Now that I’ve got an easy to use (Max) native visualizer, I’ve been thinking about this idea that has come up a few times throughout the various plenaries and weekly chats.
The idea of taking a dimensionally reduced representation and then transforming it in one way or another.
Some of this is easier to explain with a video, so here’s a quick video explaining what I mean:
Some specific questions and use cases I’m talking about in the video are:
Taking a 2D representation and remapping via changing/skewing the orientation. Some of this might be simple rotation stuff, but in the example I show in the video it’s not so straight forward. Perhaps this is a problem for a regressor or something? I’ve not really done this “point to point” training before.
Having the 2D representation remapped onto a more perceptually aligned orientation (e.g. loudness/centroid on the axes). I don’t know if this is the same as simply mapping the original points according to those descriptors, but I don’t think it is as new relationships are formed via the dimensionality reduction. This would essentially be an “automatic” version of what I suggest in #1 above.
Taking any of these 2D projections and distributing them evenly across the available space. I know @tedmoore has mentioned specific algorithms towards that end, it’s just a matter of what is possible to implement within Max (or with minimal friction from within Max). Ideally natively would be great since you can then transform incoming points in a similar way, but I envision this use case being more about using completely unrelated descriptors/parameters to navigate that space (MIDI controller, or X/Y grid like @tremblap and @spluta are so fond of).
Lastly, this starts getting a bit more complicated, but a way to visually/graphically transform a 2D representation (ala Photoshop, stretching corners, bending/warping/etc…) such that you can take other 2D representations and place/stretch/map them onto another space. This is something that @b.hackbarth and @jamesbradbury have talked about a bit, and I can see it being super powerful, particularly when you are combining multiple corpora and/or sections/subsections of multiple corpora. @tremblap mentioned doing something like this via jitter, where you apply a visual transformation, and then just run each dataset through that function, but this starts getting a bit complicated (obviously).
What does changing the mapping for you do though? If you want your space to be organised in X way, why not just serve UMAP with that data in the first place? I think that you could milk more by massaging your input data, selecting the right statistics and configuring the right UMAP parameters to get a smooshiness of space that you want.
Another approach might be to get a neural network to learn a mapping between whats there (UMAP) and what you want (RodMap).
Select point
Say where you want it
Map figures out how input points, descriptors and output points are related
Not entirely sure, but on a fundamental level it would be to then navigate this space in a manner that makes sense with a different set of inputs/controls. So perhaps using an X/Y grid/controller (trackpad, gamepad) to navigate the space, or using other (semi)related descriptors to navigate the space in a manner that is perhaps not correlated to the descriptors (louder sounds are higher on chart, quieter sounds lower, even if the points don’t share those characteristics).
Where I’m much less sure how this would work would be a way to map multiple corpora to that space.
It doesn’t, but let’s say this represents the range of sounds I can make with prepared snare.
It would be great to take an arbitrary corpora and map/scale it onto that lump in the bottom left there. Then another one from that thin line shooting off to the right, etc…
In this example the orientation doesn’t really matter so much, other than being points in space that you will then map other points in space on to.
The reorientation/scaling/grid-ing is more about navigating this space in a more intuitive/clearer/whatever manner. (i.e. this is great for seeing the relationship between the sounds, not for playing/navigating them).
In looking at my last post, it would be quite useful to carve off parts of a fluid.dataset~ using an interface like this too. Like the lasso tool in Photoshop at stuff.
It wouldn’t solve many of the transformation problems, but it could perhaps let you treat each subsection of the corpora independently, rather than trying to manage everything in a single plot.
This is where clustering is useful. You decide on a strategy and treat each cluster differently. I think you really need to try the Hungarian Algorithm as @tedmoore has demonstrated its usefulness for postprocessing the space into something more interesting.
Ultimately, I don’t see the point in using dimension reduction to get a space that is meaningful for you, otherwise why wouldnt you just use a descriptor that makes sense for how you want to navigate it? If the point of the dimension reduction is to figure out a perceptual space then, at some point you have to accept what it throws you. In your examples you effectively want to invert the mapping it is providing to you which seems drastic. Instead probably what you want is something that just has a normal spatial distribution while keeping the sense that each ‘group’ is relatively close perceptually.
That’s not really possible with MFCCs, or std of derivs etc…, Once you get past “loudness” and “pitch” it becomes meaningless numbers, so the reduction is more about making some sense of that. Which is seems to well. Unfortunately the layout/orientation/etc… aren’t so useful as a mappable space (X/Y etc…).
