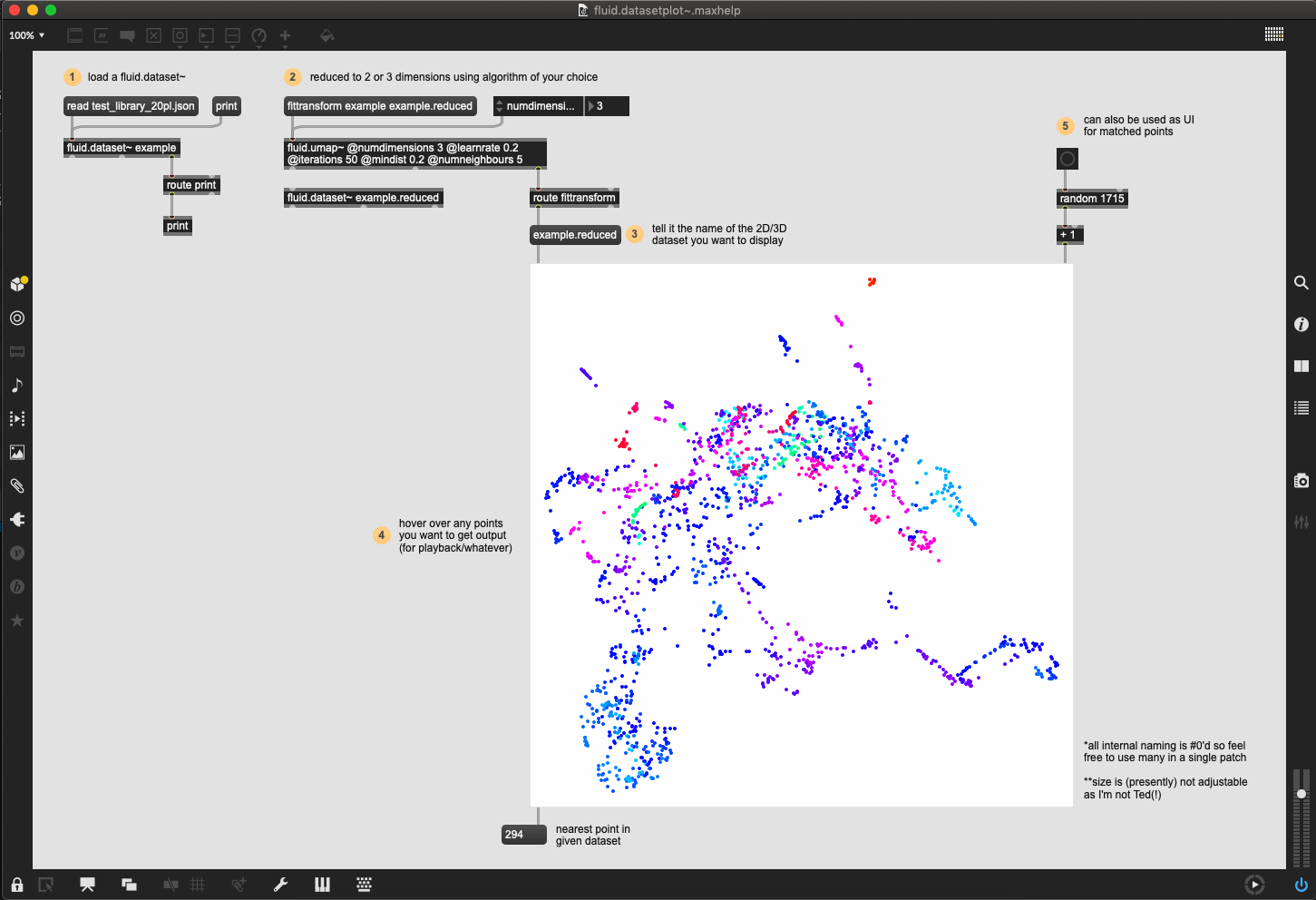
This takes a fluid.dataset~ name as its input, and handles the rest internally (using #0’d names/variables for easy reuse). The presumption is that you’ll create a 2D (or 3D) fluid.dataset~ that you will feed into it (via fluid.pca~ or fluid.umap~ etc…), but you can also use fluid.datasetquery~ to display single dimensions from a larger fluid.dataset~ (ala @tedmoore’s slick SC display thing). Unfortunately since the native fluid.dataset~ data model doesn’t include column labels/symbols, it would take a parallel process/data storage/management solution to pull that off that drop-down-descriptor thing.
