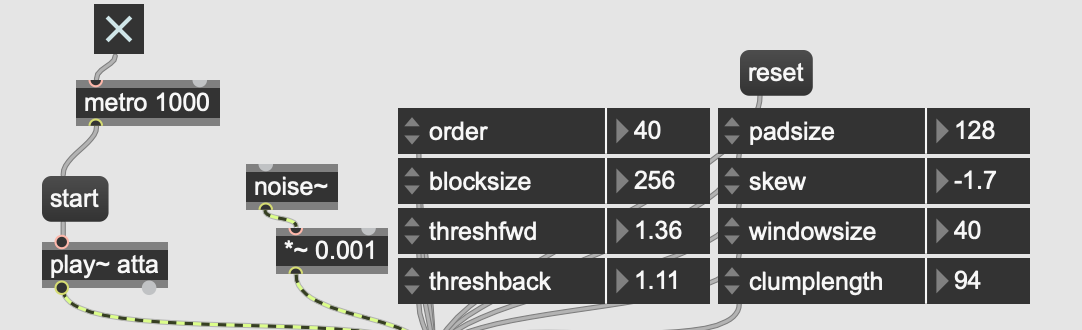
So I’m revisiting the transient replacement idea and part of what I didn’t like about it before was that the transients (in this context) were too big and “mushy” sounding. So I’ve been re-running my batch thing over and over and noticing that a bunch of the files are coming up empty. So testing parameters with the real-time version when I came across this funny business.
Not sure if this is the expected behavior of the algorithm, but feeding it the same audio produces different (random?) results.
I know with some things where you are in the analysis window can vary a bit, but in this case it seems like I get almost random results, including, frustratingly, silence.
In context I was testing this with a percussion sample over and over, but here it’s simplified to a noise burst.
edit:
It appears the buffer-based one doesn’t do this.
I’m afraid I don’t have spectrumdraw~ and friends on this machine, so some of this wasn’t visible to me. Mind you, I don’t think spectra are going to be very meanginful for loooking at tiny snapshots of white noise.
Could you talk me through what you expect to see here? You’re feeding it noise, so I’m not too surprised that you don’t see totally consistent results between runs. They don’t seem totally out there with my (imperfect) understanding of the algorithm, and I don’t see cast iron differences between the buffer and rt versions (caveat: I’m on a different build, so it is possible there’s something screwy in RC1).
My understanding of the algorithm is this (@a.harker remains the authority): it builds a rolling statistical model of what it thinks is going on with the signal in the time domain, and forms a prediction from this model. When the prediction breaks down, it’s probably got a transient. This means that its understanding of what constitutes a transient are actually formed, on the fly, by the statistics of the signal at hand.
The thresholds are expressed as standard deviations, i.e. how much of an outlier the current chunk of signal is, in terms of the measured statistics so far. White noise has very consistent statistics, and is unlikely to throw up much that deviates far from these: ergo, you’ll want lower thresholds than default to get reliable non-silence out of it. Try 1.2 for both of them, for some pleasing dust in real time.
Finally, one difference you will definitely see between buf and RT versions in general is at the start and end of the buffers because these are the start and end of all time for the process, so boundary effects come into play.
The spectrumdraw~ is superfluous to requirements there, it’s more to (further) show how different the results from each pass are.
For my use case I’m trying to extract transients from sharp metal attacks (the same library I used for the performance, since it’s on hand and I’ve analyzed it a bunch of different ways). The attacks aren’t terribly far from white noise (in timbre): metal hit.wav.zip (4.2 KB)
With this file I get different results each time from the algorithm (for the real-time version).
I guess the real-time one will always produce different results for any given input, since the “start” is unknown(?). I would have just expected the same (or very similar) results given identical input.
I dissent! Short though that sound is, I can hear a clear resonance (ergo a perodicity). Are the settings in the patch above the same you are using on these attacks?
Hehe. I guess it’s really CLAAACK, and on the continuum of all possible sounds in the universe, these would definitely be easily confused for one another…
I’ve been having a hard time find suitable settings since the real-time version (easy to test and massage settings) gives me inconsistent/random results. So each time I run a batch process I have to go back and manually check to see what gets rendered. I guess I could just pick files at random and fluid.buf...~ them and check a single buffer at a time, but ideally I could have a tweak with the non .buf version to find my settings, and then render from there.
