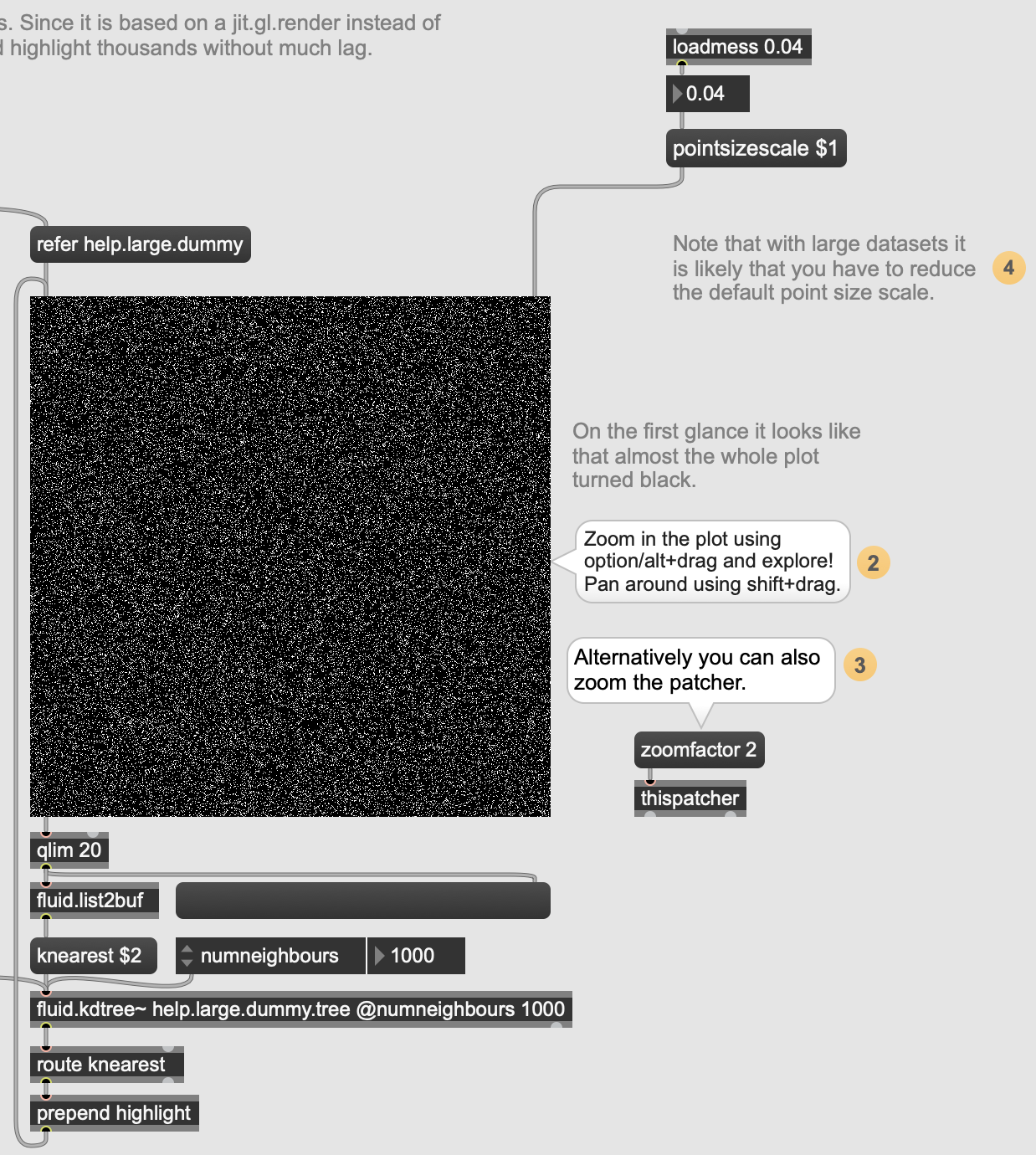
no opinion apart that it won’t be implemented in jit.plotter for a certain time if ever
EDIT: whaaaaaat we already have a shape implemented
was the tale tail… but hey we could change both - parity is important at least within Max. Sc and Pd do not have that… but I’m checking the former here…
oh no, it does. Pd deffo doesn’t - I didn’t implement it.
so for now I’d say stick with one shape message for all points. then make a feature request and let’s consider if we move all of it to a shape-per-point or shape-per-class or ?
