Firstly, having spent a couple days finally playing with the latest update I have to say that this is profoundly easier to use. So much of the friction is removed, and it’s a lot easier to pick and choose what you want, and not have to go on a buffer~ creating/renaming spree every time you want to change anything.
EXCEPT
I have no idea what the intended approach is for combining:
-
buffer~s at the end of a RT processing chain -
fluid.dataset~s at the end of a corpus-based processing chain
Before, it was “counting indices” the whole way down so having to be specific about how many channels and samples your buffer~s were, how how many deststartframes you had to offset, was just how things were. (my eye starts twitching even thinking about it…)
But now I can have quite simple and elegant descriptor/stat processing “verticals” that are super easy to code, modify, and tweak.
The problem arises when you then want to either combine the resultant buffer~s (e.g. loudness+stats, MFCCs+stats, pitch+stats, etc…) into a single buffer~ to then feed into a fluid.dataset~, or you pack each descriptor+stats into a fluid.dataset~ and then deal with the juggling/shuffling down the road there.
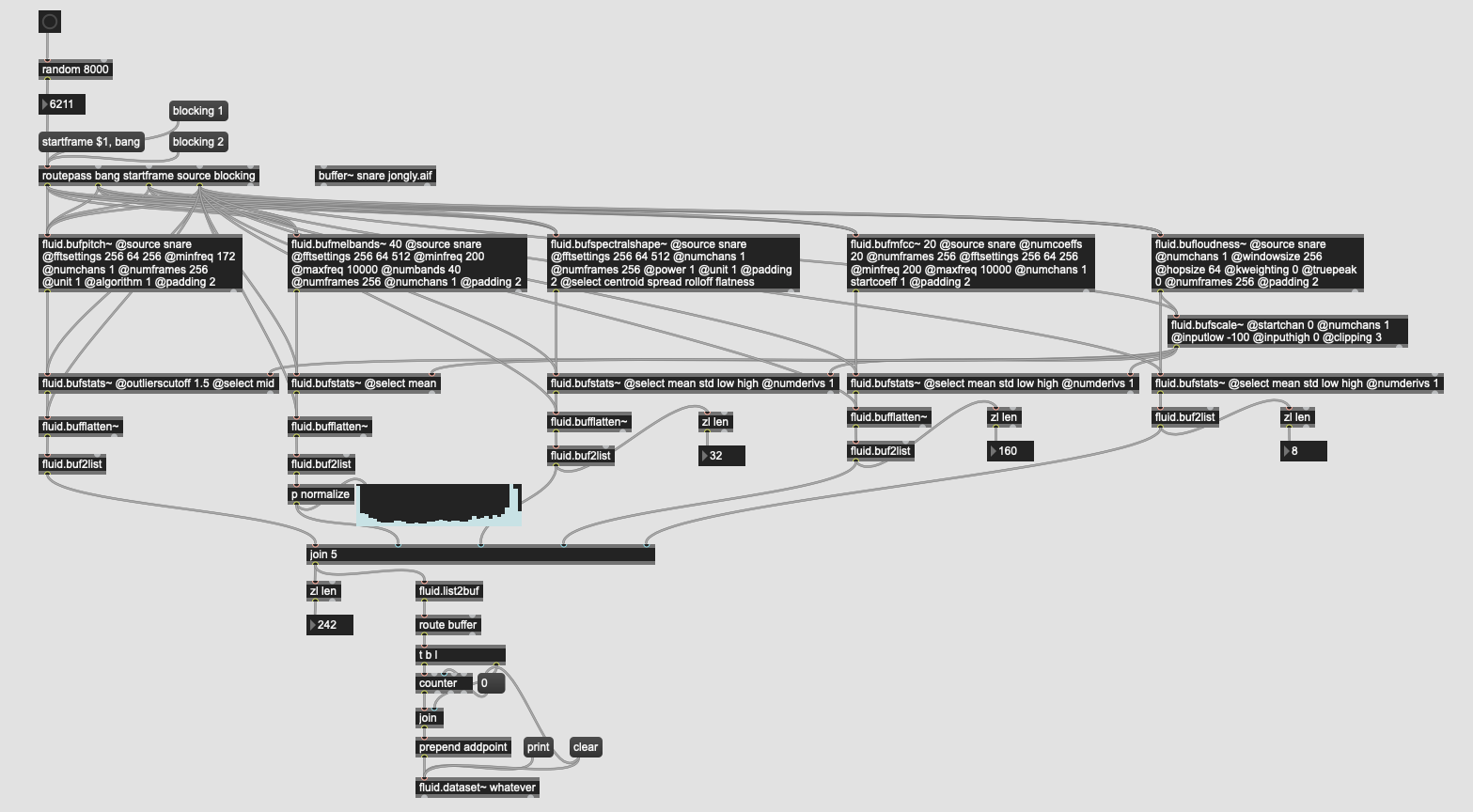
So here’s an example of a RT use case:
----------begin_max5_patcher----------
2974.3oc0b0sbihiE95jmBFWycaFW5Ojf8prOGSMUJYirCciAVPNIyL0jm8U
