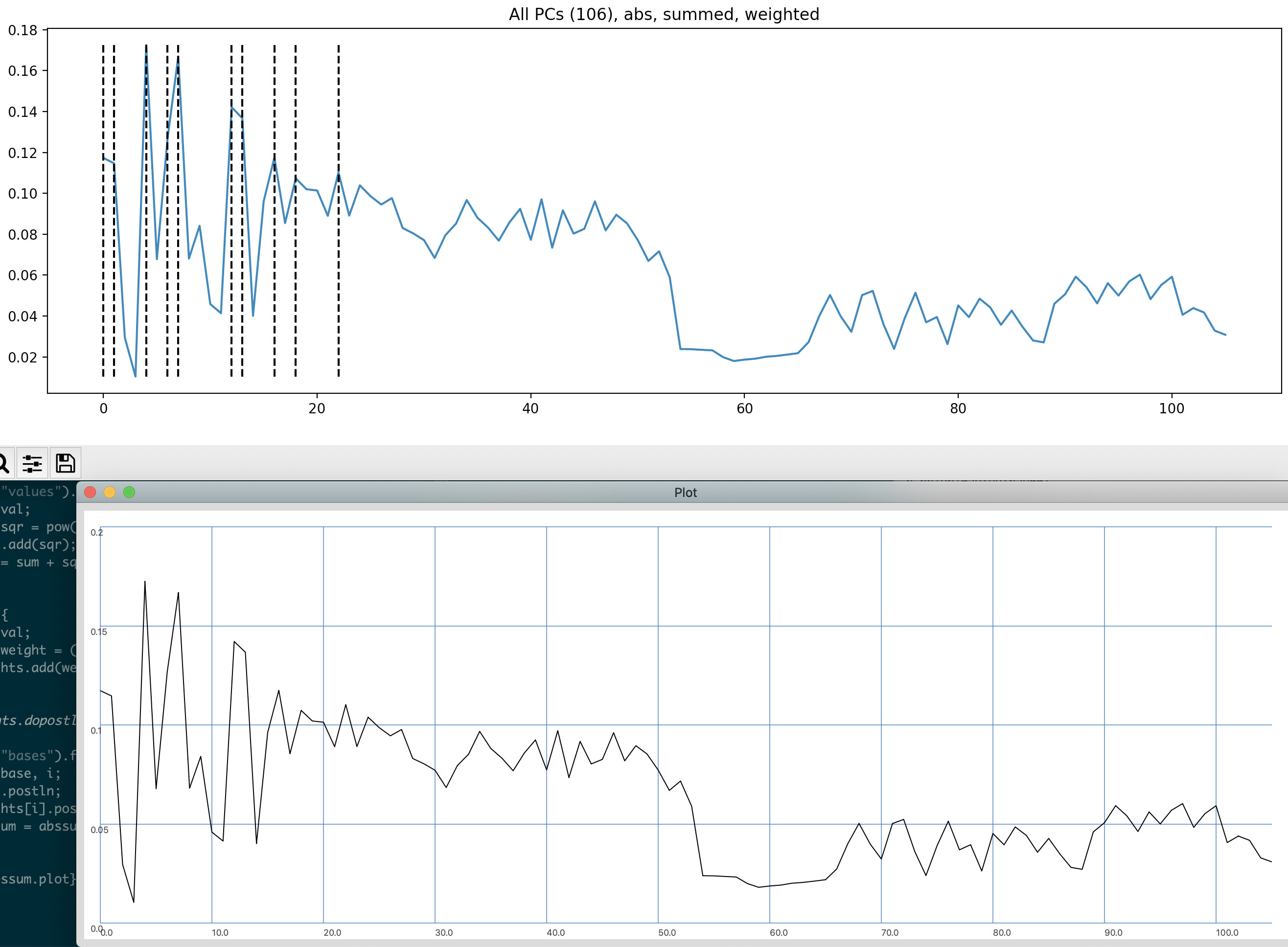
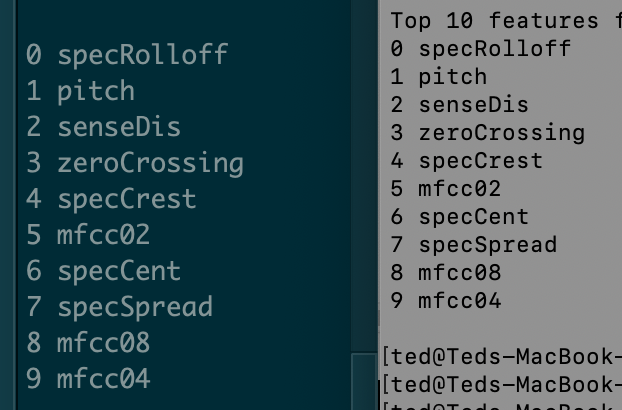
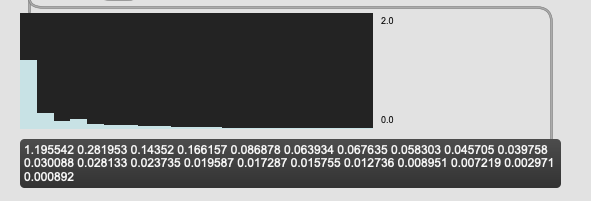
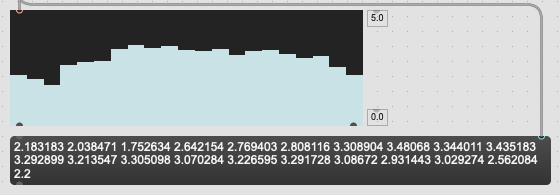
Ok, tested this today and the results I’m getting are the same:
ImportantFeatures: MFCC1
ImportantFeatures: MFCC2
ImportantFeatures: MFCC3
ImportantFeatures: MFCC4
ImportantFeatures: MFCC6
ImportantFeatures: MFCC5
ImportantFeatures: MFCC7
ImportantFeatures: MFCC8
ImportantFeatures: MFCC9
ImportantFeatures: MFCC10
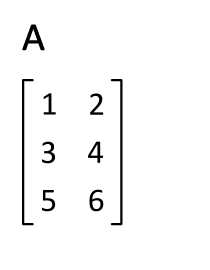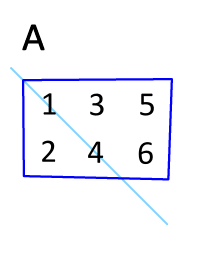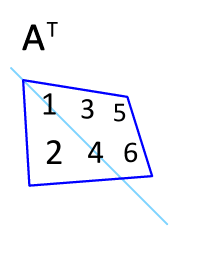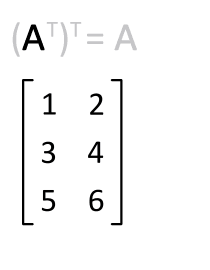
I seems that the values, as they exist in the dump output skew so heavily towards the first entry that transposing the bases matrix (via jit.transpose) had no impact on the overall results.
"values": [
673.8362958342209,
338.6515716175081,
260.5718722831362,
228.3479775847835,
161.27948443092583,
137.3968786415179,
130.18460519211504,
117.8497815323449,
106.45463928836723,
97.96113750682099,
87.04047077667117,
85.19806093624975,
77.16552071744412,
72.7289747754491,
66.65032492000918,
62.996468347624074,
58.49098132121391,
50.31602507677747,
44.452909961833726,
31.008415770540466,
18.333930137956433
]
As a sanity check, could you (@tedmoore) run your process on this dataset to see if you get the same results, as I’m certain I’m messing up something somewhere, specifically at the values step.
test_library_20pl.json.zip (344.7 KB)
These are the columns in the dataset
0, MFCC1;
1, MFCC2;
2, MFCC3;
3, MFCC4;
4, MFCC5;
5, MFCC6;
6, MFCC7;
7, MFCC8;
8, MFCC9;
9, MFCC10;
10, MFCC11;
11, MFCC12;
12, MFCC13;
13, MFCC14;
14, MFCC15;
15, MFCC16;
16, MFCC17;
17, MFCC18;
18, MFCC19;
19, Pitch;
20, Loudness;
Here’s the updated code from before with jit.transpose added in.