I can give that a try! (If/when @jamesbradbury wouldn’t mind)
Sounds like a plan! And for the in-between state while working on the “de-fragmentation” I could implement a check of the args in fluid.jit.plotter so if shape is followed by two args then it means per point, if it is followed by one arg then it means a shape for all points?
one option. another is to check the other features we have per point and global and try to clean the mess be consistent with the carefully designed interface
Well, using a CataRT-style interface for 2d browsing a (huge) corpus sounds really good. The aesthetics leave something to be desired lol…
(I had also forgotten that it’s an integer-based thing so I can’t actually see individual dots regardless)
Have to also work out a more efficient way to reduce a huge dataset down to 2d. This takes a couple minutes of pinwheeling on an M2 mac mini to crunch with these settings (fluid.umap~ @numdimensions 2 @learnrate 0.2 @iterations 150 @mindist 0.5 @numneighbours 10). It’s only 28k points here too…
my favourite garage way of reducing a dataset is to do a cheap umap to 2 d (very few iterations will do) then a grid then skip. it is a cheap downsampler
you could skip the grid part and actually just read with kdtree a ‘grid’ division of the range of the space… you don’t even have to reduce that way but it is dirty !!!
actually pca to 2d (to make the 2d most significant) then either sample the space directly (to sample representatively at the cost of missing the amount of each) or grid then sample (to sample diversity at the cost of overrepresentation)
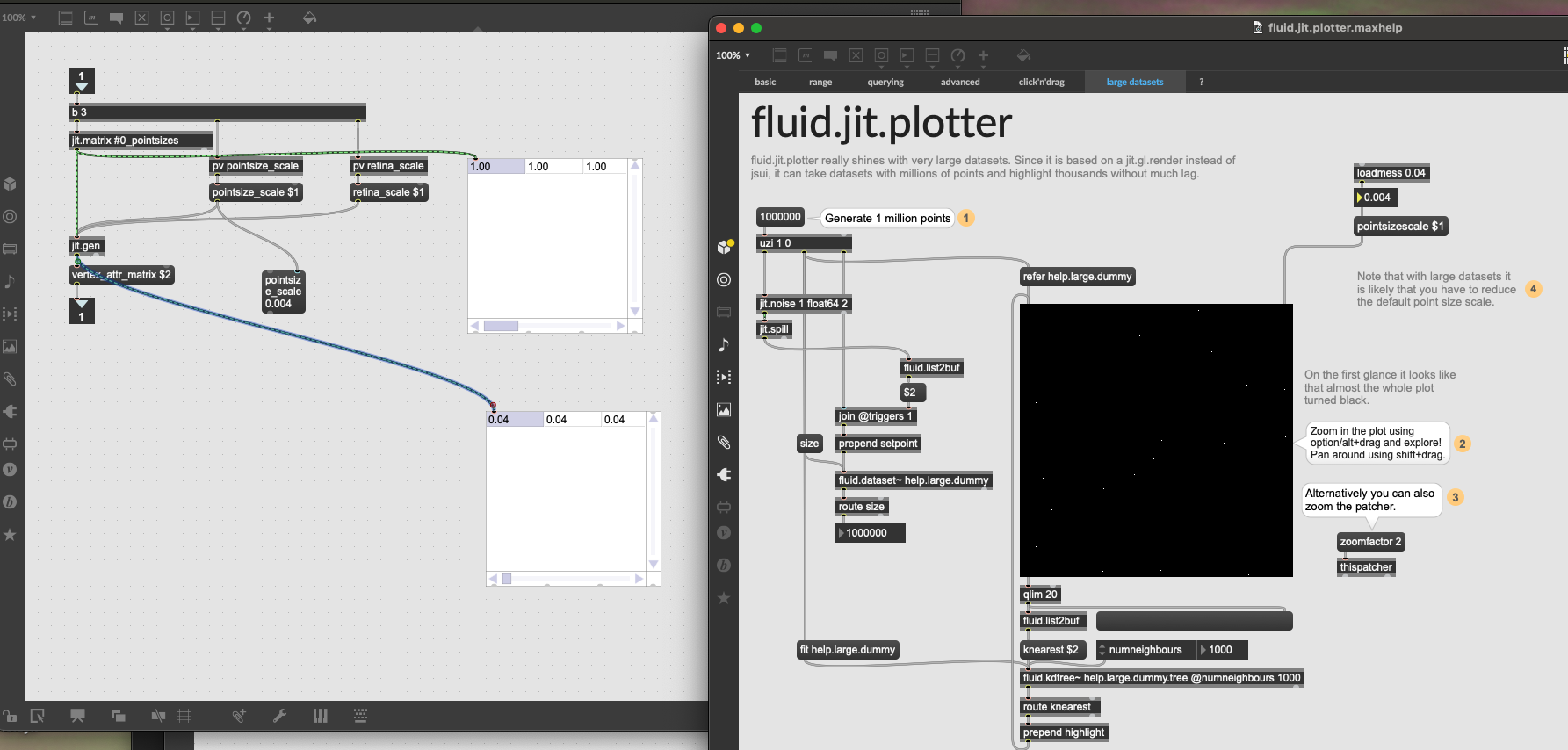