With the patch I posted, if I run that example through it, it’s a real dice roll what I get out of the real-time version.
In a broader sense, I’m also having a hard time coming to grips with “transients” in the FluCoMa universe. I’m now trying to embrace the “slightly longer than a click, but still shorter than a thump” ballpark of what these click-removal algorithms return, since clicks are short, and short means low latency, and I’m all about that(!!), but even with that, it’s tricky to get something “clean” sounding from the algorithm. I guess I need to massage the @clumplength more since I tend to get mushy smears of clicks, rather than a single CLICK-type thing, which would be more useful with what I’m after.
Yeah, it’s a tricky beast. I think there’s still hope of revisiting this algorithm in the futrue to try and understand its mysteries a bit better, and to complement it with another transient model as well (with a less click-centric notion of transient-ness: this is a declicking algorithm, after all!)
With that file just looping with a small gap, I found that I needed to feed in some very soft noise to help calm things down (provide some statistical continuity). It’s still hard to get it to settle, because the curves it thresholds on are very noisy (in the algoirhtm), and there can be a miniscule sweet spot. In general, if it’s being unpredictable the thresholds might be too high or too far apart. It’s possible to get silence if both are too low or too high.
Doesn’t solve your batch problem though. In a way, you’d kind of like to train the model across the batch and use that as a basis for detection (disclaimer: I might be talking out of my behind here).
For batch processing, if it’s truly offline, you have the luxury of being able to use some larger blocksizes and orders, which might help: if those clanks are all around 2000 samples (which is too big a blocksize for RT), then this might be a useful starting point for the blocksize. (use blocking 0!)
Finally, I’m reminded of the compressing-off-tape trick, where if you play the tape backwards into the compressor, you can get smoother feeling behaviour, because your attacks have become swells. I wonder how the behaviour of this thing would be affected…
That was my initial thinking, and @a.harker suggested some nice and chunky settings back at the 3rd plenary when I was first messing around with this idea. With those (particular) settings I got the “long and mushy” transients where there’d be a cluster of clicks, a gap, then some more clicks (on a small time scale, but still kind of KRRSH rather than CLICK).
I guess where I’m going with this, it doesn’t so much matter what the extracted transient is, since it will eventually get stitched together into a franken-sound. Sizing variabilities complicate that, but one problem at a time I suppose.