----------begin_max5_patcher----------
4561.3oc2cs9aaijj+yN+UPHre3tacz0uereZdr2L6hKYufalCCNDrvfVhxg
ITjBjTNwYwl+1u9AE0KxlMkaKo4R.raKSxtqp9UO5ppl9e7palbewWRplD8m
hdezM27Od0M2X9H8GbSyOeyjkweYVVbk4xljm74h6+3jas+p5juTa93OlVOs
tLNuZUQUxlea95ko4YI0l6D17gqhqm8gz7GtqLYVsclQLwTvsQDBV+Mt4qHz
TPzeu4dRmalD0D+ZzNO7h00ad5nlO09Q0OsJw9n0Kr6VFWWl9kI2FMYRzeWe
c+yW8J8Wt84QyOl7kUkQ+gEvn+M0WQcR0n9oZBvP0LHbJhvPbNv7OnDpndfS
l.DP6lM.6iMDTBuNJKJ6DExXLW+MJcJ0E8QFoXN3B2ulEUsd4nkoTtltHR4T
HiHgDtTPvLNDo9vADofKMIuOdFNVAbCdlPkGimELWztTdIQyaI6+csZbz2UM
KNKtbYw7jH3IpTSwcvDfbjKtffcI4BySmUOcc9p3YeJ5w3r0IU+oSE.fvSIR
DkRrzNVn.+PkUNGzNWdoo8STPiE7iEzTfKia7drcS5iV0Kuzh73xmLp721p5
2bCUwOlL+N0iVs3tKtV4q6900Vu52zxHtYRxx6SLqBvsMexp3x3kI0Ik2kjG
eeVRO+xkwqV09qM+VCaerL+kIUUwOjbD2+yko0Iik8ioLCOFBlBDPLSoaQ4B
HiyTxDhy.HPmEn1rhkKSxqOhZiUyYdcTwhnUIwepJptHpN9SszeVZdxL8UrK
86qBnhO.zjNDY.fBf0ga27AJra9.HfhV5XEqPLhZo.qCCoKEIB4rHI6i3ffQ
ScHgvepCeQwoKRhqWWlTEklGU+gzpn4w0wUI0ABnBrb.hILPNyEPEiBGPsOp
UIC17YKJxqqR+pgqJmBFKkob.Xh.rIZOiWOHuGSQhWdJCDZJiRPdPY3WdJid
+znYYIwkQwKTtohRhm8gn0UgwTpjXiWAZrgJbBPQvWdhst7onEokU0pu9Xxs
QEJpNKS6Fo9CIKCCICHaoUA1EECOC.W5T8FvhVUllOKcUbVj5BWUjqtzJmj6
tnbnXzvbtzHwsheHEZinsG1.aWUqbU3Rle0eII6wj5zYw8vj14dVDOytPCHi
i7RpWPswcwn3o7i1jG2Ilg9xiYHSilud4pnp50KVLIL.BjhfnZKcRqqaqcAR
ODI9ZDQfmprZjOORMkQySUWRkd6DYo0O8RpIAAFGEXIoisCRDNUrPWirQzzn
28ieeTZcfPVPnQgARr1cQNAVvqQNBbZTYR7baLhIQOnbMkGM8iUE4gkE0riN
nzEKRdI4P8sIAznyfjvlkH6NEbuEA1Ec+OidycBL0WJ6hld6uloP0OL9M2Yy
YOgZyKjyzcItz45UGVUczeUEQUYcbd8O0rauwlxOHxtecLQZyCCBAfTFlvkJ
CaXmY7lyCW.A8KIS0g.AGuvzRWHfw9Cg6jPXWZoYoZJRhpdZ48EYmJoh0g+e
Xpz3NIbl7RS3yJTaBZwyD7hrQ46ttiL7HyZa24pUufuSmJkCyN61nufax.6l
K68lKr8RU+lOk7zt4pU8IlT12Lyu8m9weD1vluYCStyG.r+G.xqG.p+G.1qG
.t+G.wqG.o+G.0qG.s+G.yqG.q+G.2qG.u+GfvqGfn+GfzqGfzAPB3GRxEVz
SvnCzHzO3HzAdD5GfD5.QB8CRBcfIg9AJgNPkP+fkPG3Rne.SnCjIzOnIzA1
D5G3D1C57coJK59YkpGv4aJVOOOQ6gY6CoYn5ocZEWq058JkilT8FsM1HN8x
l4JH0GOUm8MUf.6z8NUbMzDFYoyRhNkZszPoL5wQlJbVHdJ+ZftUAlepaAQP
2lBydIRvUQraGmT2Q1sABkX9nBvKotHchHHgxc5kcOPVF5svjSAR.A.i.SQR
L.QUCTgyiwPy.DPp+D.kifB8.lDSLCnX0l.LCT2NVOfPoHjd.lRklAHoRIxL
fRnLy.BRx0CfB.xNPplNy.NtY.FJM2kZtElo.nDXlaGfEMCzUXpyDRhOsDMP
Yl7E0TvJ8NT6DMvOK4ZPgMp2lVrQVMhlTlPbk9KxXyYx8w4OrEM2YufDNk80
eMMZzILpg5gHibj4rsNH8TkXrSx+1seOUi0BZSRd+3aRxM8DZW8Pms7q8R+v
QZOeCcG1jBNZ+zTnIQfbkmqi6BV2MHA3Rljv+3I2afbBYrjJdr1nBMX9iEo4
mJ4JviEKiuno+031IorSxkNL41EPl4LTLLYjwinkt6DRxIKr6SI1T83STQtS
SWXmwigwWVw8yJLzlXMZ5sW2AdhA++6.OOIbSSamffcrOM23Fz4oogWtNqNU
