I was thinking about this today as I was planning on recording a much more comprehensive set of “sounds I can make with my snare”. Knowing that the corpus would be so specific to the snare, the head, the tuning, and the room (to a certain extent), and that it wouldn’t necessarily translate if I went to a gig and used another snare, or even just had my head drift in tuning over time is a bit of a bummer.
So that led me down a couple paths of thinking.
- creating the minimum viable corpus for any given snare (maximum variety/dynamics, with a generous helping of data augmentation to fill in the gaps)
- create a monolithic corpus for each setup I have and just streamline that process
- thinking about the viability of having a mega-chunky-corpus, that is continuously fed new snares/setups/tunings and keeps getting bigger every time I use the system with a new drum
- if it’s somehow possible to train a NN on some kind of archetypical aspects of the sounds (within the word of “short attacks on a snare”), which is then made a bit more specific with samples of the exact snare in any given setup
Part of that last example was remembering the topology if the machine learning snare thing that I was looking into a while back:
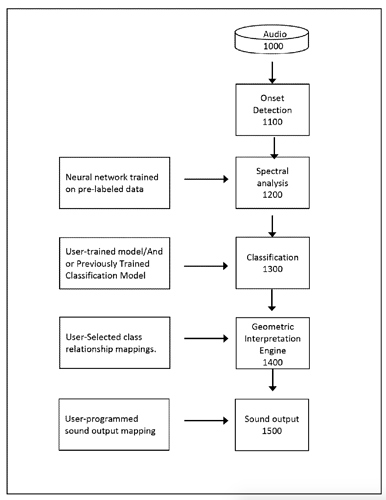
It could just be that this makes sense for the purposes of the patent application but from the looks of it, the NN is trained on data that is distinct from the user generated and trained aspects. In fact, remember when I last used the software, you would go into a training mode, and give it around 50 hits of any given zone (“snare center”, “snare edge”, etc…), and then come out of training mode and it worked immediately. There was never any computation that went along with it (unless it happened as you went and was super super super fast). You literally toggled in and out of training mode ala a classifier. But there’s an NN involved somewhere/somehow. How?