Can we push forward with this approach then and then merge it? I would hate to have all this other juicy stuff being worked on get merged into a release and for this great contribution to not make it. I can lead the PR if you’d like to offload.
2 Likes
It will be merged when I have time to do the PR. it won’t happen before the next release which won’t happen for a certain time anyway - loads of plates in the air and new features.
What can be offloaded when we release is the QC on all CCEs if you want to help ![]()
There are still questions of naming and interfaces that need addressing on GitHub - @balintlaczko has been fantastic and patient with me and my thoroughness - and it is a fantastic PR and addition so don’t worry it’ll be in for sure in the next release.
There has been under the hood (in all wrappers) some significant changes that I hope people are trying on the nightlies. that is what will trigger the next release (when I’m done with SC and it is tested) and this will deffo be part of it (alongside a lot of @MattS6464 work on typo and clarity) but most probably not with the new 6 objects (one of which is in public test now, 5 more coming)…
3 Likes
Wow, that sounds quite busy, I had no idea! No hurry with the PR, I addressed your comments there, @tremblap, mostly just lobbying for keeping refer.
…and while you are busy with other things I plan to add another mousing mode, the “pan-by-dragging” which I often sorely miss with large datasets, having to zoom-jump out and draw a rectangle at almost the same place quite often… It might take some time to figure out an efficient-enough way, so if you guys want to go ahead with merging, that’s fine, I can open another PR for that later.
1 Like
just keep pushing on that PR until I merge - if you add features now I can check them - I am likely to check that later next week
1 Like
Ooh very exciting!
Any info on what they may be?
Also hopefully there’s still some bug fixing going on as I have two coding ideas stalled because they ran into bugs that are impossible or super clunky to code around (1, 2).
the problem is that I even hesitate to say a number ![]() imagine if I give a list, and one gets removed…
imagine if I give a list, and one gets removed…
Bug fixing is not a mega priority if they don’t crash - especially when they are about comfort more than actual bugs, and controversial ![]()
In all case, you should see more stuff soon, the team is working hard.
thanks for your enthusiasm
1 Like
Just curious of the category of stuff being added, as even if they aren’t added now, that means they may be added in the future (and/or inspire better coders than me to help chip in).
The couple I listed there aren’t so comfort related. I don’t think fluid.bufampslice~ is working as it should be, and will always miss the first onset when used, and doesn’t work properly when using a different @startframe / @numframes.
The buffer weights in fluid.bufstats~ can be coded around but requires a massive amount of plumbing to do so programmatically, since you need to manually check/resize/move/copy/crop everything going to it.
Added the new panning mode now (using Shift + drag), soon will update the help + reference too

4 Likes
now merged into the main branch - available on the nightlies for the world to test ![]()
thanks to @balintlaczko for the amazing work!
2 Likes
ok I spoke too soon - I have to fix the Apple code signature dance on GitHub. I’ll report soon
ok fixed. now online
1 Like
Just ran into some mega speed issues with the native fluid.plotter so definitely see the benefit of using this!
(loaded up something with 50k points and it’s as slow as molasses)
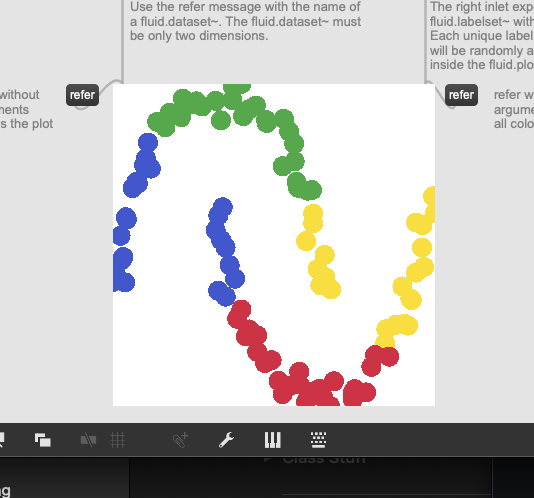
I haven’t kept up with all the updates here and on github but does the jit version of the plotter let you feed in two dicts for class/cluster coloring? (I see some diff colors above, but not sure how/what that is).

