Bit of a stats noob question here, but I’m organizing and scaling data and for things like loudness, it makes sense to dbtoa things like mean/min/mid/max so I get a smooth linear output from 0. to 1. but I’m not sure what to do with standard deviation, which is in decibels (since it’s computed off the mean). If I run it through dbtoa I get a much higher value than I think makes sense, and it ends up more than likely being > 1.0.
The analysis frame I’m working on at the moment has the raw output values of:
The mean/min/max look good, but the std is all jacked. Similarly if I convert the other values and leave that one alone, I have a similar problem, though I guess they are all in the same “units” at that point.
So the question is, do I leave the values raw and then let something like fluid.robustscale~ sort it out, or do I scale (which I imagine would be better since it gets linearized along the way)? And if so, how much A does 2.4dB convert to?
I imagine I will run into similar problems with Hz and ftom when dealing with standard deviations of frequencies.
This feels like a super solved thing and I’m just too dumdum to know what it is.
More about what to do with it further down the line. Using the Example 11 as a model, things are packed indiscriminately(ish) together then normalized on the back end. It seems like it would be useful to linearize the relationship between each stat before normalizing (if at all) as that would be more perceptually meaningful. It was just the standard deviation that was throwing me for a loop.
In terms of the maths there, wouldn’t I want to do this pre-atodb-ing it since the relationship between std and mean exists in the log domain (as in, the std isn’t 1.31821 amplitude).
No, I don’t think so. I’m not even sure you need to do at all. I was just hoping to explain how to interpret the number you get. Standard deviation can be thought of as the average difference between your samples and their mean, so this additive relationship in the log domain translates to a multiplicative one back in the linear domain.
If you do all that multiplying in the log domain you’re effectively raising your linear figure to a power, which doesn’t lead to something interprable IMO.
hz → midi pitch is going linear → log, dB → a is going log → linear, so no need for acrobatics in the frequency case (although I don’t get why you’re linear-izing one and log-ifying the other).
I was trying to get everything into “perceptual units”, though I guess dB is perhaps better for that. Was mainly wanting to use dbtoa to avoid infinity at the bottom if I try to do a normal scale operation on the dB.
I guess in reality I would want log versions of both (dB and MIDI), and then move them into similar ranges later on in the process.
Actually, I thought I understood it, but I don’t think I did.
Presuming I’m going to put everything in log (“perceptual” units), for the standard deviation of loudness, I would still take that as a difference from the mean (mean - std (?) (or does it require the maths from above (or is that only when traversing the log domain as well))).
Actually, I’m still not sure what to do with Hz then, since it’s already in the linear domain.
Actually actually, I think part of what has been confusing me about this is that I’m expecting the numbers to still make sense. So if I’m (thinking) in Hz, 3k centroid makes sense, and a 752Hz derivative also makes sense, as it changed that much over time, so I thought that if I ftom'd them that it would turn into a weird representation (e.g. 78MIDI as a value in and of itself). Whereas what will happen in context is that these points will be in a messy multidimensional space, and it’s mainly the relationship between the numbers that will play more of a part. Is that right?
I guess it’s still good to have things in perceptual (log-ish) units so that as the numbers change, that correlates more closely with differences in perception.
Just to underline – that maths isn’t required for anything except illustrating that a deviation in the log domain translates to a gain factor in the linear domain.
If you were aiming to have things represented along more perceptually correlated scales, I would have thought that would be dB and MIDI pitch. Yes, it’s the relationship between the numbers that’s significant here: if you have a bunch of stuff in dB and normalize (or whatever) that, then the hope is that the resulting scale will be (more) perceptually linear.
I’m not sure where the derivatives enter this (as opposed to the deviations), but bear in mind that the units of a (1st) derivative of frequency won’t be Hz but Hz-per-unit time (Hz-per-frame, I guess).
Yup, that makes total sense. I was trying to picture it like setting values on a synth (e.g. setting the frequency of something as “2”, rather than that representing the deviation off the mean etc…).
For the bit about derivatives, that gets a bit funkier to think about I agree. For my purposes I’m grouping together a dataset of exclusively derivatives, so hopefully they will mingle together nicely.
