Thinking about this some more, with my low-level, but ever increasing knowledge in this area.
Also, sorely disappointed that no one has commented on this gem:
///////////////////////////////////////////////////////////////////////////////////////////////////
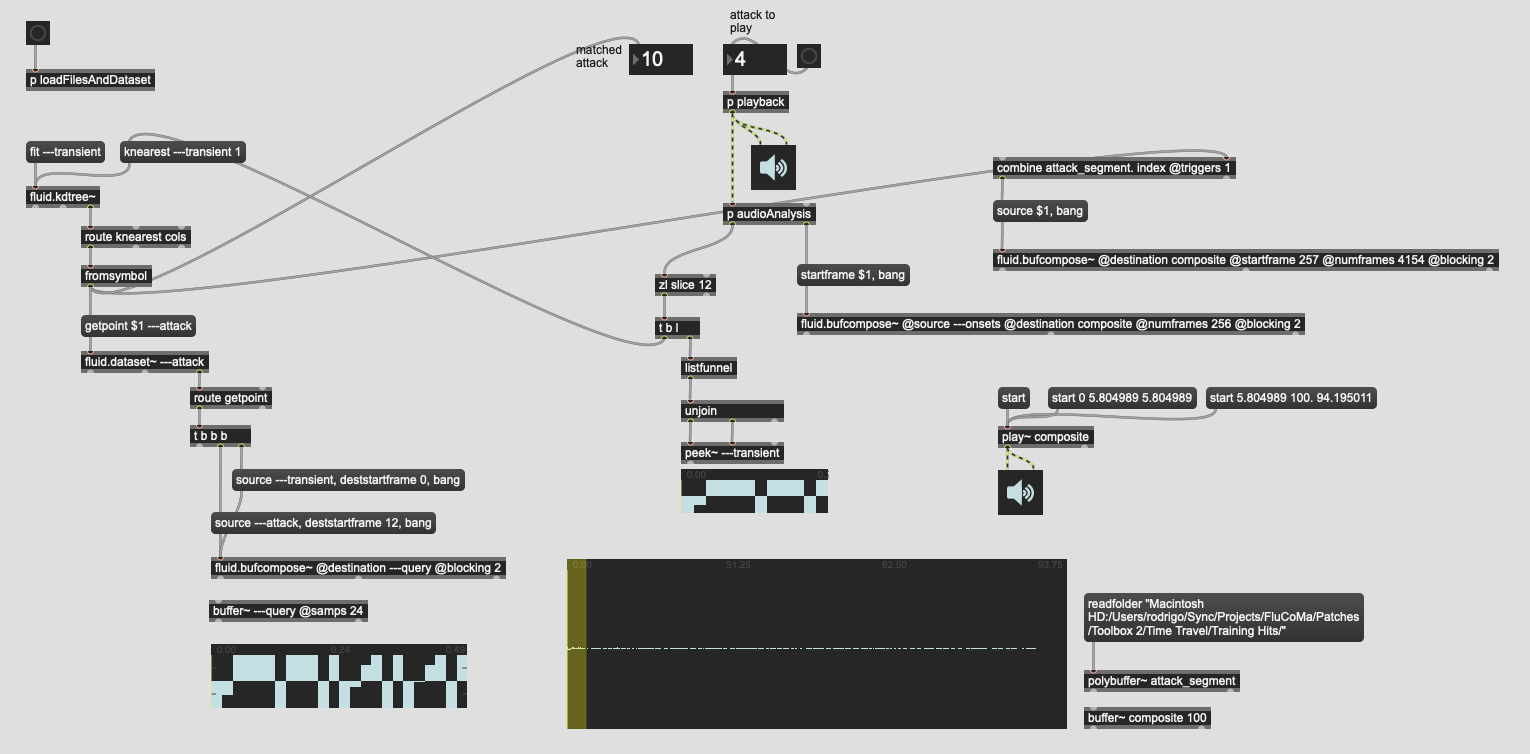
The first thing that comes to mind is to try to create a training set that will be fed into fluid.knnclassifier~. Since the idea would be to capture a fairly solid representation of of the amount of sounds I can make with my snare, which as wide as they are, are not infinite, that I could give me a few hundred examples, making sure to cover different timbres and dynamics.