RXrMNhXYaIR1tp1oPByQmuy+GIyee+cyVT8lncVz+N52it6t+996tyLjdf61
c8cy1veaYAu0bay1HZa4qEydnaNo3MoYbP+Hka2jWVHjlaGsav7LyMUs3G+F
I8n6rZqr+Vg6FsaH4eVK5VVylE8G6lplKW9bd45mZDKkcyFSXyAODwHX8ePo
yiUehlCh9C8W4et+d8GO3HuUJdUsB+.qIiVDUXk8fVXOlc1CMF6sfWtd1Cmg
MIIPCaBMrYZbHXyeTkW5rPj5SgXO2k.BmPbY01RonwJCFagAI1YPxXLXdozH
E28e8ktvxc5sTyEWMKOlM4xBAuwYQJzmhTJIVyRIPCmgiuI9aDQZcinVTlEw
yxpqL3ualn3z.n7tiSg.THX0F0ZRDsX6pUBmEn33KzSjqdgnp+fALF.kjljx
RgILklLHHpv0MiIXswwDuFZIkdrJbPjqqJ1lmMOiK4sB46Qu9LWJdYDQrMMY
PfDwIwDi1bH45h7VIRoR6JyhtTyVMAbReV4q5i5y2FmuXqTVU5LqsOogZdCe
iPEn5IQIeQggU.WFaaRn3yXaV5bZJJNEhRXLHBPRTp2LSPWiTW+oWcdwKyp1
Dk..NmjHL9Bk0mKdqMdNwjngZl.nh24p98n1RdiH5GUkqK9y47bmU1gvKzxd
UQE2jAxYE+XVmTFfmSR0+KNAwnLhVqGhtQzX6lEt69hd4Z8epmsyy5TxbJ.E
SSHJFVw2D3HgyhAgPq3uJhJDNmjMy2N2sy9179gYgf80UXDE6ZJ3w9LXtcVG
nJjhEm.XwwIX.DgfZVGNmnRiigSnoIXDjxBPdMKJpV9S0RLB5tKQrOADDLsK
BOYNVgIPBBkh.HDSiK3fjK2ddF4NOiBAOSYezy2MxyWliO3glfLUt9fDvN2b
wD.REC.QUg.Ipbb+V56CF68TaGAAn.+696BUFXStx.HwXI78U7SR7t3umm+F
Hvm7DeXIlxYhAvuqxahuk26XYBcxRuoqrVcl+EboTT9t6JDPey8TjUecVvhT
PPwBjoJbmUCv9tFeq.gU6.F5alRg2i.lR.NF.7akRA16M9wNPXKXXfUJtPff
4af.hT0E4lJQfQhVIW19dzishB0pKZifWF0JyhJpdM5470OG8nhmyDM4uzdA
0LgQdOMB6HFRMntJJFJMIAhRnTUTFHLX6EPs5lhzg8UfDuQtRmFQTa01lkhn
95rbsPaHdjvOweJJc7+uzVuYs4SnvrMQWuGXj22AEaXAg8c2ALB4a+N1vgXP
57XJhEiA.FMAQiSCkWm5nxplM7h7+R3bK5S7Z6n5a51frRHn4Plx6ACjFmx.