Yes, it works with dicts too (the old interface), but I seriously recommend using it with the refer message, because it is much faster. Take a look at the fluid.jit.plotter help from the nightly release, or here for convenience:
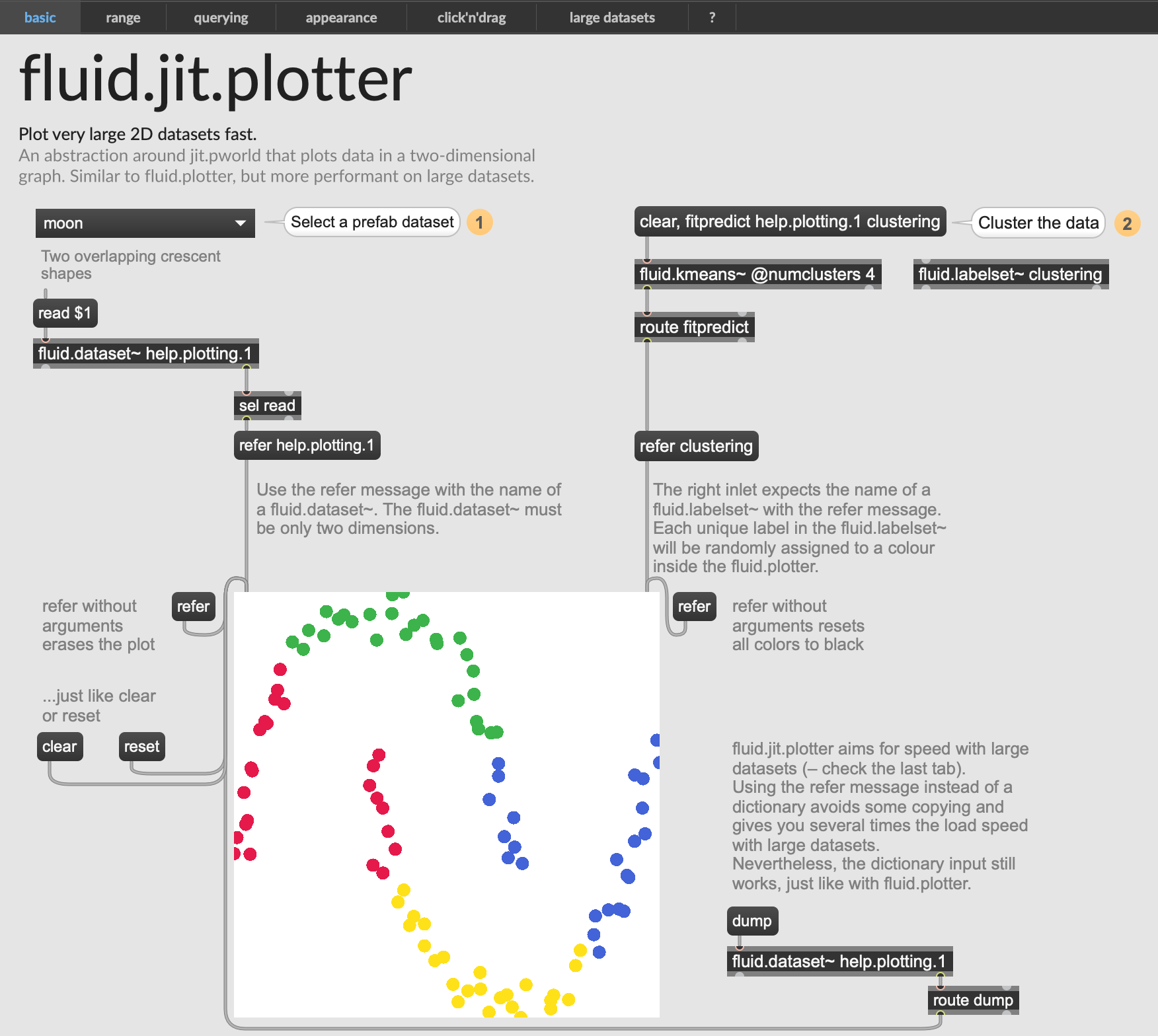
If you are curious about the speed gains you can check out the (new) last tab in the help for fluid.plotter:
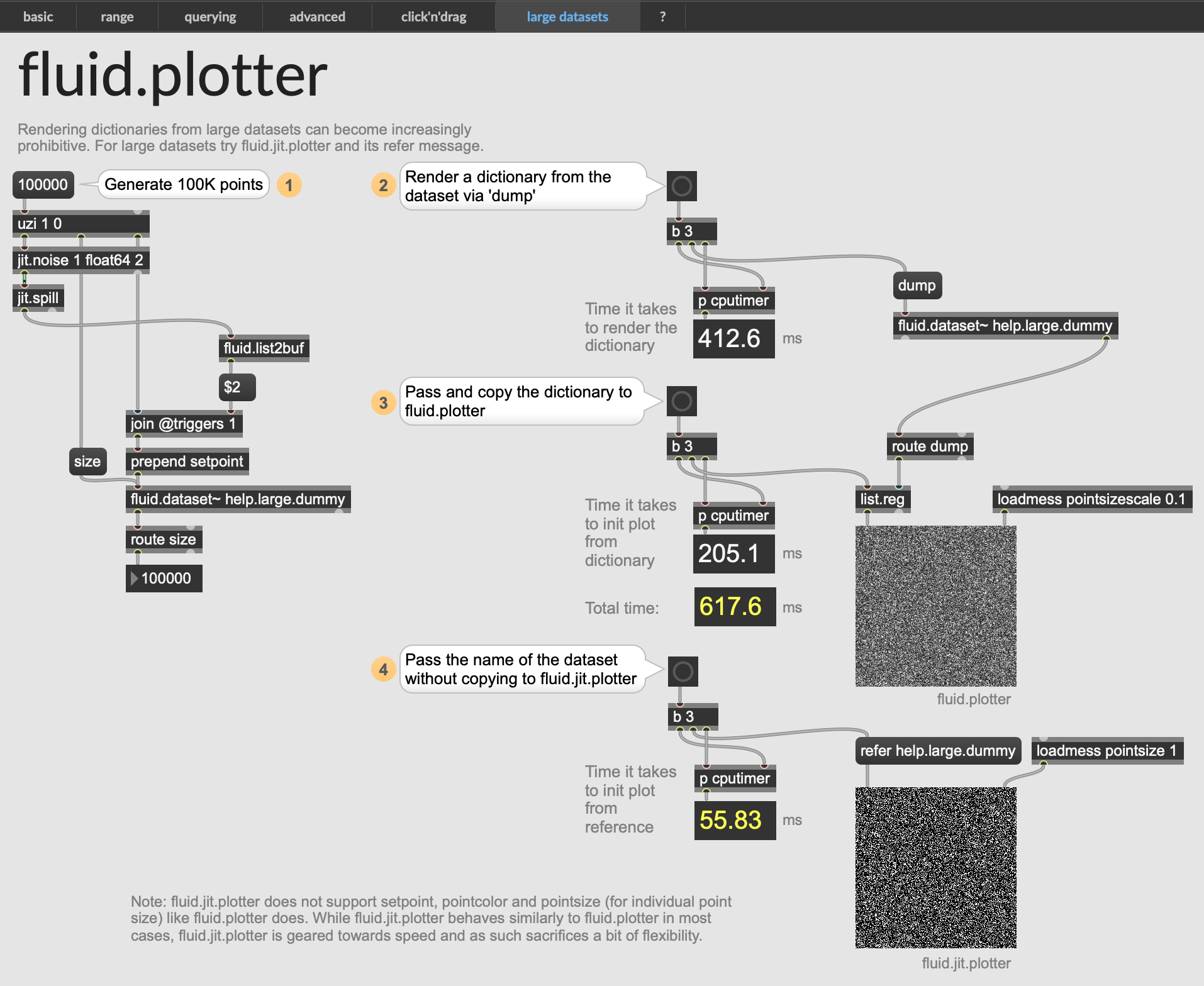
Note that the right-side refer is at the moment (sadly) just an alias for dict and it is similarly slow. So if you dump in the labelset for 1M points, it is gonna hang… But on the left side, refer actually uses reference and avoids the (costly & slow) dictionary rendering.
1 Like
Hehe yeah. I assumed that it would play nice with such a modest corpus size…
The rest of it looks really good actually.
