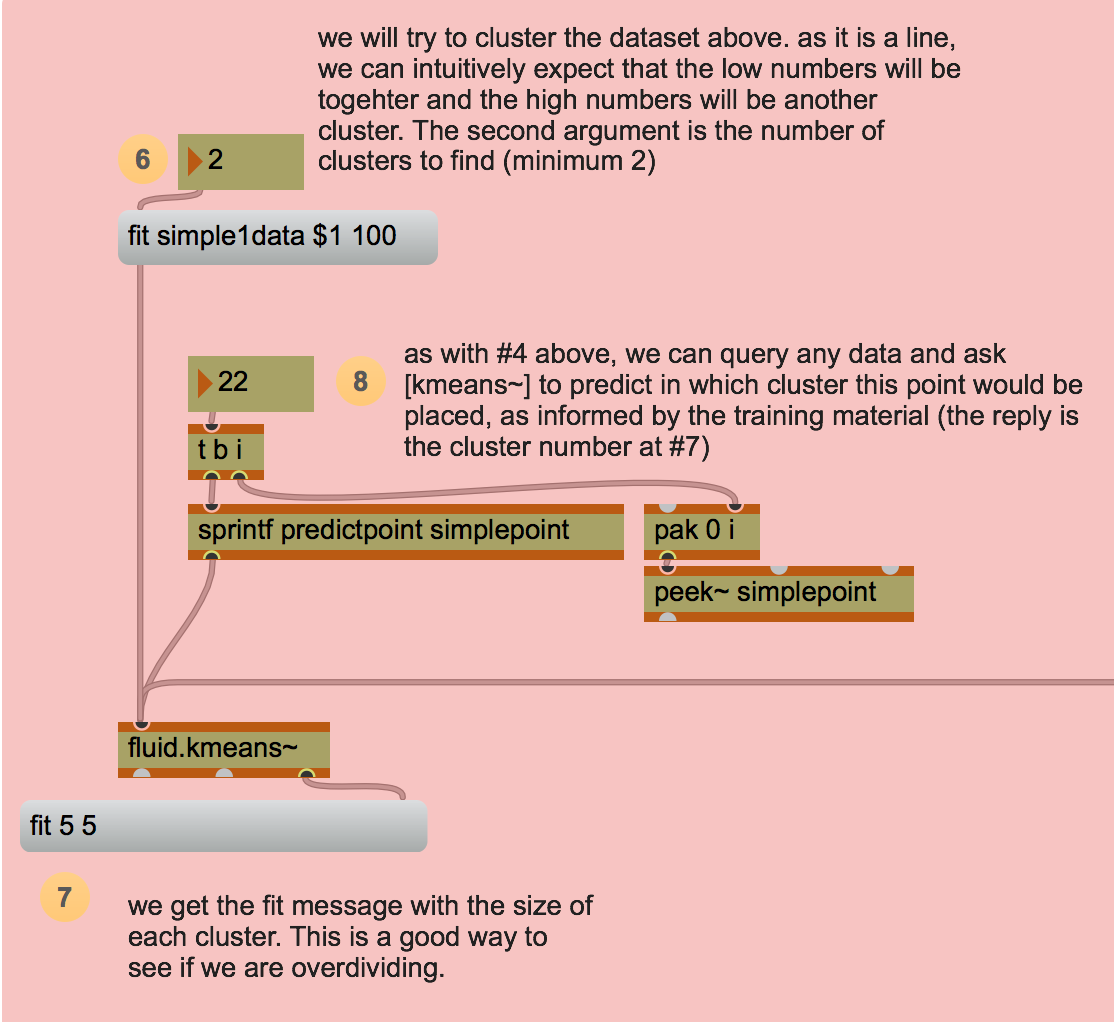
question about the 1a-starting-1D-example
I ask for a division into two clusters and see fit 5 5
when I then enter value 1 into 8, I’m obtaining predictpoint 1,
but any other number btw 1 and 10 also gives me predictpoint 1 - so where is my second cluster?
never got that one. I’m sure you’ll find a way to reproduce.
it is intrinsic to loading large sum of data. Polybuffer is not doing that, it is many small buffers with a table. 2 different beasts. I provide the patch for you to explore both, and polybuffer might be your best bet.
One large single buffer might be a solution for other questions, and the idea is to load it once and save it as is in tmp for the time being. Once it is concatenated, loading it should be as fast if not faster than the equivalent number of small files, so if you do fixed soundbanks that might be a clever way.
If you use dynamic libraries that you will reanalyse everytime, then maybe polybuffer is better for that. You now have the option.
the entry are multiply by 10 to create sparse points… but the query are at unity. You will get most probably under 50 and above 50 in that window to split. This patch is meant to deconfuse ID vs entry by making it confusing somehow. I’ll need to find another way I reckon.
Did anyone else get a stackoverflow error with the folder iteration patches?
Ok, I understand you now, but this explanation was even more confusing!
(so $1 is the second argument but the first arg?)
Right right. In C-C-Combine, I do long single buffer~s, I just then shove them into a polybuffer~ as well, in order to select which one I’m playing from.
if that is the way it is saved, then you should use this patch to assemble (faster) and just refer to the slice in your process (instead of parsing them to polybuffer which must take time)
Heh, it seemed that way, but I didn’t understand the original text, it was possible I was just missing something altogether.
In C-C-Combine, the files start off assembled, in that it’s arbitrary recordings. I did want to add a thing where if you selected a folder it would concatenate it into a single file for you, but never found a good way to do that in Max (this is pre-fluid.bufcompose~). In terms of segmentation, it doesn’t matter there as it’s just 40ms slices no matter what.
For future bits I’ll use this method and have smarter segments, but that’s a different beast altogether.