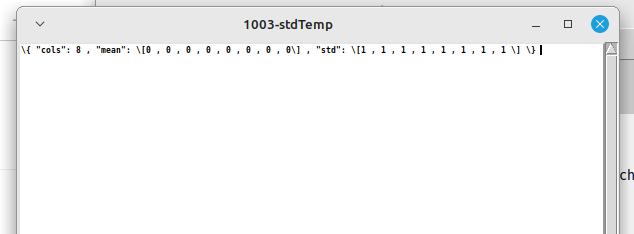
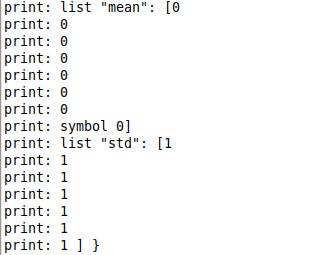
Hello,
a bit of an odd question here,
I’m adapting some max code from Rodrigo Constanzo in Pure Data which implies at some point the modification of “fluid.robustscale” state:
fetch the “Range” in the json file
multiply by 2
replace the “Range” in the json by the result.
Yesterday I gave it a go, I fetched the “Range”, I multiplied, once I had to modify the json I ended up with an incorrect json file, not readable by “fluid.robustscale”. This task is made quite complex by pd itself, I know there’s an external for JSON parsing ( haven’t tried yet ) but the goal here is to rely on Flucoma only, no other externals.
So I’m wondering if I could get some help to get the same result without having to manually construct a json file in pd.
for reference, this is what’s to be achieved:
here’s what the data looks like before the processing:
{
“cols”: 8,
“data_high”: [ -26.247343063354492, 0.241597786545753, 63.95220947265625, 0.081183396279812, -40.074893951416016, 0.244581758975983, 90.867919921875, 0.000858980114572 ],
“data_low”: [ -42.08658981323242, -0.129064902663231, 47.55539321899414, -0.309432119131088, -96.38632202148438, -0.207946330308914, 27.48699951171875, 0.0 ],
“high”: 75.0,
“low”: 25.0,
“median”: [ -33.885108947753906, 0.090700931847095, 52.845741271972656, -0.018240973353386, -77.57266998291016, -0.012044765986502, 83.26824188232422, 0.0 ],
“range”: [ 15.83924674987793, 0.370662689208984, 16.39681625366211, 0.3906155154109, 56.31142807006836, 0.452528089284897, 63.38092041015625, 0.000858980114572 ]
}
And here’s what’s loaded into that dict in the patch:
{
“cols”: 8,
“data_high”: [ -26.247343063354492, 0.241597786545753, 63.95220947265625, 0.081183396279812, -40.074893951416016, 0.244581758975983, 90.867919921875, 0.000858980114572 ],
“data_low”: [ -42.08658981323242, -0.129064902663231, 47.55539321899414, -0.309432119131088, -96.38632202148438, -0.207946330308914, 27.48699951171875, 0.0 ],
“high”: 75.0,
“low”: 25.0,
“median”: [ -33.885108947753906, 0.090700931847095, 52.845741271972656, -0.018240973353386, -77.57266998291016, -0.012044765986502, 83.26824188232422, 0.0 ],
“range”: [ 31.67849349975586, 0.741325378417968, 32.79363250732422, 0.7812310308218, 112.62285614013672, 0.905056178569794, 126.7618408203125, 0.001717960229144 ]
}
So it’s literally just “range” multiplied by two.