Since this is for distribution (as in, SP-Tools), I’ll wait until this is pushed to the live version before changing things over. Besides that I’m frozen added new features into the current update and this would enable cool/new things anyways…
1 Like
So I don’t know if this is because I’ve just copied over the main files into a standard sp-tools install (rather than downloading the fork above) but all the fluid.jit.plotters are really big and pointy looking:
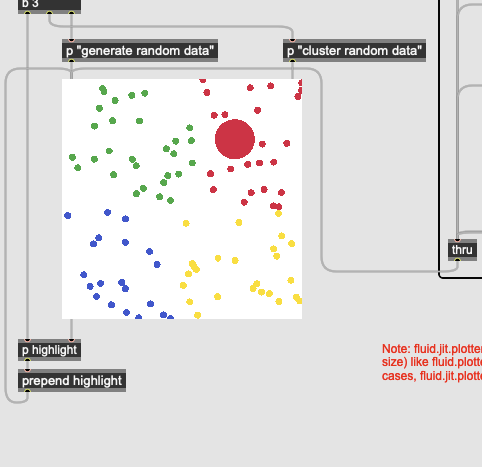
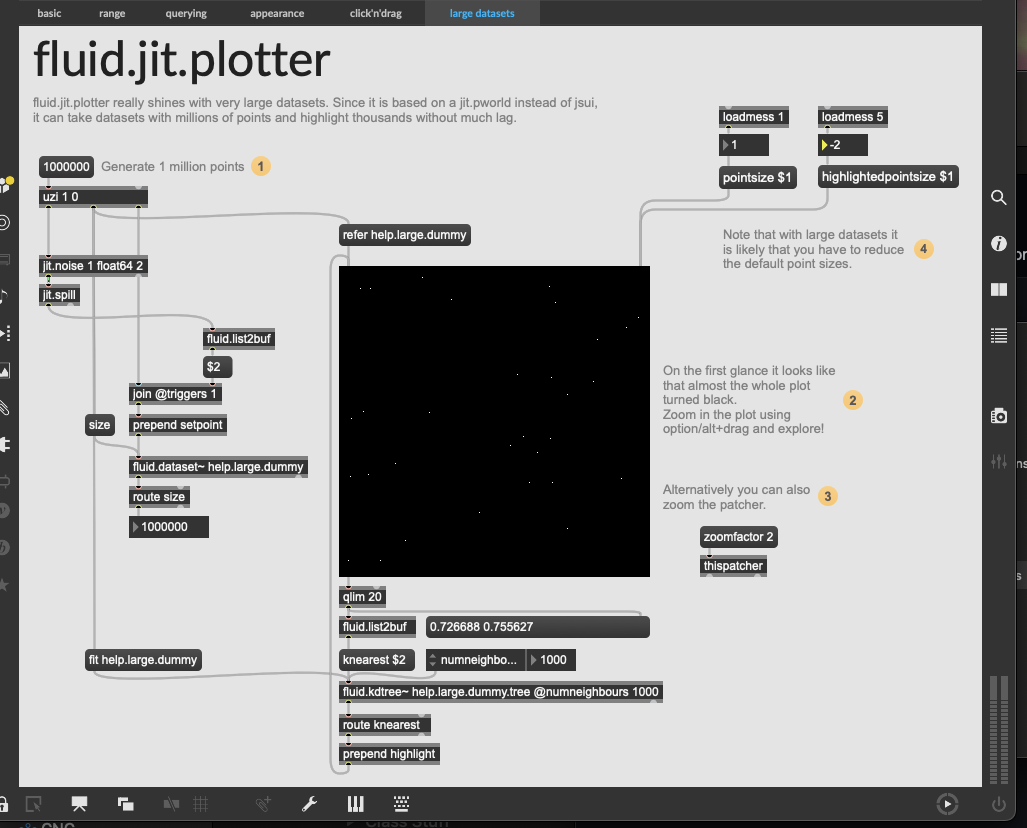
This is just loading the examples as they are in the helpfile.
/////////////////////////////////////////////////////////////////////////////////////////////////////////
Even if shrink the pointsize the dots get fuzzier (as they get smaller):
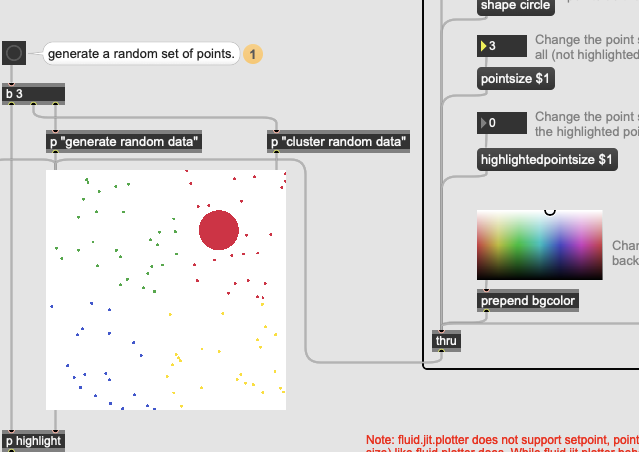
Hmm. Yes, we’ve noticed the “low-poly” points earlier, although it didn’t look so severe. Points rendered by a jit.gl.mesh seem to be lower-res than let’s say instancing a circle with jit.gl.multiple.
