Hello,
I want to analyze sounds from a folder but I don’t want to perform an automatic segmentation after concatenation of the files in a single buffer. I rather want to use the transition between the sounds as segmentation points.
Before an attempt to modify the fluid.concataudiofiles abstraction to record the start position of each sound in the buffer as a segmentation point, is there any existing patcher/abstraction/object which would do that already?
Thank you in advance.
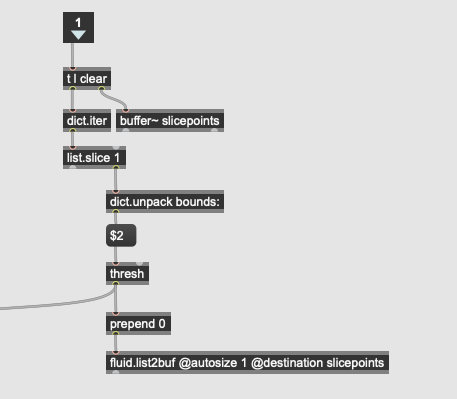
fluid.concataudiofiles tells you, in dict format, the start and end fo the files that it joined together into a buffer~. This comes ordered correctly, so you can dict.iter at the output of concataudiofiles and extract the bounds, like so:
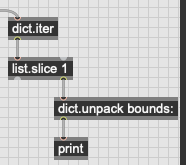
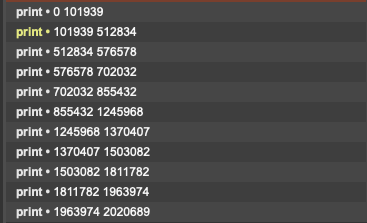
2 Likes
Great! Thanks, @jamesbradbury !
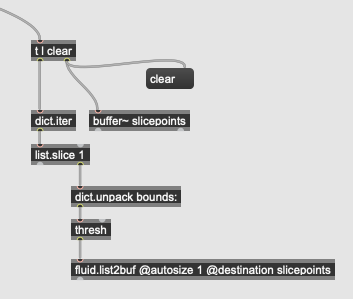
for the corpus-explorer patch (as part of the tutorial) I would like to modify the process so that the slicepoints are derived from the input files (see below). I’ve worked out some of this but am getting a bunch of errors:
fluid.bufmfcc~: Input buffer sound: not enough frames
fluid.umap~: Number of Neighbours is larger than dataset
it would be really great if there was an example patch that showed how to make a corpus from a set of files already cut up.
I’ve not personally used this example file very much, but this error will be to due with the fact that one (or some) of your slices are smaller than whatever the analysis window is set to.
Hey thanks for that. It wasn’t clear how markers are to be read (concat sends out segment pairs wihere the endpoint is the next start point) whereas the slicepoints needs unique points only). This bit of a patch solved the problem - but umap still has too many nosy neighbours!