I also added some extra features so you can hover with a mouse and it will tell you the nearest match (as well as giving you a little “puck” UI) which you can use to play back samples as well as adding an extra input so you can use it as a playback UI display too.
The code is tidy and commented, so it should be pleasant enough to look at.
I didn’t intend for it to be massively comprehensive, more an adequately functional and generalizable solution for visualizing stuff in Max. That being said, let me know if there are things you’d want it to be able to do that it presently doesn’t.
Oh, one thing I’m not sure about is how to best map to an RGB space for the 3rd dimension. Presently I’m using swatch to convert a single value (via HSL) to an RGB array, but the problem with that is that 0 and 255 both equal red, so it wraps back around on itself. I initially tried scaling it so 0 = red and 255 = blue, but then the contents seemed really smooshed and not very differentiated. That could just be down to this particular dataset, but I imagine there’s a “standard” way to map via color for stuff like this.
This is soooooo cool! A few ideas pop right away and questions, nothing you patch won’t do in 2 clicks (messing about with UMAP 2 powerful main parameters for instance)
I wonder
if it took you long
what were the problems encountered (apart from 1D colour space, more below)
how did you analyse this dataset (the neighbours are quite credible)
As for colour space, this is a known problem but since you are reducing dimensions… you could try reducing to 5 dims and map 2 to xy and 3 to colour… this is crazy but fun… in PCA land you could do that since the order of dimensions is less and less significant. I’m sure @weefuzzy and @groma will know something cleverer.
Pretty bells! Yeah I ran into the same color problem. My hacky solution was to just scale the color hue value from 0 to 0.8 (rather than 0 to 1) this avoided “reaching” 1 where red would reappear. I’m not sure how I decided on 0.8, probably just looked at a color wheel or something. One thing that might be cool, per @tremblap 's suggestion, is to go into Python and export some matplotlib color maps as look up tables to use.
This would be a good move since, as the webpage linked by @tremblap states, “Researchers have found that the human brain perceives changes in the lightness parameter as changes in the data much better than, for example, changes in hue.” And some of the color maps in matplotlib are designed to account for this.
Yeah totally. The idea is to more-or-less isolate the visualizer part, and the rest can be handled elsewhere. So this can be a loudness/pitch map display as well, etc…
The whole thing took the better part of the day (somewhat on and off).
I was able to get something that displayed 2D points hacked together from the fluid.pca~ helpfile, but it was suuuuper slow (for >100 points). After figuring out fluid.buf2list was the speed bottleneck, I used the dump-based approach like the fluid.umap~ helpfile uses.
So that much wasn’t too bad, an hour or two of solid work (spread out in my case). It still had all hardcoded names and such, so generalizing it was a faff.
The color thing wasn’t massively difficult once I realized/remembered I can just use swatch to do the HSL function for me.
What took the longest was working out an overlay for the playback display (mainly cuz I suck at jitter).
Tidying obviously takes a while too, particularly if I’m going to Rod it up (no color coding here though).
I answer some of this in the previous step, but the logic/headspace of managing a unique-name-per-step is just a general PITA as everything breaks with a typo, and each fluid.dataset~ needs extra code around it to display the contents to figure out where things broke. So in general the “buffer problem” added loads of friction.
Other than that it wasn’t too bad really. Once I added the playback puck I realized I needed to scale the space back a bit as some points were being plotted weirdly (which I didn’t notice while just using normal hover), so I guess that’s a scaled data → jit.pwindow~ thing or something.