Definitely like the sound of that. As I’ve mentioned (probably oodles of times!) I think of a transient as something longer and identifiable, I guess closer to an “attack” or “hit”, but there’s definitely some usefulness to a short transient (as it’s presently pseudo-defined). I just haven’t gotten somewhere with the algorithm that satisfies either use(ful case).
Come to think of it, that might be part of what the algorithm does. I think the threshBack is from a backward pass over the analysis window, so you see slightly different staistics (I guess with the expectation that the transient moment will represent less of a deviation than on the forward pass, so it would be lower). IIRC, it’s another schmitt trigger thing, where the forward threshold has to be exeeded from below and the backward crossed from above, to mark out a complete transient region. I need to look at the code again. But should get back to what I’m meant to be doing (washing up and drinking campari)
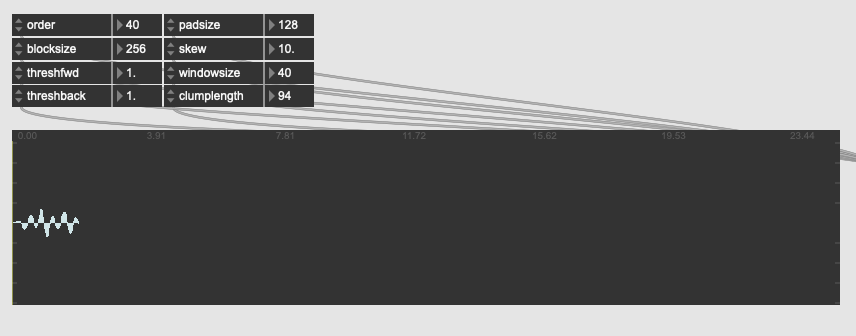
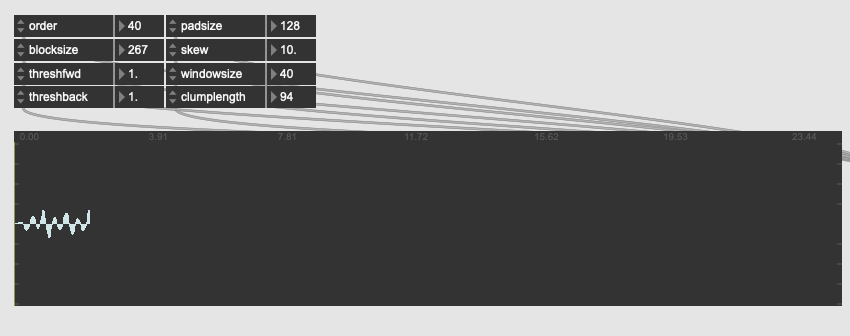
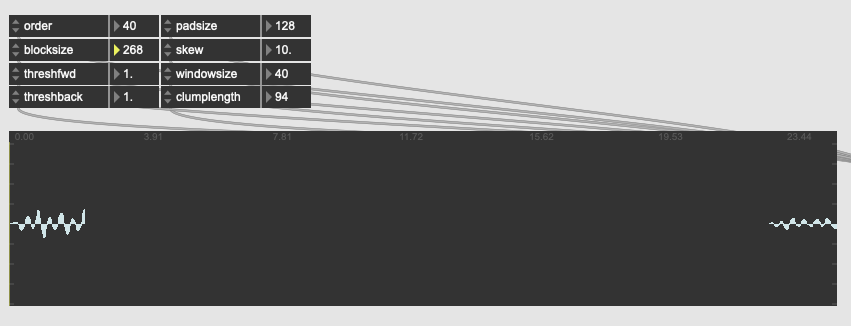
…and the main transient disappears, replaced with the ending peekaboo bit.
I get this a lot, where one sample in either direction for the params completely nukes the output in a way that, to me at least, doesn’t seem to make sense with what the params are meant to be doing.
I’ve also tried loads of params and combinations to see what determines the “space” between the two clumps that show up, as they are persistent among a bunch of tests. I can get the ending one to move forward by a sample or two and then the front bit disappears.
In practice, I can just tune the settings so I get a starting click and then manually trim all the files after that, but seems like a clunky workaround for someone that I would presume is doable via parameter tweaking.
Yes, that’s frustrating. My guess is that it’s down to how very noisy the internal curves are (I don’t yet know why they are so noisy). My experience has been that extreme values of skew make this problem much worse: was there a particular reason for cranking it in this case? What happens with a more moderate value, is it just as unpredictable?
It all feels unpredictable in every direction. The cranked skew seemed to give me a nice chunky thing at the start, so I left it there and started massaging the rest.
It’s just tricky when there appears to be no (or little) correlation between parameters and results. (some (much?) of that is on me though)
What would be good here is to have a sample (not noise) with a specific expectation so we can detangle what is expectation issues, and algorithm ones. I’m not saying that it is a combination of both, but this is a hard cookie to break indeed, so the more we agree in sound/behaviour first, the more I can go fight that fight with the algo for both of us, if that makes sense?