sMz48XSXyzUkTq9T0sZmMSnK6tx6G7zzrXXp4aPHqG5cf8kpV.U0OYCcqcQ0
T6UDbf80E3v.Osvc2fEnjgi2EwtJh28DiqWXZ7Qrj6AgRtlCrOqHdt1dPDv2
+ehfBL.zQXSbfSKDfKZExMEYczIwgY7jvrInyYhptr8+rtyOFMwY6mCVa+T5
vY4kLnfEYqSmOsokm+Vzqe8qMGtwzjdjmdzkO1NdFRbJQgm3lXWnTCqegNPX
w2W8u7GV.+WG8A9qI6Kvia+KA08QgS96tS2Xim7FC5Bt6S2H954n98GOkit5
Fp0V3bgvszDdIkl1ViPEje0nsUIM1mnJ+NGAfcugNw4quH5MT7Sffs9RIfN5
WSrS2rBwEtcsdPIkWE8ceMSc85HdU9MAfQmJpFCVB3TNVHvPK8S4XkYagSeU
hKtBc.cX0.CnftZaWmdu3nqJ2W52IAUqRUau+6xRqTSc9C0evAzXXeYJSAJ3
fTWCE8dTEL8o5cf5rgtNZNLcewOZEBVSqZxr4szIcRt317NERDC1dNeNr42b
KXYWzzO+wpnUyhuSSxSUiuWo1WcpuQF55HLCQNk1rSvm93xd0hTk95ll3dGR
chyCub3yo0hz5gslN7NdZxOn8Pjz6VdjW987nX0eK56Tye6AEopmB2M7ddPT
PGcEr6sriYizGh1zd.7gnQhqSmL9SbculOfTmBaRqvVO0VAytbc2PAsT6tOm
Nu9C1Vmi1dzJF.jXVJlxqevq8GC0o+78YRUEqKms4Q07B3IZKAMOopNMOttI
oxueqSO8E0obv2IRaiYvYJDSj90OxfSj9sywNWTQoNcv8dXQB5Tad0vz0bCd
VysvKxVEYaD7Yxf06OXvYhGBQ4ARo93mzPPTXumpmKUw8QRsAJ87lIejTTPH
lIejTLbHlIpOnufv8zPXzPZTgXlX9fHzGvlm+L4CLmEDZB3wLgYgXl7Xhz8S
zy1FA0K0oPHl17PbCHBAySuQOOr6QBwTg7ZpBA3yXSCNjjRDhY5bA9Hxyk9D
waZ5YOSDeUnd1bO7YalPd.83g.5Q7w+DNDd20ci3fzDNDggQ7YWB3PXMh.7c
lPO2YxGydAfhvmMKDXebOgCQrxlk6PXbZHvCXur5EB8VrO.BbHBi.iGAME1s
B62T+hrSXLvq3LBhJ2YR0F4ipMJDp1HehlFEBmJHz4xbExe.wy0+Ua3qCmFF
vydp7xhELHSEwmfZnAapFbGpggp7Q80DpFLzlG8atI78l6koyWUjlW2jpWAg
Xd2DhMsmBDy3s+XnMo52xEw61bNJ.yMzW02t4URn8s4hsxuRJeJhdzOhIlZY
nu1M+zyFh4UVuIuDdf8atOTxFL.Cv2rvC6nfFwqV8XR4lda2LKSVF+whx12O
BJAbt8GM0PYRYxis8Bu8sWvj3xYeHsNYl9sIhofLegYqp8D8KC7x70oMLYyo
CehoYqOnJJskr76WOOs3WpiqWWc2aSxWaKmihrVDuNqdelw8OrHMKaVQlc8s
aYP2TGmI1e6ssusPZt12aNjmDHTnXdSwPLGwLiTCnzcv2M2CbyMQnDI.ouTc
oeITyHABSw5QfCtMz14B.k1Y.HE.hcj5iz0Ld2aKN+AaMYssna6IPnP+FGpg
sqtUY60utt3gx34lZrdTobusAKUpOhFa5w8IM7TSC5u4d1E60JLdy5Mu+u5V
.rG6jvoPrgefjXgzNhBAL4djnWRsVJpGAmmLy8EchVAlfCnBgcjff671ZEcL
pZRzWKS+Otcj8I8hH4ZOUBYIl2e46Q5bjheZVMPFGYwbB..RNjGu2cIADntF
xJ5URIbCMHzG+XC2fxZuu3YyTql8tWLRg3MbXxFFgVGgbfTc2WdbJiN+WqRx
i9k37pneIYY58EYy21ICJBa4gyBWnXsVYC.JD1QpIDg1eZz0u0bi2klqMbkz
hIvRDjYwbazPQ6JbChBwaiqqcoPr6qsO8axwCXPadS489s1helKn28802YtM
f25oRp1vmUvS3.COSqFgOPhZNUR6bmlt5Qc6J7C0pOnTiLM42uiUt891Br18
A.EjKcWKs20nc47cn55mkqCUc+9xz3rICqwYPCa9R3Tw9se8m7FJC09ss1vz
3WiROeiG7qAToeFOu3AKzMnTzOnDxvJaGF2PbBSJaFAjChIo.NyPP.FECsOB
HBhb6N4u7z7xhGRx+UizxkiDBCp1utIpLIhQLbQpDpzo2eBZiudewrNRPiWU
0ZhxrhNscACzRFHHto6oRm4ejUMVm6ZzXg4cDO7VanXI2ZADKabQn+HJNLn0
8nIQq+5iGcRXbWPYY+HY+n4tPx9JUN.J+yI4IOFOY.f3wFWuPliavp+vNGWy
AQrMQJHZAFflQAeY8m0tpt1VT+bbZ927V4F25453QgeoU8Yya+MGKtiP5vF.