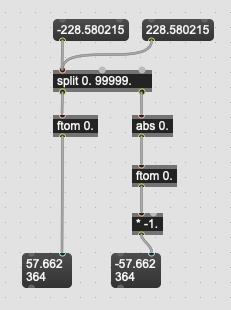
Last question with this (I think) with regards to the derivatives. In my toy examples (above) this was working ok as I just so happened to be having positive values for the derivatives (of mean of centroid/rolloff). But in testing it now with more arbitrary audio and I’m getting negative values for this, which makes sense.
To convert things to the log (perceptual) domain, I’ve been chucking it to ftom 0., but that doesn’t like negative numbers… Or rather, it puts a bunch of -999. in the subsequent datasets.
I was thinking of abs-ing it, but that strips away the directionality of the derivatives, which is largely what I’m after. I can also do something like what you mention before (mean(Hz) - derivative(Hz) -> ftom), but I suppose there could be a situation where that could potentially still produce a negative number (e.g. a low centroid with a large negative derivative).
I could leave the derivative in Hz, but that throws off a lot of the scaling elsewhere.
I guess these keeps the values in a sensible-ish range:
It does (potentially) double the overall MIDI Pitch space in that now it can go from -127 to 127, instead of just 0 to 127. But this problem only happens to derivatives so I guess that’s ok.
Is there any particular reason for ftoming after you’ve taken the stats, rather than the other way around? That would seem the least hacky.
A challenge with relying on the sign after ftom is that it yields negative MIDI values for frequencies smaller than MIDI 0 (which, according to mtof is 8.175799 Hz), so small deltas will give you misleading results. One possibility would be to ‘centre clip’, and set a zone around 0 Hz that just counts as zero-change, but that will be entertainingly inaccurate in the lower octaves.
Yeah, the more I think on this, the better an idea it seems to do the stats after log-ifying.
I guess fundamentally because that’s the available interface option… I’d sooner prefer @output pitch log so that all the stats are computed in the log domain (where relevant), but any deviation outside of the presented options involves a lot of peek~ / uzi → [Max maths] → peek~ again to carry on with the process.
edit:
[Actually it would also get quite confusing as, as much as I’m terrible at counting channels/indices, it’d be even worse if what was being fed into fluid.bufstats~ was in some arbitrary order which I’d have to know.]
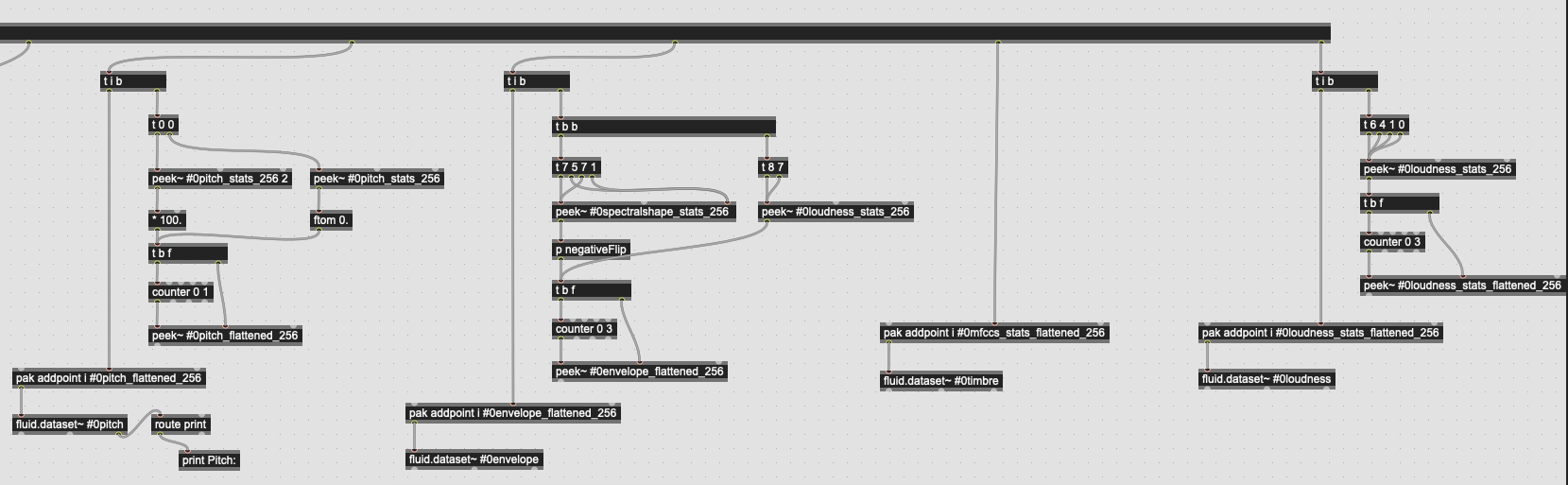
Don’t get me wrong, I do do this all over my patch. Actually, checking now, it looks like everything except my MFCCs processing chain is doing a peek~ → Max → peek~ round trip to get the values I want, and to get them in sensible ranges:
(in looking at this, I’d have a helluva time figuring out what’s actually happening here if this was someone else’s code, but that’s another (well-trodden) story)
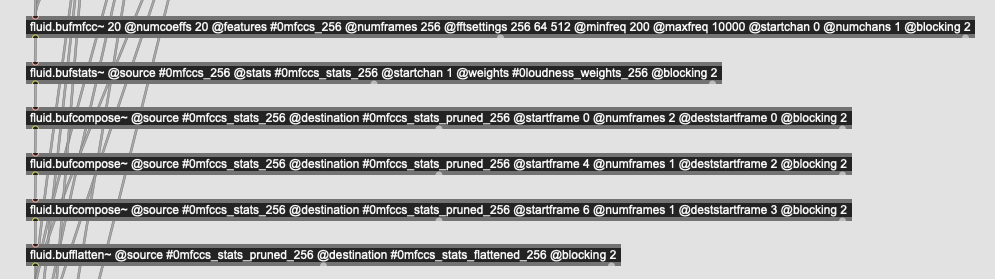
And even the MFCCs one is not without it’s funny business. Since I only want mean/std/min/max I have a nice cascade of fluid.bufcompose~s to put something together:
All of these are post-fluid.bufstats~ though, so it’s just the final pruning and scaling, though it would be ideal to do that pre-fluid.bufstats~ in all the cases. Or for that matter, if I’ve come out of the fluid.verse~ I can just do the stats on the list manually…
@unit 1 if we’re going to be all explicit about it.
For times where you do need to roll your own, you will possibly find using gen (non-tilde) more concise (box-wise) and perhaps computationally quicker than chains of peek~ (because it just-in-time compiles to native code). See the ‘gen-with-buffer’ tab in the gen help (basic idea is to run a loop in codebox).
It’s been a while since I mess with fluid.bufpitch~ so it’s nice to see that. That is quite an interface departure (in a excellent/useful way) from most of the other descriptor objects that offer no such options.
That’s a good shout.
I guess this may not have a straightforward answer, but are we ever likely to see selectable descriptor/stats options so you can pre-choose what you want to get at the end? I don’t want to optimize a workaround if in the future I can just specify what descriptors and stats I want (and in a perfect world, units) since I can remove most (if not all) of the peek~s in my patch(es). May still be handy for unit conversion stuff though.
Whoops, I knew there was something. The issue I’m running into here is with fluid.bufspectralshape~, which doesn’t have any units. I did now switch my fluid.bufpitch~ to @unit 1 to save some crunching elsewhere in the patch, but it’s derivative of the mean of the centroid that I’m getting the negative numbers with here.
It’s been there a while afaik. I guess because it’s the most obvious case. I guess the various level-based ones (loudness, melbands) could have a dB / linear switch a some point. MFCCs just do their own thing. Spectral shape is troublesome, insofar as that would be a difference between taking (say) the centroid and just translating that value into something log-gy on the one hand, and taking the centroid of a log-spaced spectrum.
I’m sure I said something about this like only two weeks ago tl;dr just do your patching, because even though I can see technically how it might be done now, it’s far enough back in the queue of things to do that I don’t know how far back it is…
Then I’d gen it pre-stats to get it into MIDI pitch first.