Perhaps what I’m getting at here is more about an additional “mapping” projection that is about how you traverse the space created by the dimensionality reduction.
As I said, I’m not entirely sure here, but I know that every time I’ve seen a plot like this, I find it interesting for seeing the patterns, but have 0 interest in playing with it.
Have you thought about using a UMAP reduction for only the x axis, then using a more perceptually transparent descriptor, like amplitude, for the y axis? Self organizing maps also might be interesting to try here.
I’ve thought a little bit about the graphical transformation of XY points in the abstract (as you say, a la photoshop). Trying to implement something like this in jitter would melt my brain, but if you come up with something I’d love to have peak.
I’ll give that a spin today or tomorrow. I’ll also try 2D umap + [perceptualDescriptor] to see how it all folds together.
SOMs is something that @a.harker suggested, and has used, a while back. I’ll have an investigation to see.
Full Photoshop-esque transformations (stretch/skewing) will also melt my brain, but doing some more simple min/max-ing to overlap areas may be simpler/easier.
another approach is SOM then UMAP like @groma proposed in his now classic Fluid Corpus Map paper. You use the quantization of SOM to make sub-dataset (or clusters) and then you
In our objects you could have fun with orders of things.
(optional UMAP distortion of space)
then clustering with kmeans
rank clusters by their centroids in 2-D via PCA of the centroids
then taking each cluster and UMAP-ing them
you get a kind of strange frankenstein mapping
if you get 9 clusters, this is manageable and you can do step 2 manually (put them in the 3 by 3 grid where you want)
It would be great to be able to massage datasets around based on the clustering. Either breaking them into new datasets (like @weefuzzy’s example in the other thread, which would then facilitate the separate processing strands, or adding the clusters as a column which can then be matched against (though being able to apply filters to that would be good, but that’s a separate discussion).
So when you say doing step 2 “manually”, do you mean by manually setting the min/max output points of the datasets so they then exist as a subset within a larger space? Not sure I 100% follow what it would mean to do that process.
Literally just to listen to them, and then decide where you want to put them in a 2 d grid. you have class IDs and you can make subdataset with them, and then run a UMAP on these subdatasets.
What I meant was in terms of the code. Like, how do you take multiple datasets (or clusters) into a single 2d/3d space. Like placing them where you want them etc…
Ah right. So they would be independent bodies, and you would just have the analysis chain fork down the path (rather than mapping them all onto the same “space”). So if a 3d plot represented “all the possible sounds” I can make with my snare, and I wanted to place each cluster/dataset/corpus onto that space itself.
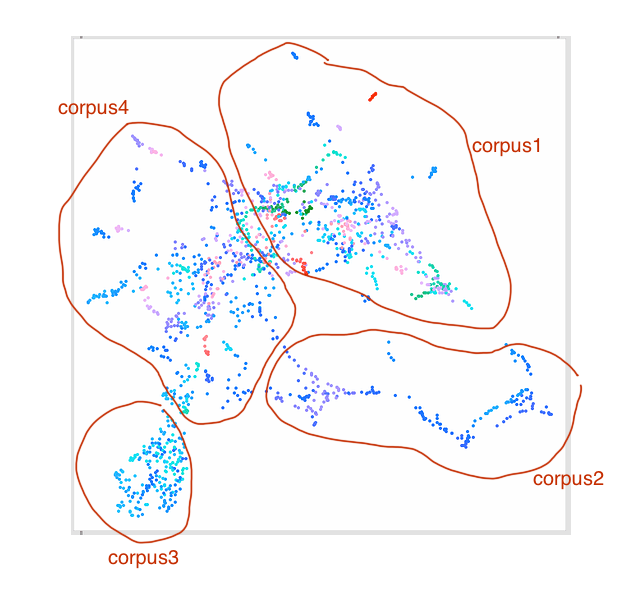
So presuming this plot was my “snare space” and I have 4 clusters/datasets and want to do this:
This is a bit more complicated as each space isn’t a square/rectangle, and could potentially have some funky shapes in the middle.
I guess this kind of thinking or approach could play very nicely with what @tutschku suggested at the last plenary with regards to “drawing a lasso around an area in a dataset”, except instead of deleting the points (I think his desire/point) you could select those and “copy/paste” them into a separate dataset (or cluster).
")