.HRuk+G.fiedpxM5X6c78cyVkWn26n17pxiVX2MiWWezv2czWQCV+nx7fRdX
+P4kcCg2OTi3k79uOX+n7FEWIUrz1FCOO6MZeR75GSkxYc41byRoaPkXa2Rx
HfJUtrZq4K69xZ4X+zGvojtsgpqqzThwnfnOl.8fgRAXs1cmH63E2rpZQYdY
cinUTpBrbxZeVlXEeag7oUUkxVsRfdQp0zrL+pcqPqSp4Ayx++zjyK1y.qax
ypJ0KhARB8v8jSEIw3sS+4AlwbGk7ZKeYkRnBVFYRczyssK3MZA0t5HQ8SJq
pJFN09uWgXkb2z04kkmfhxp5wmrQET9S9tKpTSt4yd1lYZeZaY2rOozIjO0x
eYHZK4EE6rhG93eiWlugKEx7NQ.BrextZoetcYSUQw.9salWrLSlRGeo307L
4yFBcrxf51yq6UhlsWJmkuVzJGNljutc3Hsx+rCzOZnsK1YC+jTroVEV5jaP
Ycn7f19b0qs6twdEsiAfCGbqisoO1k3fw+LWiCcOxkUYKNdFaNG+PThS9Bez
G4Y7SN59v2cRYL193S1dp65CIry+h+whrExJ9khE3PgEjDC+2su0SOX7K+lx
vXTv.Mhhw0pYzsklmCRfftCdCKw1gGK7Xh59x2rcy0.LehZB57.yImxrygOX
Z2ANap0YjQE6O8jt6LgbkPyfLvG0iBn6nZA9ZzXdQ7VcSzutBF8uTehT07tj
WvazYLEAuXknT2rtFIUGGbCMddNeJ7h5bOAYzfnwY.lQAKfcvhRtRWQCJn4L
7MatovVcAc.PRJR2IftfWGm2pIM3pMaDkCyfvrhKyDucThydAv53oK0PjFON
hAbANvHfAOTk42gGXOiGGRdtHubrThLKO871AptFmrSV2qnDMbwoRCTlWtuV
heeeVOQtpXeoKBriqAsLJXKBs+EmVE3PtHbVbjF5UAzkUQPwBWUKfgT2r+g6
lDAFpUgqKBxnPwtA66MwLcAnYO0Ur8SborIewVYmakia1xEUT35hpE7hSpjy
VMi2eXwcom4lsEx71h7rCaCcqxMcesmvOqKWpaTMp5w0gXcIGcT+lFjKO452
559zOHfq+3ICSbruY6x6fD+coYxPr2ONe1Zh32+tIC8d2js2M0PzN4K6bdfl
7i4gk1pqLK93VsDGlesFGsWT+J7gnteZaNpV.7Y+0sBD1N1ePHdp2VS2QDvz
3wv1dWBogEW1HJTZGYJng.TnS2FW1cX4eb0JoJjjJL951HTLMhRhhgpxjUv0
pFw+U2oW0E72LWnPI8kZKS8yy73TWXTB6955KW9LurUkFxi07rrAGAUc1Fle
afG+q66bV1oIShjQ47ZdJROLAPTptpIUCFa12.5+WsQ7ojo4.NoTkgw3DbJi
RUA+PvjfsM7gEvHwSyg+YBO2Be.vz7Ptnoc4VY0pUpTNiO.hJnvQjhxljMo2
FPo7tDTfpNWs1d2A2iF2b8tGgLzPedm3NbaYtTOLuXcUSt74M9yuHhNExB6t
Egrv5VrVslZ3EsOyqEu6ZHqOQLTW8pnQOdu7XuHXuUvRQoroJOKpstQvyhza
Zo1RQW6QoJEraSVgRlDex1kVzzfJs1rZ4x2UIJbpbRKOpDqV0Zl6DIx4LrFI
uidArI4WyS2eFTX1jDFPkN7bnNvIIESwXUgzXsLhDVKpk7BikjA2TfXzP77w
7xZE6ohhpSEd2kl.ppKVVjWWqwWrU7E4H9x7+Oy.8lypBTDSn..NAlDq6FAl
BskIGs+kiPP.3hpsYZ2DuayJnGjeMuLq5UcqY5T1etp1bgR4+we9pPeHOzvr
BxkMaE0B9Oi9nkimhdLMmUS6J6HpUkcyie3NKzIZNsUk6DPenEkjA8Oej9Sp
+0On76aWIvYJAcgRCWNUMYcGjLvsQZlqLI3VYRpCTBm5CJwNta+iwSzCc29p
oDN1Ezi4Cdh3Bkn9fRtnLpe8UXSYDdavY5EP5ahRHmnTrGnDlLU7jK5hnf3D
A5Bo08T81kat3tBFOQnIKDFAtvg9vN2b1vOKk7ATpKWwIBA8thIA6HoQ9VLB