01u7hrlPWUKp+ycO359gsNX03bab9aQ2OqBc5Ibn4Hj7q2jLeb5g9RErWTyZ
u07W3xY0kYOiUePWP5Ny+atS503LebsfP9aEy2bTK7vpnmgG3vO+kmfGkIjW
ZG3+s0Ku28hoKKUG6z7EXo8tzY0Cyqt3xy2Ulz92wqqnnM9kYEqR7ObisYsV
h0+qCyvGXg4rxj+036C91h5B4Ln8kfRTpX1uezAP2c7DcrQjWVCG+ZwC5MfE
rvYcHTvbFgCs2AACM6jjzTVkPRR+OKGnvRmw.M+s3GSVTTt7aAmCO9HOA55Y
GDhadb4mdcd5Cen90l829bqhW2ImCN.vI3IsH3Ila+jVzt29Qlc5tLJ3aV96
N8CjVih71hozVVEg4wDHjxGMKfjRvlW2Eg3Q4bujGVWCmYoEDvzq42z76Bj5
ggcS6sXB2mkn76YKE3OTT7ogR701ZVbz.Pvfbo4exaysLESCHZcwhY.kBn6J
ksagILWNd2QAHis9u1NiVJOK0+1CowQVQ83dNLovmtcWOlrNSywv2Ve5K2t2
WCW.Jextmre6Cs+YF+xErTlNThgCg9vbi.jjl9PQJwBdyHtviMHvZc2QasQu
Q4Ibz0x3uvzmudeooCXvfcL71AVTr+9a3M5uWxxInIXyaH.+2kGBSQx8cVp0
NCtbXu2jEuXgpJZKE+wibXElKz8X1scN5LFEfm1tCDpZesC+jh1WiCiKoa6z
SeAOuF1WZH+P15jMujB8rBG5tRj2Tj8sFijA2DTyBrr3y4idEddLRZWg+3Sw
ieAp+ytgsG.3bLFY01PPU3YgeA9ykIImvJzv8ZSEGjoi8H7Kt2prrkWGO5km
f.XLaRBY.0hyvJYRnjF903+cx7Qu93sQwBa2TEnwiQnWe+uIYYEe18R7395h
JA.gSuzHpsOX3BnvDZt5dnD5KFAf98HAXJewOWjcBPj17ePUQBQssbztNACx
Bb05xUYIiJ3TBvFWChBXRCFFInLjvyHz3ssCHARUlML11zVOBJiuLYVR5itq
bWWXh18MscwA1s2CCyhytEEMrv+8ySTFzjMNB3M8BsBsJwN2R34AEUkjOu5Z
yCxVlracuCZaUNDvs0Yhv.xlVNmCoCtE5yCqtNd0P1A2IOVuIttH5M5cgNIX
yeUcxh0YY0iq.K5CsB2vcXsQ2qSdvgM33gcrofRg1D4xvbrsS4YJURVXYpVh
57PSHAWXCNA2B+wHIVJtV1eecR0004E3y5r47j+KILavJJAzxNyFRwMhLkJb
S0GbzGj+4zx5mh9OdnXnLBCkRfMvSEZkzTMcF.fgM8j6PNJGpM3GOi0d14LU
vSSQUqZjSl2Uhu5e9p+O.Xmv2BC
-----------end_max5_patcher-----------