You can also verify the weirdness in the jit.gl.mesh help file:
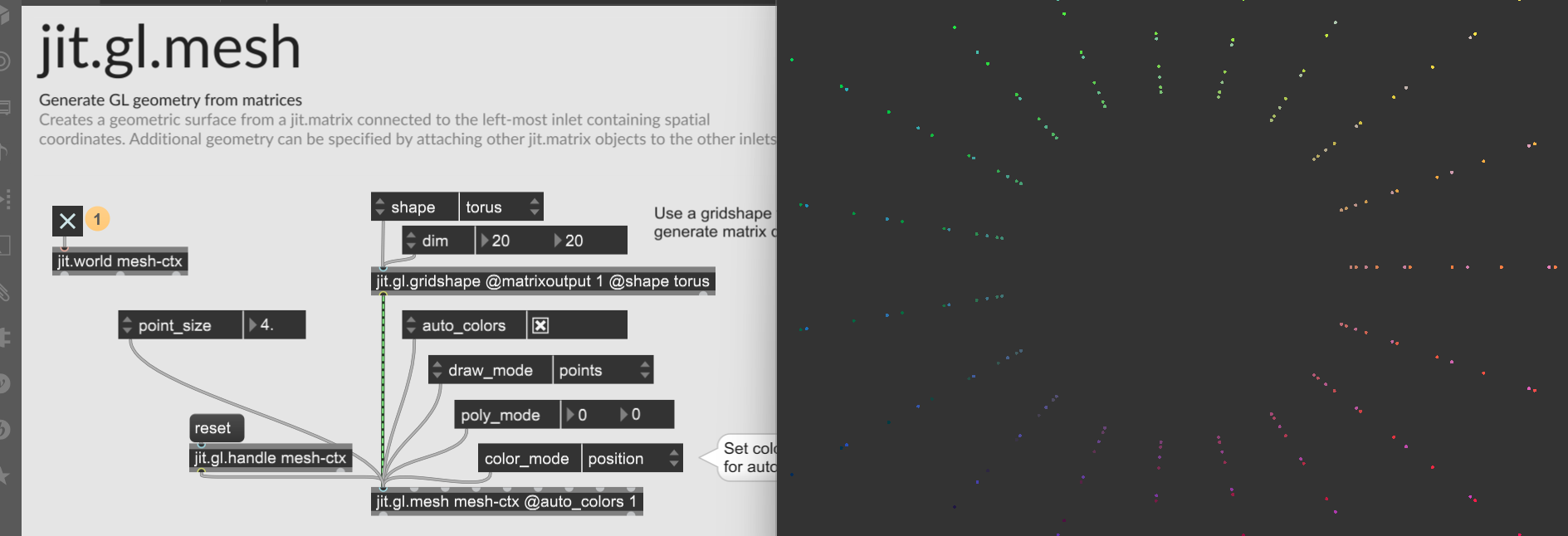
In my experience this has to do something with screen resolution. It’s the least problematic on a 16" retina screen, and a little bit worse on an external 4K monitor.
Yeah I see what you mean.
The fuzziness isn’t great, but it’s more the radically different size which is less desirable.
And indeed, on a 4k desktop monitor here.
Is this (the size part at least) something that can get coded around? Or be made to work on multiple resolutions (i.e. fine on my screen, as well as others if I share a patch).
I started playing with this again to see if I can just deal with the fuzzy points as being able to do large datasets would be fantastic for >5k points.
But it seems like the pointsize and highlightedpointsize are limited to int values, which for the weird “upscaling” that happens at 4k means it’s impossible to have a reasonable pointsize to highlightedpointsize ratio:

(if I set both to 1 in this example, the highlight disappears completely)
Having a poke through the code and it looks like this is a limitation of jit.gl.mesh fullstop, where point_size is limited to integers, and these are the results of point_sizes 1 and 2, respectively…
1 Like
this is a very seriously well spread dataset ![]()
1 Like