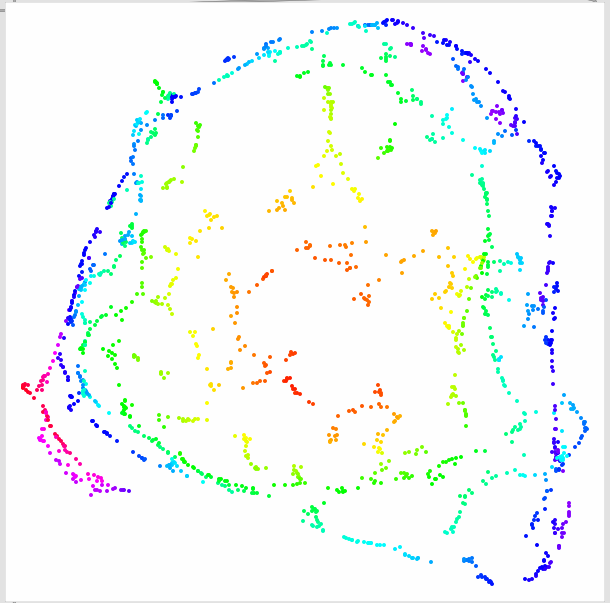
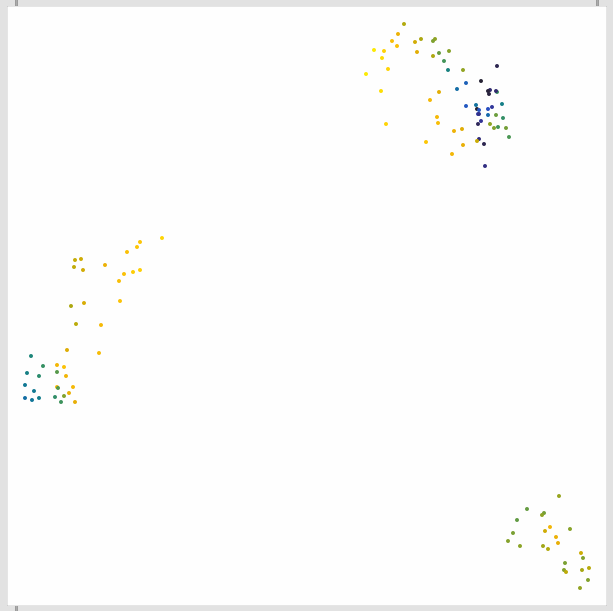
This is using my “best” recipe from the time travel thread, which gave me the most differentiation with the lowest number of natural dimensions. In this case 20MFCCs (minus MFCC0), loudness, and pitch, with just the mean of everything.
I am excited about the prospect of being able to hone down to a more meaningful set of descriptors/statistics via the PCA method @tremblap mentioned in the last FluCoMa chat. At this point I’m a bit tired of manually testing different permutations manually (as in the other thread) mainly because the patch has to change pretty drastically for each version of that.
I did think of including point size as well, but I think that 3D is probably already pushing it (for the purposes of this kind of browsing/inspecting).
This is very cool. And I’m in agreement with @tedmoore that it would be super handy to see this as a lookup table.
It’s interesting how different the perceptually differentiated ones are from what one would think. I guess it makes sense that we wouldn’t necessarily perceive things in a uniform(ish) way.
Having a quick look through that page I’m not entirely sure how one goes about doing that however. (Python is not my strong suit)
Oh, I forgot to add that I didn’t normalize anything before going into fluid.umap~. So the MFCCs are in whatever weird range they are, the loudness is in dB and pitch is in MIDI.
So the data looks something like this (the rows are in random order):
I will have some more detailed questions about the best way to approach this in another thread, as part of me building this was to make an IQR-based rescaler, so I wanted to be able to visualize what is happening throughout the process.
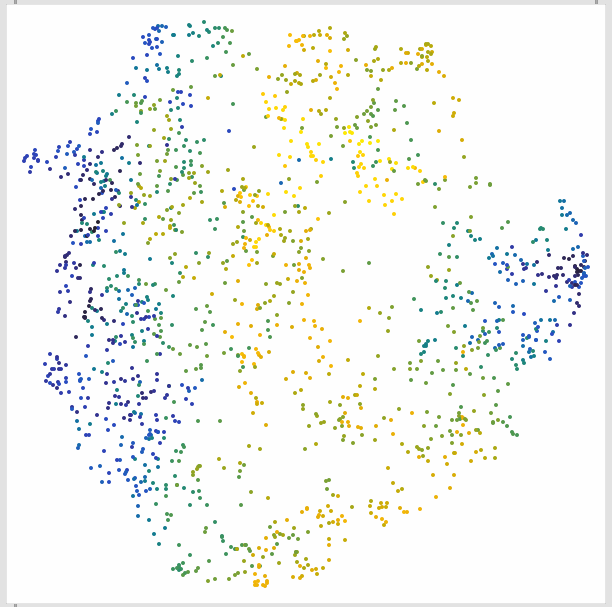
On that note, and out of curiosity I plotted some variations of this dataset.