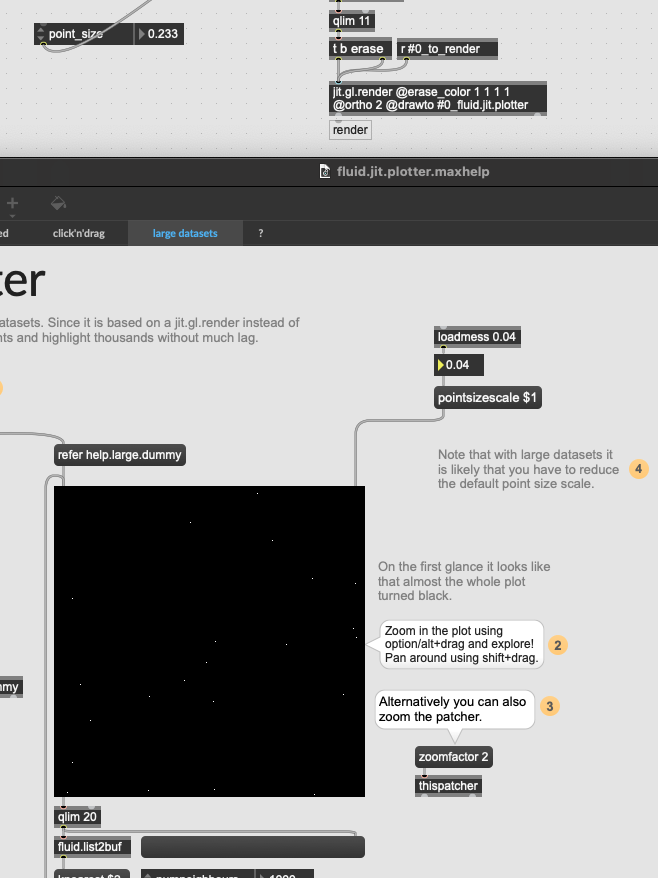
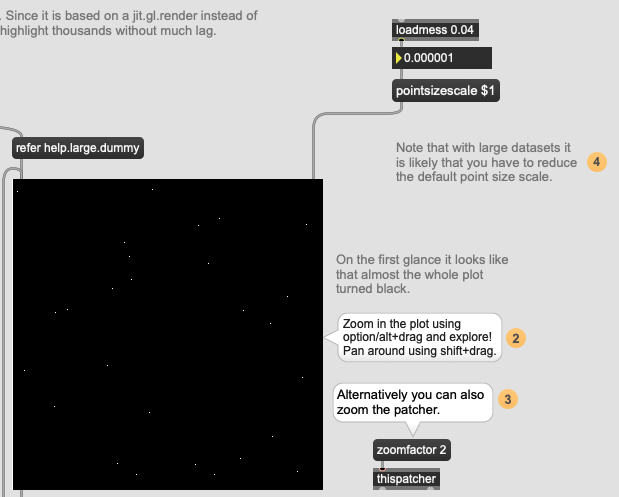
I think this might refer to the display scaling bug. Have you tried lowering the pointsizescale? I will try something now to see if I can “auto-detect” the PPI somehow and scale the points accordingly…
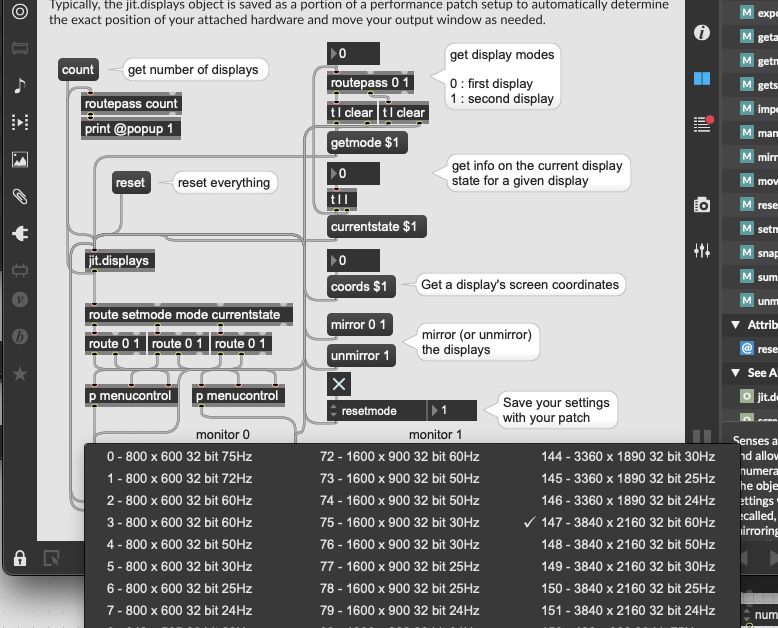
Okay, I think I got something now, will implement it into the PR in a bit. I am more and more sure this is about the retina scaling not communicated properly to the jit.gl.mesh render. I made something now using gestalt + jit.displays + thispatcher that can detect if the patch is on a retina screen or not, and halve the current pointsizescale, which effectively keeps the points the same size as I am dragging the containing window back and forth the MBP screen and the external monitor. It’s a bit ugly hack, but I’ve seen worse.
I used to have much lower iterations, but upped it recently to improve things. Seems like that’s a bad idea with high point counts. I’ll experiment to see how much is passable in this context.
Now that it’s viable loading/mousing so many points, I have to have a think about what makes sense to expose as UI. I guess a grid option is useful, and I’m leaning towards a 3d representation (2d + color) ala the oldschool experiments.
If you start dialing it down eventually you should see it. (How about 0.01 or something?)
Can you check what is the value of pv retina_scale inside the fluid.jit.plotter instance? It should be 0.5 if the screen is not retina, and 1.0 otherwise. I suspect that my hack might not catch the retinaness with the “More Space” display scaling.