So… some exciting new changes have made it to the nightly builds of the FluCoMa Max package. This change has been in the works for some time now and aren’t made lightly. Lots of documentation is needs fixing and overall needs to be updated to reflect what you’re about to learn…
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Let’s say we want to get the maximum spectral flatness over a buffer~. It would look something like this:

In this example we have to name and manage five buffers (including our source). Lots of advanced users have asked for a way to reduce the amount of buffer dancing they need to do when FluCoMa-ing. We agree, this can get tiring to patch around and generally is a source of all sorts of foot-guns ![]() that can lead to sadness when you’re trying to think about ₛₒᵤₙd.
that can lead to sadness when you’re trying to think about ₛₒᵤₙd.
So…
New changes to the buffer~ interface mean that you no longer are obliged to provide buffers everywhere. For example:

As long as the first object in a chain of buffer~ processors has a source the output will be passed along to the following object. It does this by every processor having its own internal buffer that it can use as a @destination, @features, @stats or whatever. When you don’t supply this output attribute, the object will use its internal buffer instead. Every buffer processor understands that the buffer <somebuffername> message means “use this as an input” allowing you to arbitrarily connect any number of processors together without worrying too much.
And…
Theres more! We’ve also introduced a new set of attributes for @selecting different channels of audio descriptors and such. The first two cases that people often found to cause friction are fluid.bufstats~ and fluid.bufspectralshape~. Gone are the days of fluid.bufselect~ing channels to extract specific descriptor features. The same patch even smaller:

Okay but what about fluid.dataset~?!?!?!
We got you.

can now more easily be patched as:
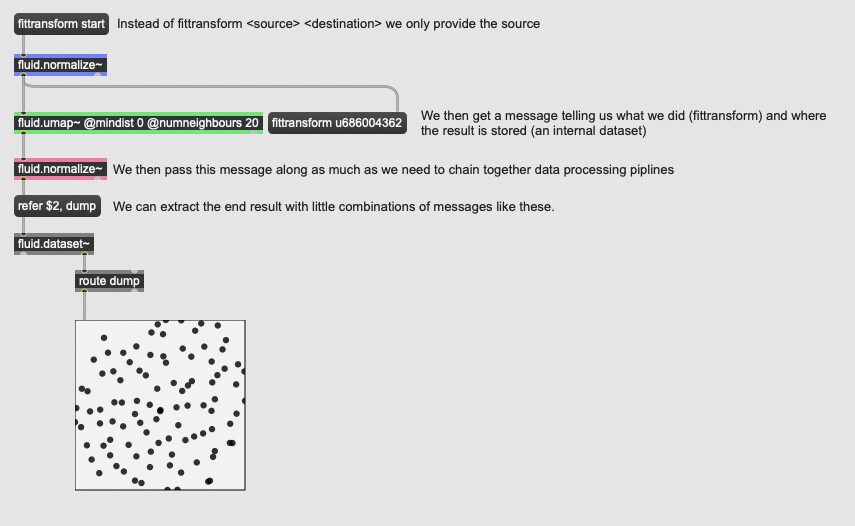
Much like the fresh buffer~ interface internal datasets can be used if we don’t fittransform <source> <destination> and instead fittransform <source>. Whenever we call methods like fittransform (with or without a destination), the object now reports via a message out of its left outlet what it did, and the destination dataset~. Objects that deal with dataset~s can use these messages to chain together more easily and without having to manage a bunch of potentially superfluous objects.
One caveat of this is if you need a different message to
fittransform. In this case you’ll need to usesubstituteor form your own message.
I want this now and I don’t care if the documentation is a bit broken!
Go download the nightly builds here: nightly builds
and play with these two patches to wrap your head around the new interface. Feedback and questions are very welcome!
auto-buffers.maxpat (12.7 KB)
auto-dataset.maxpat (20.9 KB)