Since I don’t know what these sounds will be ahead of time, and I’m not terribly interested in creating a (supervised) taxonomy of these sounds, I was thinking of just assigned each individual attack a unique number which corresponds to its class. The data for each point would be something like 16-20 dimensions of (summary) descriptors/stats, and this would be only trained on the target transient, as defined above (i.e. first 256 samples of a snare onset).
So something like this:
1, -35.584412 -1.791829 3.50294 123.374642 -284.869629 35.527923 -3.364674 0.773734 0.322499 132.203498 1097.339844 68.029001;
2, -33.469227 0.217978 2.396061 100.806667 1306.492188 71.573814 -11.920765 6.502602 1.149465 97.934497 527.226685 82.160345;
3, -23.90354 -0.69517 3.378333 116.119705 -735.833984 51.341982 -6.689898 -1.087609 0.252694 127.367311 -2514.203613 74.122596;
4, -28.433056 0.200565 3.09429 96.997334 614.809875 77.417631 -14.684086 4.913159 2.038212 93.661909 -87.01062 25.470938;
5, -18.193436 -0.639064 3.84877 116.842794 -309.310791 35.34252 -5.882843 0.371181 0.325729 121.526726 242.327148 42.387401;
Logically, this seems like I could then play in arbitrary snare hits, and it would tell me which individual hit it was nearest to, and with the unique number it returned, I could then pull up from a coll (or entrymatcher) to retrieve the corresponding target attack.
BUT
This seems like a bad idea. Having a classifier built out of hundreds of hits with only a single example of each. Not to mention that my “matching” resolution would be limited to the training set. So if I only have mezzoforte hits when I strike a crotale with the tip of my stick, it may return mf values if I strike it softly, skewing rather than improving the matching. (this could be mitigated if I just use MFCCs sans the 0th coefficient, since it wouldn’t so much reflect the loudness of any given training point).
This approach could also potentially work well in a vanilla entrymatcher approach, where there are discrete entries, and I’m trying to find the nearest “real” match.
The overarching approach would be the same in that context, matching the nearest, and then bringing up the “missing data” to fill in for the target attack, to then query again but with a complete set of data (target transient + target attack).
///////////////////////////////////////////////////////////////////////////////////////////////////
After @tremblap showed some of the features of the upcoming neural network stuff, I was thinking that a more vanilla regression approach may be interesting.
I’m definitely fuzzier on how this would work, so semi-thinking/typing out loud.
So I would create hundreds of training points where I use target transients as the inputs and give it target attacks as the outputs, with the hopes that giving it arbitrary target transients would then automagically give me predicted/corresponding target attacks.
I guess since the algorithm is making crazy associations between its nodes, there’s nothing to say that the output would be a “valid” set of data (as opposed to some interpolated mishmash of numbers between the training points).
If it does work, it would be kind of nice, since the output could be more flexible and robust to unknown input sounds.
///////////////////////////////////////////////////////////////////////////////////////////////////
The last thing that occurred to me is that if I’m using “raw descriptors” (e.g. loudness, centroid, etc…) as my inputs and training data, that I can apply some of the loudness (or even spectral) compensation methods discussed elsewhere here, where the nearest match for a target transient is 5dB quieter than the incoming audio, so compensate for that difference in both the target transient and target attack.
This, likely, wouldn’t work with the regression-based approach, but I suppose the idea there is that it wouldn’t need this kind of massaging as the algorithm would take care of it for you.
///////////////////////////////////////////////////////////////////////////////////////////////////
My gut tells me that the classifier approach is more what I’m after, though I’m not sure it’s altogether viable (having loads of classes with just a single point each). The regressor could be interesting, but only if the automagic aspect of it works.
For now, I’ll try creating a viable training set with hundreds of sounds, and with a bunch of different descriptor types.
I would imagine it would probably easy enough to create a test patch that runs the input on itself and then stitches the input (target transient) and output (target attack) together to see if it sounds “real”. For the training points it would be a good way to test if the thing is working at all, but then giving it a lot of similar, but not in the training set, hits to see if it can create approximations that sound believable.