Quick report back to say that this approach is working (at least visually, not tested its impact on matching and training), and has a subtle impact on the dicts produced.
I used apply gain instead of normalize as the buffer~ command to try to keep them all proportional. Don’t know if that’s desirable or not.
Here is the “before” and “after” of running fluid.bufnmf~ on single hits (left) vs multiple hits (right) with ‘averaging’:

Some fairly big differences for some, less so for others.
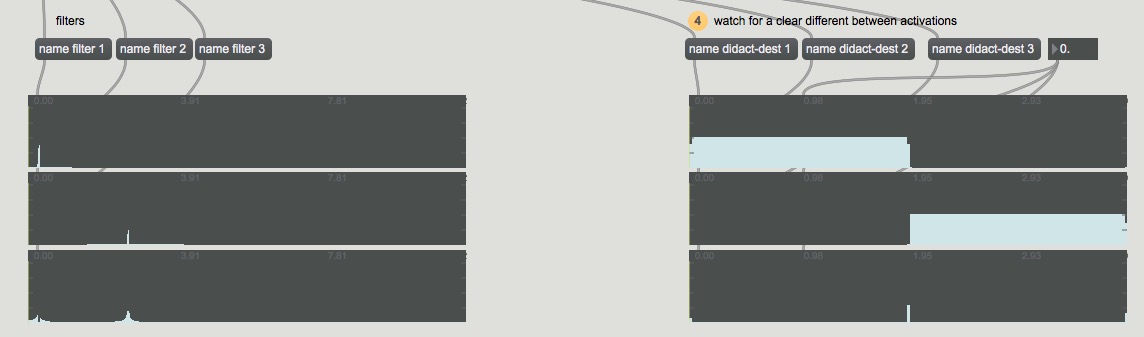
Now where it gets interesting is when I run the ‘multiples’ version again with @filterupdate 1 on an audio recording of a bunch of mixed hits (from a “performance” set of training). The regular multiples on the left, and the @filterupdate on the right:

They look (nearly) identical. If it wasn’t for a tiiiny change in the 3rd channel (circa 0.49ms) I’d say nothing happened at all…
I’ve fed it a 6 channel dict, and am requesting @rank 6 as output from the @filterupdate 1'd fluid.bufnmf~.
Should I request seedchannels+1 ranks (@rank 7) and manually add a channel of noise to the seed buffer?




 Problem sorted, thanks to
Problem sorted, thanks to