Revisiting this analysis frame thing today. I’m trying to build a kind of slow-mo envelope generator by using the loudness (and eventually other spectral descriptors) on a frame-by-frame basis so that a single attack can yield a variety of envelope contours, and when unpacking the loudness frames I can never get an envelope shape that seems correct.
So at the moment I’m doing this:

And throwing out the first three and last three frames, so taking frames #4 through #10.
My thinking is that there will be real audio in frame #4, as opposed to being zero-padded.
That ends up giving me attacks that look like this:
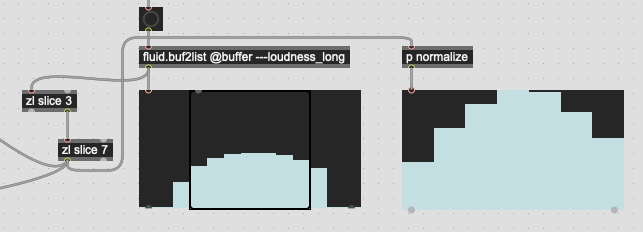
And this:
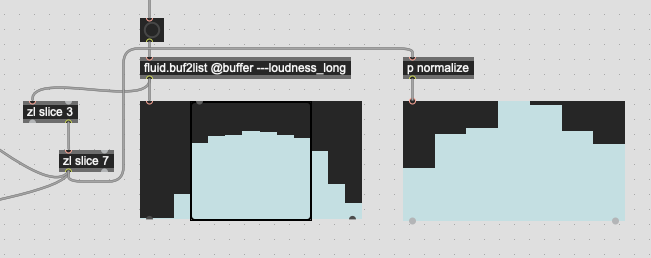
(that’s normalization in dB and then converted to linear amplitude in p normalize)
So with this, the loudest frame I get is frame #7, or frame #4 if I count from the trimmed frames, which corresponds with the analysis frame that is full centered in the analysis window itself.
This, however, is not the loudest frame in the overall window as these are percussive attacks with super fast onsets.
It makes, computational, sense why this is the case as the loudest part of the analysis window is generally preceded by the silence (digital or otherwise) prior to the detected onset. But this isn’t really intuitive as, perceptually I would expect something more along the lines of this:
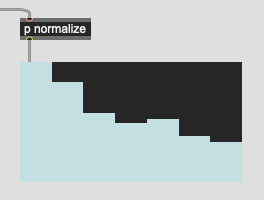
I’m thinking that mirroring here might give a more (perceptual/intuitive) set of values since it would, presumably, have the highest amount of energy centered around that hop of the analysis window. Or rather, folding, to use @a.harker’s lingo from above.
I think that would require dropping another analysis frame too, so only taking from frame #5, which would be the first frame that would be centered at the start of the analysis window.
///////////////////////////////////////////////////////////////////////////////////////////////////////////////////
Am I thinking about this correctly?
What’s normally done for short/loud analyses?
Up to this point, particularly with summary stats, I’ve been taking the mean of the whole thing here, which, if consistent, should correspond to a comparable descriptor across the board, but if I’m interested in the specific envelope and contour of that short window of time, I feel like there’s probably a better way to approach this than I am presently doing.