Had a great geekout with @tremblap this afternoon and he walked me through his workflow when using fluid.mlpregressor~ as an autoencoder.
I was initially comforted by the fact that the faff, and the results he was getting were in line with what I had experienced up to this point (when being used with “real world” data, vs toy examples).
Off the back of that, I’ve spent the better part of the afternoon/evening running long training things, tweaking settings, clearing, rerunning, and plotting the output to see (and hear) how it’s performing.
I have to say that after hours of this today, I’m no closer to having a useful reduction, particularly as compared to UMAP or even PCA on the same material.
By an absolute longshot, this is the best fit I managed to get:
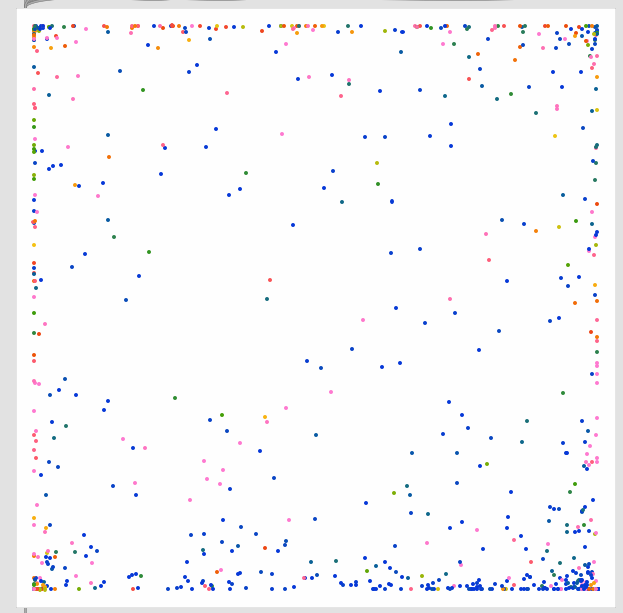
Clocking in with a reconstruction error of ~45.
The clustering here is, as you can probably imagine, dogshit.
What’s in this dataset is 76D of MFCCs/stats (20MFCCs (no 0th) with mean/std/min/max) run on a mix of different percussion samples, and is exactly the Timbre process from this patch.
Here’s the same data with PCA:

Raw UMAP:
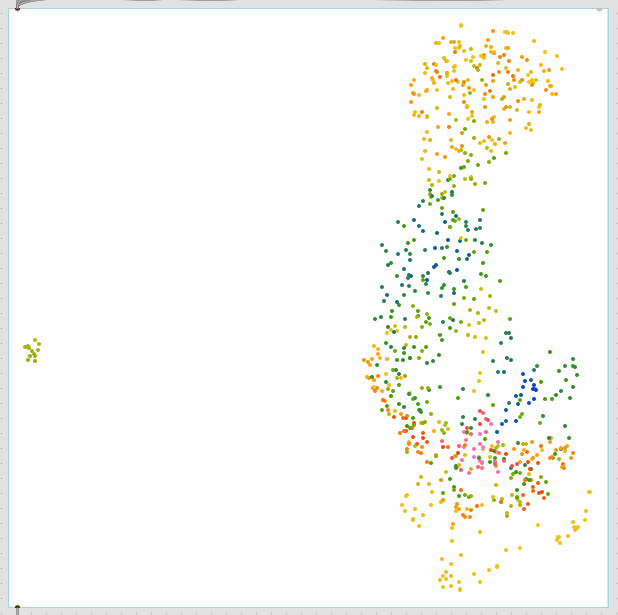
Standardize → UMAP:

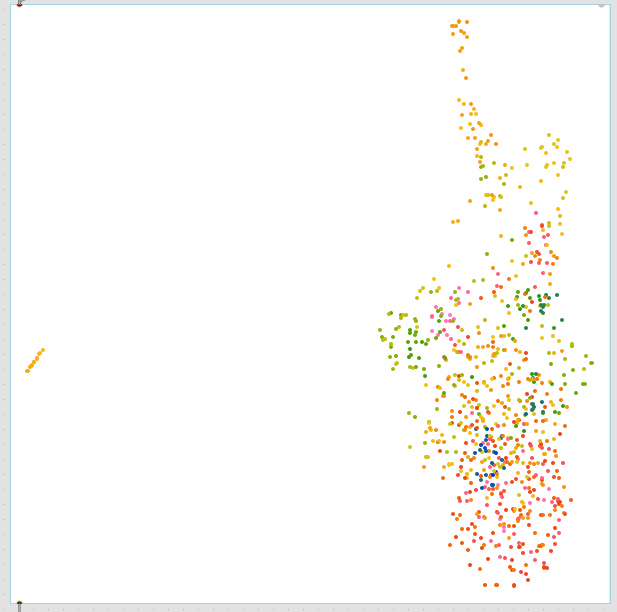
Robustscale → UMAP:
So a couple of things strike me. One, the interface is quite different from other similar objects (predict vs transform for example), and then some of the feedback is a bit weird. For example, the reconstruction error is, apparently, a sum of all the errors, so it scales up with the size of the dataset. This is really confusing as seeing an error of “45” seems unbelievably bad (which I guess it is), but the magnitude of this error is relative to the data which it is attached to. Not sure why this number wouldn’t be normalized to 0. to 1. so relative comparisons, or a sense of scale would. make sense.
Also, it would be really nice of the @activation info (via attrui) included the range in the name (e.g. activation (3: Tanh (-1 1)), or even just activation (-1 1)) or was even only the range information as that seems more significant/useful than the function being applied.
//////////////////////////////////////////////////////////////////////////////////////////////////////////////
Lastly, and I guess the main point of this thread, is the general workflow with autoencoders super fiddly, and potentially not viable for certain types of data? Up to this point I had chocked up my failure to get useful results from a lack of understanding (which I still have in spades), but after speaking with PA and seeing and replicating his workflow, I’m nowhere nearer getting something that converges in an even remotely useful way.
Is this indicative of me needing to learn the voodoo/dance better? Are MFCCs not good features for autoencoding? Are certain feature spaces, or specific instantiations of feature spaces, not suitable for autoencoding?
//////////////////////////////////////////////////////////////////////////////////////////////////////////////
This is the data I ran the above on:
mfccs_76d_DPA.json.zip (537.6 KB)
And here’s my “good” fit:
mlp 45_2.json.zip (39.8 KB)
 ) include adding noise to original training points; or going back to the pre-statistically-summarised points and summarising at different boundaries to get different (but ‘true’) reports of means, derivatives etc.
) include adding noise to original training points; or going back to the pre-statistically-summarised points and summarising at different boundaries to get different (but ‘true’) reports of means, derivatives etc.

")