Here is the 21D space (20MFCCs (19), loudness, pitch) mapped via 3D umap (what’s displayed above essentially):
Now this is where the fun will be. To shring the spectral space and bounce it against pitch and loudness for instance, before the redux, is my exploration of the last months (when I have time)
I’ll check if any of these can be computed with free code, that could be fun if it was legal to share it.
that will skew the stuff, since the range tend to decrease with the coefficients. Again, loads of fun to compare the various scaling possible… and more to come
Totally. Hopefully being able to visualize with something like that will make that exploration easier.
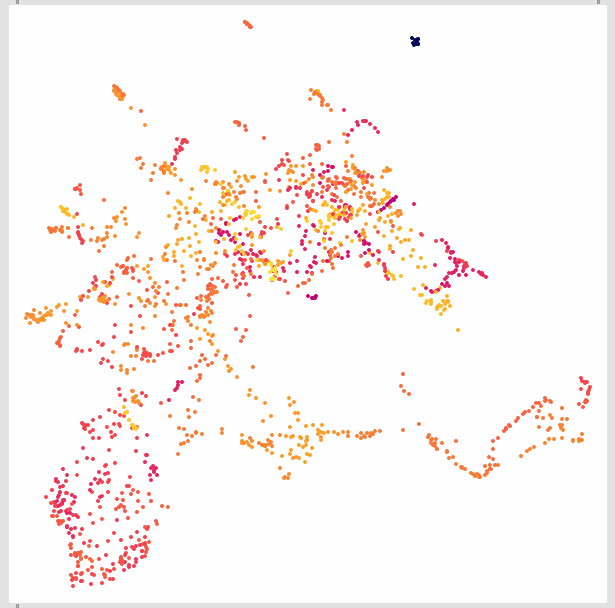
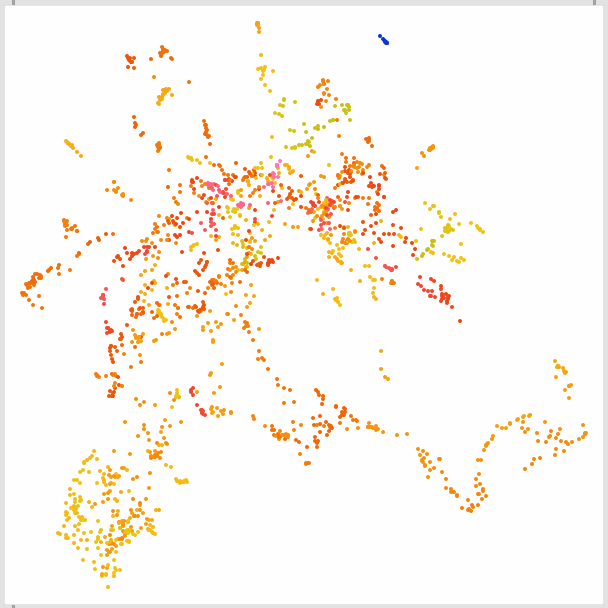
After my last post I tested some other corpora and the results aren’t as immediately good. For example, pitch isn’t a useful descriptor when it comes to tiny aluminium foil crinkles as it turns out. And in this raw approach, the MFCCs severely outnumber all the other desriptors too.
Will see how this develops, but I want to say that from my testing before, having a dimensionality reduction step in a realtime process slowed things down enough for me to want to just curate less, but more meaningful “raw” descriptors/stats rather than having a dimensionality reduction step in the analysis/querying workflow.
I’ve not tested this stuff in a while, but that’s where things were at least time I tried.
No clue how it works, but presumably it can just generated a LUT which you can use anywhere. In my patch I think there are only 255 color “steps” available anyways, so a 255 entry LUT would be fairly tiny/portable. I just have no clue how this would happen in Python/library land.