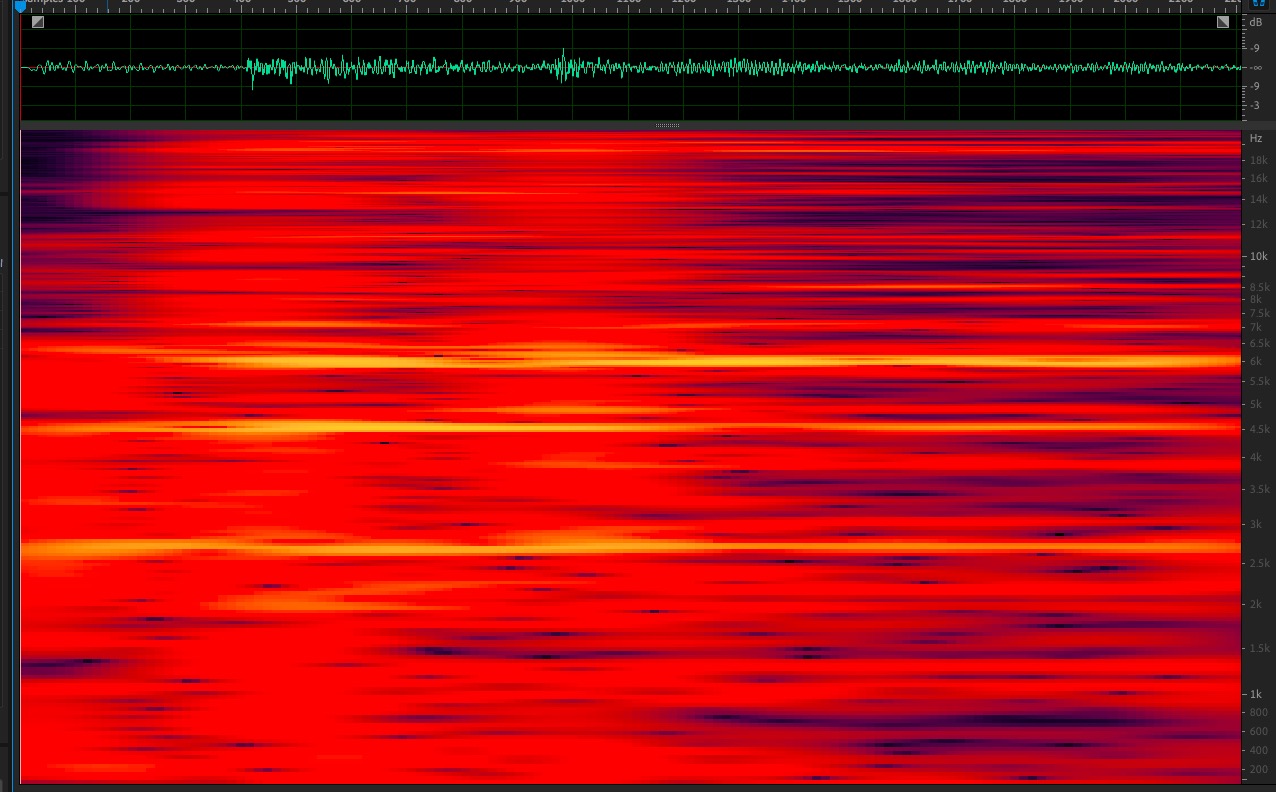
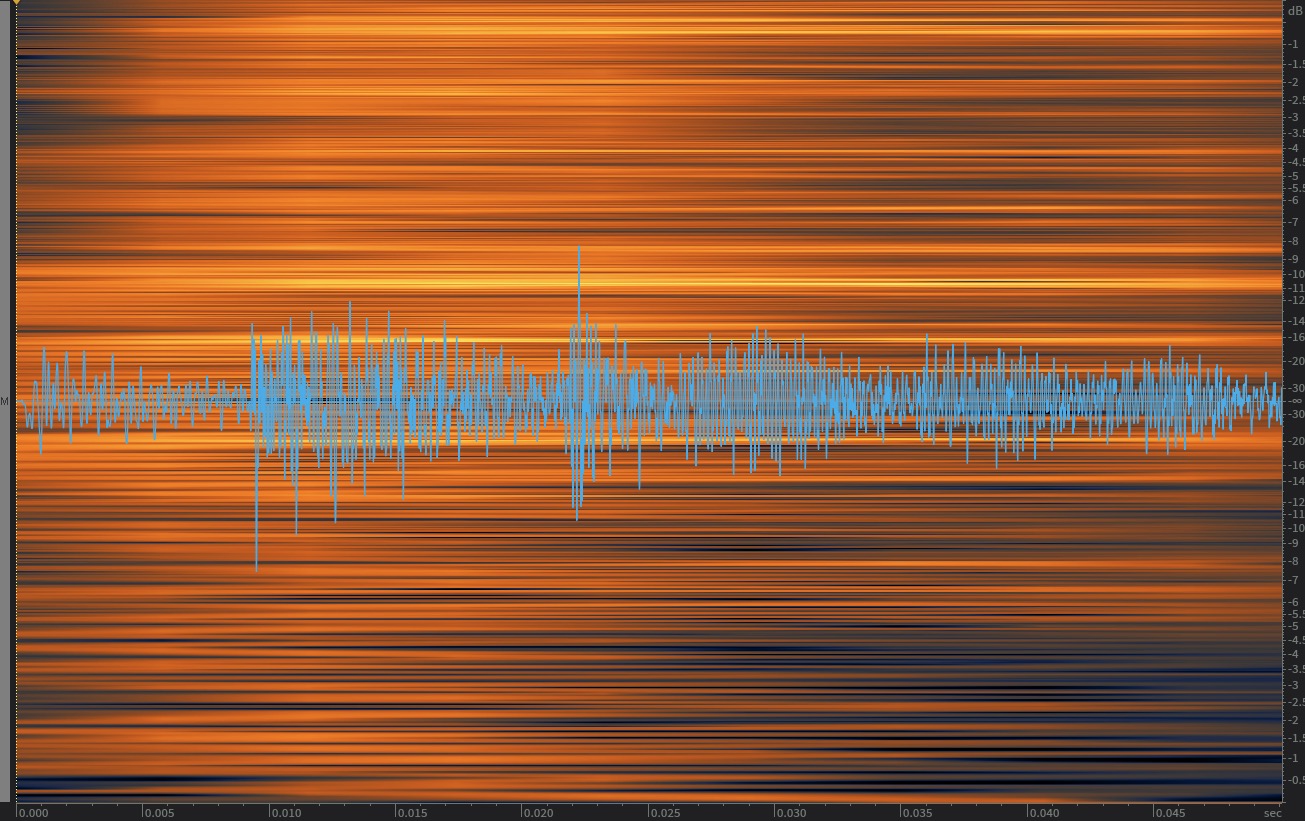
All of the screenshots were run on a sample, rather than noise. The noise was just for the initial demo was they were “close” sounding.
In terms of expectation. I’m trying to get a short bit at the start, that doesn’t have (many) gaps in it, and specifically doesn’t have only a transient at the very end with nothing before it (this happens waaay more than I would expect).
Seriously, when I listen to the source, I hear a flam. When I put about any setting like the default, I get that flam. So here I’m not certain it is a bug, or just wrong settings. Or the wrong algo for what you are looking for.
For instance, this is how I use it: I get with your loaded values a flam of 3 short things. I want less of them, so I try a larger block size, which gives me a flavour. I raise the threshold forward, with gives me another flavour. Changing the order gives me yet another flavour. I tend to keep thresh backwards quite low. This is all from experience and reading the manual. It is quite abstract but order helps with low-end signal, blocksize with the transient size.
This algo is there to find clicks. Misfits in signal. To quote from the reference file:
The whole process is based on the assumption that a transient is an element that is deviating from the surrounding material, as sort of click or anomaly. The algorithm then estimates what should have happened if the signal had followed its normal path, and resynthesises this estimate, removing the anomaly which is considered as the transient.
If you feed it very short noisy signal like pink burst, you’ll get nothing sensible. The ‘metal hit’ as some pitchness as the attached spectrograms will show, so that should be captured by the algo as being ‘normal’ and that is why I get clicks at the 3 bumps…
