Ok, I got to some coding/tweaking and made a lofi “automatic testing” patch where I manually change settings and start the process, then I get back quantified results (in the form of a % of accurate identifications).
I’m posting the results here for posterity and hopeful usefulness for others (and myself when I inevitably forget again).
My methodology was to have some training audio where I hit the center of the drum around 30 times, then the edge another 30-40 times (71 hits total), then send it a different recording of pre-labeled hits. These were compared to the classified hits and a % was gotten from that.
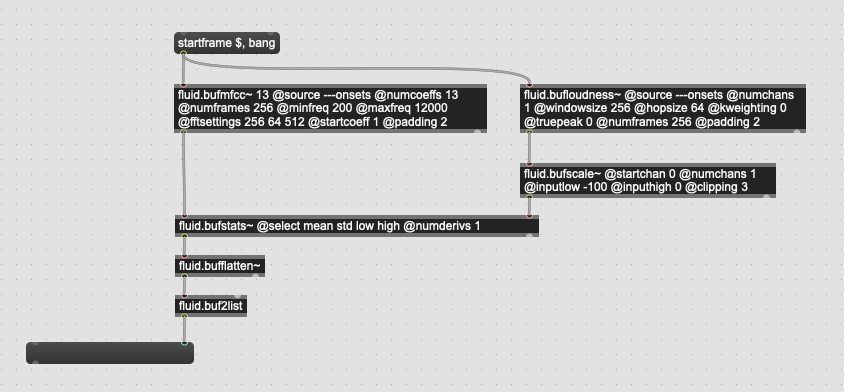
Given some recent, more qualitative, testing I spent most of my energy tweaking and massaging MFCC and related statistical analyses.
All of this was also with a 256 sample analysis window, with a hop of 64 and @padding 2, so just 7 frames of analysis across the board. And all the MFCCs were computed with (approximate) loudness-weighted statistics.
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////
To save time for skimming, I’ll open with the recipe that got me the best results.
96.9%:
13 mfccs / startcoeff 1
zero padding (256 64 512)
min 200 / max 12000
mean std low high (1 deriv)
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////
As mentioned above, I spent most of the time playing with the @attributes of fluid.buffmfcc~, as I was getting worse results when combining spectral shape, pitch, and (obviously) loudness into the mix.
I remembered some discussions with @weefuzzy from a while back where he said that MFCCs don’t handle noisy input well, which is particularly relevant here as the Sensory Percussion sensor has a pretty variable and shitty signal-to-noise ratio as the enclosure is unshielded plastic and pretty amplified.
So I started messing with the @maxfreq to see if I could get most of the information I needed/wanted in a smaller overall frequency range. (still keeping @minfreq 200 given how small the analysis window is)
83.1%:
20 mfccs / startcoeff 1
zero padding (256 64 512)
min 200 / max 5000
mean std low high (1 deriv)
81.5%:
20 mfccs / startcoeff 1
zero padding (256 64 512)
min 200 / max 8000
mean std low high (1 deriv)
93.8%:
20 mfccs / startcoeff 1
zero padding (256 64 512)
min 200 / max 10000
mean std low high (1 deriv)
95.4%:
20 mfccs / startcoeff 1
zero padding (256 64 512)
min 200 / max 12000
mean std low high (1 deriv)
92.3%:
20 mfccs / startcoeff 1
zero padding (256 64 512)
min 200 / max 14000
mean std low high (1 deriv)
92.3%:
20 mfccs / startcoeff 1
zero padding (256 64 512)
min 200 / max 20000
mean std low high (1 deriv)
What’s notable here is that the accuracy seemed to improve as I raised the overall frequency range with a point of diminishing returns coming at @maxfreq 12000. I guess this makes sense as it gives a pretty wide range, but then ignores all the super high frequency stuff that isn’t helpful (as it turns out) for classification.
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////
I then tried experimenting a bit (somewhat randomly) with adding/removing stats and derivatives. Nothing terribly insightful from this stream other than figuring out that 4 stats (mean std min max) with 1 derivative of each seemed to work best.
92.3%:
20 mfccs / startcoeff 1
zero padding (256 64 512)
min 200 / max 12000
mean std (no deriv)
93.8%:
20 mfccs / startcoeff 1
zero padding (256 64 512)
min 200 / max 12000
mean std (1 deriv)
90.8%:
20 mfccs / startcoeff 1
zero padding (256 64 512)
min 200 / max 12000
all stats (0 deriv)
90.8%:
20 mfccs / startcoeff 1
zero padding (256 64 512)
min 200 / max 12000
all stats (1 deriv)
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////
Then, finally, I tried some variations with a lower amount of MFCCs, going with the “standard” 13, which led to the best results, which are also posted above.
83.1%:
13 mfccs / startcoeff 1
zero padding (256 64 512)
min 200 / max 5000
mean std low high (1 deriv)
96.9%:
13 mfccs / startcoeff 1
zero padding (256 64 512)
min 200 / max 12000
mean std low high (1 deriv)
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////
For good measure, I also compared the best results with a version with no zero padding (i.e. @fftsettings 256 64 256), and that didn’t perform as well.
93.8%:
13 mfccs / startcoeff 1
no padding (256 64 256)
min 200 / max 12000
mean std low high (1 deriv)
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////
So a bit of an oldschool “number dump” post, but quite pleased with the results I was able to get, even if it was tedious to manually change the settings each time.