Indeed. I need some fresh brainspace to consider my questions around this, but basically how to best take a dataset, incoming analysis, and selectively scale them (or not), perhaps, and eventually, including the multi-corpora scaling thing, where you can overlay many corpora onto a single “input” space.
Ok, after installing matplotlib and trying a wee bit (with a bit of help from @jamesbradbury) I did some more googling and just found LUTs in .csv format here:
Ok, just went down a mini color rabbit hole playing with the options.
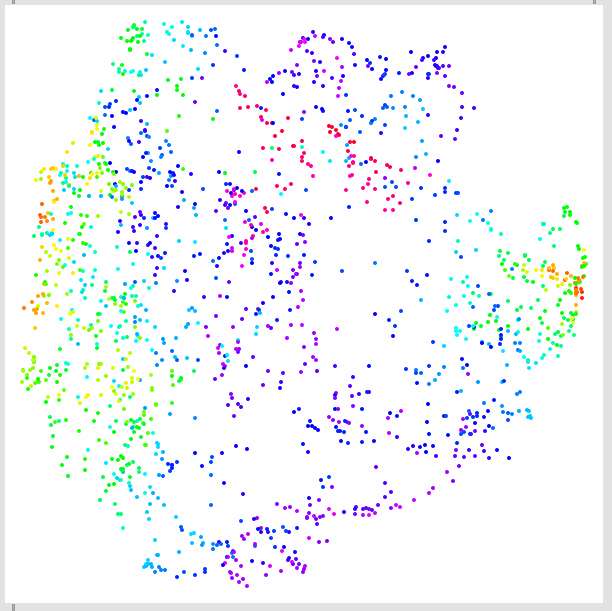
What’s immediately striking is that although the vanilla hsl version looks good (and honestly, better in many cases), it creates artificial distinctions since it jumps around loads more.
Before showing the individual tests that I made, here is a gif (hopefully it loops properly here) that shows a linear progression from 0 to 255, with Linear CET-L20 on the left, and hsl on the right:
You can see huge jumps in color on the right there. Pretty striking given that it’s changed very little in terms of linear distance (on the left).
Here are the LUTs I tested.
First the vanilla hsl representation of the main dataset used above:
So for now I’m going with the CET-L20 as that gives a pretty wide range and flows very nicely.
I’m keeping all the LUTs so perhaps at some point I’ll add an @attribute for color map type, but that’s pretty low priority.
On a different note. Is it possible to tell the size of a bpatcher from the inside? Thinking of adding some resizing capabilities, but since it’s all wrapped up in a bpatcher I can’t drag from the outside. I guess this can also be an @attribute where you set width/height and then manually resize your bpatcher to that space. Not as sexy, but quite functional.
Probably a better way to do this, but here’s another update.
I remembered speaking to @tedmoore a while back about checking to see how two spaces map onto each other but applying the same fit before plotting it. The previous version of this automatically normalizes your incoming dataset so it would be impossible to visualize something that only uses a portion of the available range.
So with that there’s now a @normalize attribute that will either automatically normalize the incoming fluid.dataset~ (default behavior) or will pass the dataset along untouched. This can obviously exceed the bounds of the display, so you’re on your own there.
If there’s a way to clamp a dataset to a range (without scaling it) that may be a handy alternative here too, but for now it will display things “off the chart”.
Ooh. Yes, I like the idea of having a “normalize” flag, but yes, my thinking was that the plotter expects everything in a range 0-1. That way the user can decide how they want it scaled (for example frequencies scaled down exponentially from 20-20k or just normalize frequencies to whatever range they have as two very different options). That way those decisions are made outside the scope of the plotter, which is just intended to do plotting.
In my version here you feed it an arbitrary dataset and it will then do the normalizing for you (for quick/dirty viewing), but that’s not always great as it will spread things out to 0-1 regardless of the input.
I could leave it so it expects 0 to 1 and you’re on your own to normalize too, but I wanted something that you could take a dataset, as it is, and visualize it without much faff.
edit:
It was specifically me thinking “Ooh, I should finally try that thing that @tedmoore suggested a while back” when I realized that I can’t actually do that with the abstraction as it was before.