so back at you: what are you expecting? Have you tried HPSS on this with something very biased towards sharp, noisy elements in the percussive definition (fft, filter sizes) because here I cannot reproduce a behaviour that I don’t understand?
So yeah, this sample (and many others in the library (and most sounds of things being hit by other things)) have these micro-flams at the start.
When I first ran a big batch setup after the last plenary with suggested settings from @a.harker, it gave me very “wide” transients. As in, it could catch all of these little flams, and have gaps of silence between them. It would also often swallow the initial one (which I thought was my imperfect editing of the starts of the files) so I built a thing that would remove the zero padding from the start of the file after the batch process was done.
To my ears, this extraction of transients from multiple “sections” sounds really bad. Without the rest of the material that contextualizes it as a flammy sound, it ends up sounding mushy, like a smeared transient.
Ideally what I’d want to be able to do is have to tune the settings for the initial transient it meets, and then have some combination of settings (or lockout-type thing) that ignores stuff for a while. I’ve run the batch process on varying cropped/faded sections of files and would still get these silent returns, or more often, silent starts with the second “transient” being caught instead of the first.
So more concretely, with a file like this, I would want to have the biggest possible initial transient extracted, and then nothing else for the rest of the duration of the (short) file.
I’ve not tried running it through HPSS stuff, as my thinking for this was to create a database of “just transients” which would hopefully layer up nicely with subsequent bits, in a more synthetic way (perhaps the second chunk of playback would have had its transient extracted). I would think that this would be an ideal use case for this algorithm.