cxYllzX+SZlijl3aRm5hn1zd7aVqJ0EGqPBzCjh4BWkRrqACCOooL6jFGdRS
BhcKyc0HKzFcSzl5THFjObLRbJtIwGVKN4RfLYd6gCOWP9xZAQc0Z4l4Rjy9
DtYR4RlHIgHuNWnr4Gpo+kjl2YNNPbe3d27tpYxnEvIadeTGr4UwgCzh4EZ4
V3Xuj4pSY0c5JxaoTBch3XuvnNor3kll3V9pmpR4KPE6VccfvPb2L+8hYB1E
smzQ.YrGnM7Kj1nuPZiuRZCgSAwGwUEaBnMKPVztPa5XcPYJj3mj88dhSl.K
bbPZcjaV3gj1nuPZiuRZGOAx6SJLwq5ZvuPZi9BoM9JoMbJLvOs9PO0bBGk3
gj3nuRhiuVhmLEx7vEHE90QZzWGowWGomBEsSKCbOwoSBwAecIJGpF93FwQi
jzFbRD5C+E7cf5oSAwAism62noFxscuE4k8bzo956CJAcpGQdYSogNwV8Qlt
MRAbpiPPuz8IvU1UztSd0Iu7pzT4jWZUm7Bq5iurpF+EU0oujpL+HPG6kS08
+y8+OIgmrf.
-----------end_max5_patcher-----------
This seems like a super archetypical use case where you are analyzing multiple descriptor types and related statistics. The upper part of the code is a breeze to use, even with all the min-max-ing I’ve done with the @attributes. It seems like this is then begging for an easy way to combine them. I’m going into zl-land to do this, which obviously works, but it seems like a hacky workaround to something that is, surely, a fundamental use case.
The same problem exists with fluid.dataset~s, though I have already made a thread about that a while back. @weefuzzy’s abstraction there works, but I don’t think someone should have to go digging through the forum to find an abstraction to do something that, again, seems like a core requirement for working with different “descriptor chain silos”. Nor do I think having to, out-of-nowhere, start having to keep track of amount of channels/samples/dimensions in order to do anything as that undoes all the utility of not needing to define your own buffer~s and use @select to pick only the bits you need.
In short, the automatic buffer management and @select is a game-changer, but unless I’m missing something obvious, the utility of both of those stops at the bottom of the processing chain when you still have to roll your sleeves up, squint at the screen for a while, and count indices to carry on coding (which is error prone, fragile to changes in @selects upstream, suuuuper tedious, etc…).