As I mentioned briefly in this thread, with a bit more of a descriptor-based solution mentioned in this thread, one of the things I would love to be able to do with the non-database side of FluCoMa is to be able to train a system with specific sounds, and then be able to (quickly) match them, as well as being able to extract controller data from that as well (either via descriptors or via geometric/nearest matching distances).
There is a commercial system/product which does, more or less, exactly what I want:
Sensory Percussion
It uses a special pickup/trigger which you attach to a drum which has a small metal disk attached to the head. As far as I can tell, it’s just a hall sensor that is being sent over as “audio”. (it just sounds like a shit version of a close mic, but with sharp onsets and very little bleed)

Beyond that it’s a software package that you train on different sounds of your drum (10 sounds total, like ‘Center’, ‘Edge’, ‘Cross Stick’, etc…) and it then matches those sounds and uses that data to play back sounds via its built-in sampler. It also does a thing where you can interpolate between points to use as a “blend” function. So you can somewhat/crudely tell where on the drum you are playing from center to edge via audio.
All of that is great and all, but as with much “cool audio software” these days, their app is a walled garden in that you can either use its own built-in sampler, or send out 7-bit MIDI. I’ve built a patch for translating all of that into something useful in Max, but it’s still shit resolution, particularly when trying to extract some more meaningful data (like the “blends” stuff). Plus it uses proprietary hardware, which isn’t cheap. I do own one of the sensors though, so that part of the equation isn’t a huge problem for me.
Now in looking up their ‘patended’ technology, it’s a ML-based system:
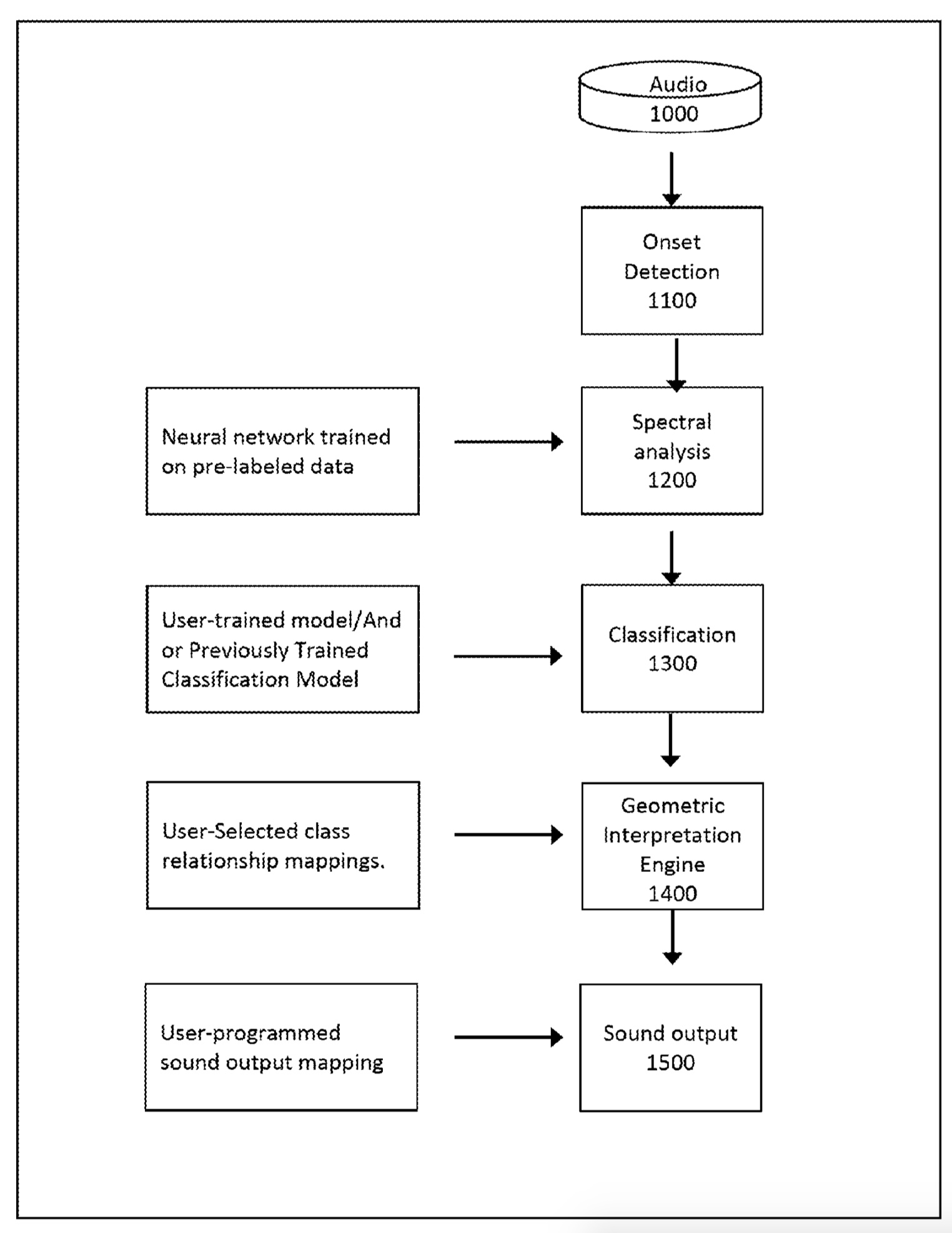
The patent pdf goes into a fair amount of detail on each of those sections (including their onset detection algorithm, which is by far the fastest and best algorithm I’ve used). It very quickly goes above my head, but I was wondering if some of the algorithms at play here are already implemented, or planned in the FluCoMa universe.
And on a more specific note, I don’t know if it’s possible or an planned aspect of being a “composer” on the project, but would it be possible to get an afternoon (or day) with either @weefuzzy and/or @groma looking at this specific problem/algorithm, especially since I think it would be generally useful to have some real-time/onset-tuned ML algorithm stuff.