Ok, I’ve built a thing and got it “working”!!

(actually had a gnarly crash, which I made a bug report for)
I’ve trained it on just 10 hits, and am feeding the training data back in to see how it fares. Surprisingly, it only gets the correct results 50% of the time, which is unexpected as I’m feeding it the same exact as it was trained on. The real-time version is running through an onset detection algorithms, so it’s not literally the same data as it may +/- some samples, but I guess that has knock-on effects because of windowing etc…
(I should note that the training data was, itself, segmented off real-time playing and the same exact onset detection algorithm)
If I test it on the same literal buffer~ data it works perfectly, so the system/plumbing is working.
Here’s the patch as it stands:
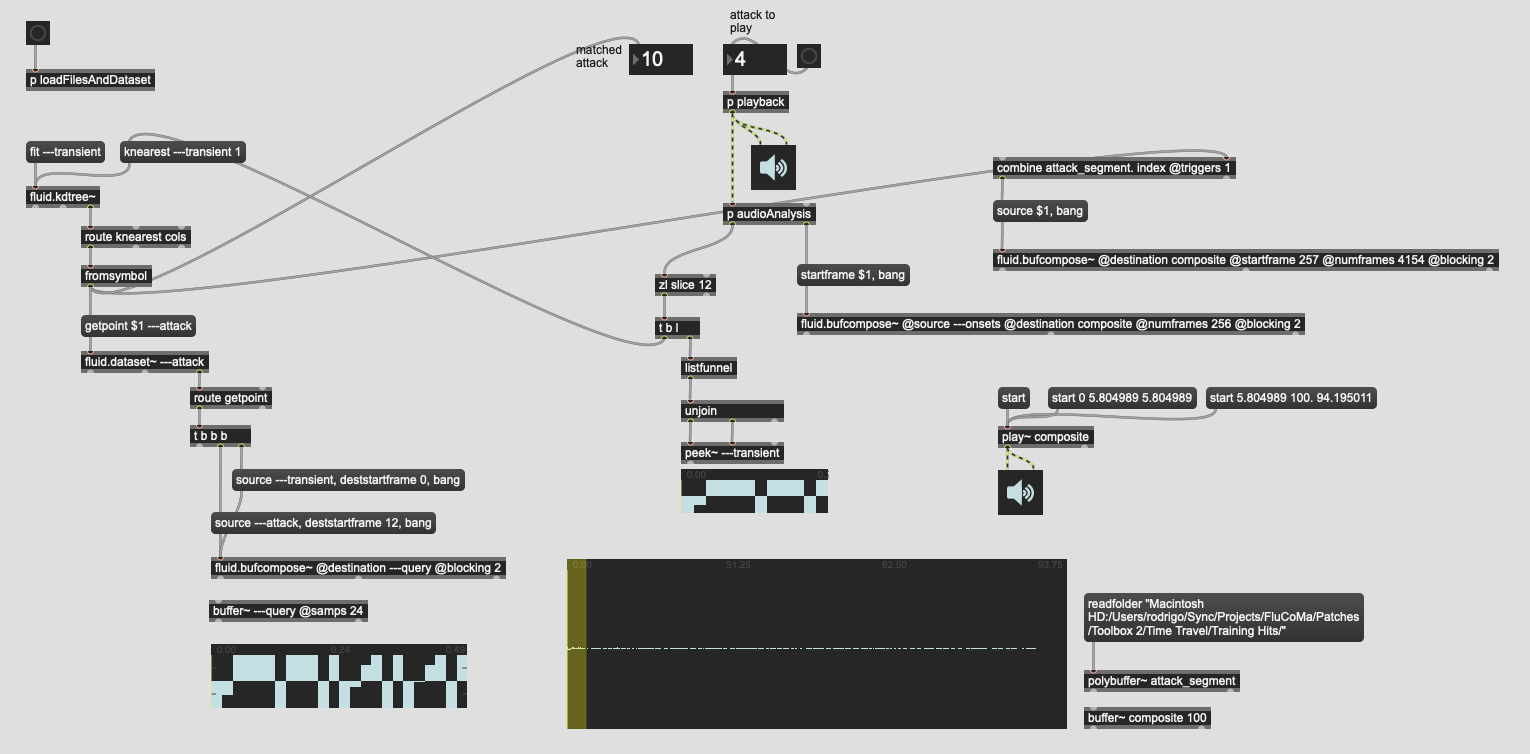
At the moment it’s oriented around validation primarily, so I can play specific samples, see which ones are matched, as well as fluid.bufcompose~-ing a franken-sample so you can “hear” what the algorithm thinks is correct. Even though it was 50% wrong, all the composite versions still sound believable, so that’s good.
It will definitely be critical to weigh these segments differently, since the second half (at the moment) has pretty shitty accuracy.
Speaking of…
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
At the moment I’m using the following descriptors:
loudness_mean
loudness_derivative
loudness_deviation
centroid_mean
centroid_derivative
centroid_deviation
flatness_mean
flatness_derivative
flatness_deviation
rolloff_max
rolloff_derivative
rolloff_deviation
These have been my go-to descriptors for a bit now, but they definitely aren’t robust enough for this application as an onset detection’s worth of slop in the windowing brings the legibility of them down to 50%.
(it should be said that I’ve not standardized or normalized anything here, but the input is the same as the dataset, so it shouldn’t matter that much…(?))
Off the bat, I can take all the spectral moments, along with all the stats, and perhaps even two derivs. Maybe throwing in a manually-calculated linear regression for good measure. Basically a more-is-more approach, but primarily based on “oldschool” descriptors.
OR I can try throwing MFFCs in the mix, as I did have the best results with MFCCs and stats when I was trying to optimize the JIT-MFFC-Classifier.maxpat a while back.
That patch, notably, does not do any dimensionality reduction, nor does it take any loudness descriptors (not even the 0th coefficient, looking back on it now). So it just brute-force takes a 96 dimensional space and matches based on that.
So I’m thinking I might do something like what @jamesbradbury is doing for his macro-segmentation stuff in Reaper and take MFCCs with all stats and two derivatives, and do some dimensionality reduction on that to see how things go.
This quickly ends up in territory as discussed in the (ir)rational dimensionality reduction thread, where loudness is important, as a perceptual entity, as is timbre, so if loudness only represents 1/13th of the total dimensional space, that’s a bit of a problem.