I want to export an STFT analysis into a Jitter matrix then do the inverse operation.
I have tried with regular Max objects but I’ve met several issues, especially to resynthesize a sound from a matrix containing STFT data, so I’m having a try with fluid.bufstft~.
I want a 512x512 pixels image. Magnitudes will be coded into the red component/plane and phases into the green component/plane.
My first issue is to have the FFT settings right to get the correct amount of data. To match the matrix size, I need 512 frames of 512 bands. So I start with a buffer of 512 frames of 1024 samples (supposing that only the positive half of the spectrum will be returned), that is 524288 samples. Therefore, in fluid.bufstft~, I use the @fftsettings 1024 1024 512 (I know that with the Hanning window it might not be the best thing to have hop size = window size, but this allows me to get a longer sound).
However, the resulting output buffers have dimensions which appear weird to me:
They have 513 channels instead of 512. What it this 513rd channel? What is it used for?
The length is 525312, which corresponds to 513 * 1024. 513, you again!
The second issue is related to the way the data are organized in the output buffers for magnitudes and phases : if I am correct, each channel matches a channel in the FFT. And the duration matches the number of frames. So, each frame is split into all the channels, linked by the position - however with the aforementioned numbers, I am not so sure. Can someone confirm that I am correct?
Another issue: with so many layers, it’s not possible to use jit.buffer~ for a translation into Jitter matrixes. The object is limited to 32 channels.
So I am planning to do some JS to convert each output buffer into a single-channel buffer with all the frames in series (that’s some kind of time multiplexing like inside pfft~). But if there’s some obscure external which can do that, please let me know!
So, a bit of STFT/FFT explanation. If you know any of this, please skip it and do not feel patronized - it might help others with similar questions.
First, I presume you have read the fantastic resource prepared by @tedmoorehere so you know about windowing and STFT being a lot of FFTs windowed in time.
Second, why 513 values? It comes down to the conversion post-FFT: once we convert what FFT gives back, we have a lot of redundancy. In effect, we have 3 types of values: for a 1024 FFT frame size, we have 1024 frames of 2d (real-imaginary, cartesian values)
Frame 0 - the DC component
Frames 1 to 511, and 513 to 1024 - the real-imaginary components
frame 512 - the Nyquist component
The type 2 above, are redundant - the 1 to 511 is the same as 513 to 1023 (just flipped).
So most software, when converting from real-imaginary to magnitude and phase, will just take frame 0’s mag, append 1 to 511 converted (cartesian to polar), and this gives you 512 values of magnitudes and 512 values of phases (with DC phase always 0). They just scrap the Nyquist value.
That made us sad. so we give it to you. It is more rigorous and in certain processes changes how the algorithm will behave and such things.
The good news is that you can just scrap it: just ignore it if you don’t need it. Which leads me to your 2nd question:
indeed, each channel is a ‘bin’ in time. Channel 0 is the DC magnitude, channel 1 is bin 1, etc… up to channel 512 being bin 512, the one you want to ignore if you don’t care about the Nyquist magnitude.
you can also do that with the fantastic fluid.bufcompose - or you can spit out one frame at a time with fluid.bufflatten @numframes 1 and iterated with @startframe… again, some fantastic resources designed, this time, by @jamesbradbury
They help visualize what these powerful objects do. You could also scrap the 513th bin (512th zero counting) at the same time with these buffer manipulation tools.
This Nyquist component seems a bit weird to me. I thought the last band in FFT was ending at the Nyquist frequency, not being occupied by the Nyquist frequency specifically. But as there’s usually nothing of importance in the very upper end of the spectrum, I’ll happily remove the last band to go down to the required 512.
Now, let’s dive into fluid.bufcompose and fluid.bufflatten…
As I was already in the process of building a patch without any JS code, I went on with the attached patcher.
I still got a puzzling number of samples after having flattened the buffers coming from the analysis.
Also, I am not a Jitter specialist but going 100% with regular objects seems to be quite slow. Moreover, I cannot fill my matrix completely, I got only something like 20% filled.
all our buffer analysis objects apply padding by default. This is to do with making sure the first and last hopsize worth samples get analysed fully (due to the windowing). Just turn it off with @padding 0 and you get the number of frames you expect
your translation to jit.matrix was slow primarily because of using counter and a feedback loop to iterate. This is almost never a better idea than using uzi. Because you were using delay to try and stablize things, not only did this add considerable time to each iteration of the loop, but also accounts for the missing frames due to thread swaps (delay always executes on the scheduler thread if overdrive is on, but jitter always executes on the main thread)
Below is a version that seems to work as you hope. There’s room to make it simpler, I think, using fluid.bufselect rather than bufflatten.
Couple of queries:
Your fft settings are, in effect, without overlap (window and hop of 1024), because they’re in the box as 1024 1024 512. The last number is the fft size, and this will automatically be bumped up to the minimum need to support the entered window size (i.e. 1024)
Presumably putting the mags into one image channel and phases another is for export, rather than display? I can’t imagine that the phases will ever look especially suggestive
Thanks for making this patcher working as expected! It’s great to know that it can be done without JS.
I am quite surprised about uzi doing the job because usually I use counter+delay precisely because uzi is not compatible with complex patches. I wished C74 provided more examples on how to deal with threads, scheduler, etc because despite having read the main paper on the topic, the subject sometimes remains obscure to me (especially in a patcher like this one where you both have MSP and Jitter objects). But I had never thought about avoiding thread swapping. Will remember that!
Indeed, putting magnitudes and phases in different channels is for export purposes.
In between, I have checked the JS code from James Bradbury and have improved it. Also, it made me programming the reverse operation (picture to buffers) in JS too. It’s almost done!
I thought I grasped the fluid.stft~ output but now I realize I still don’t. Numbers don’t add up.
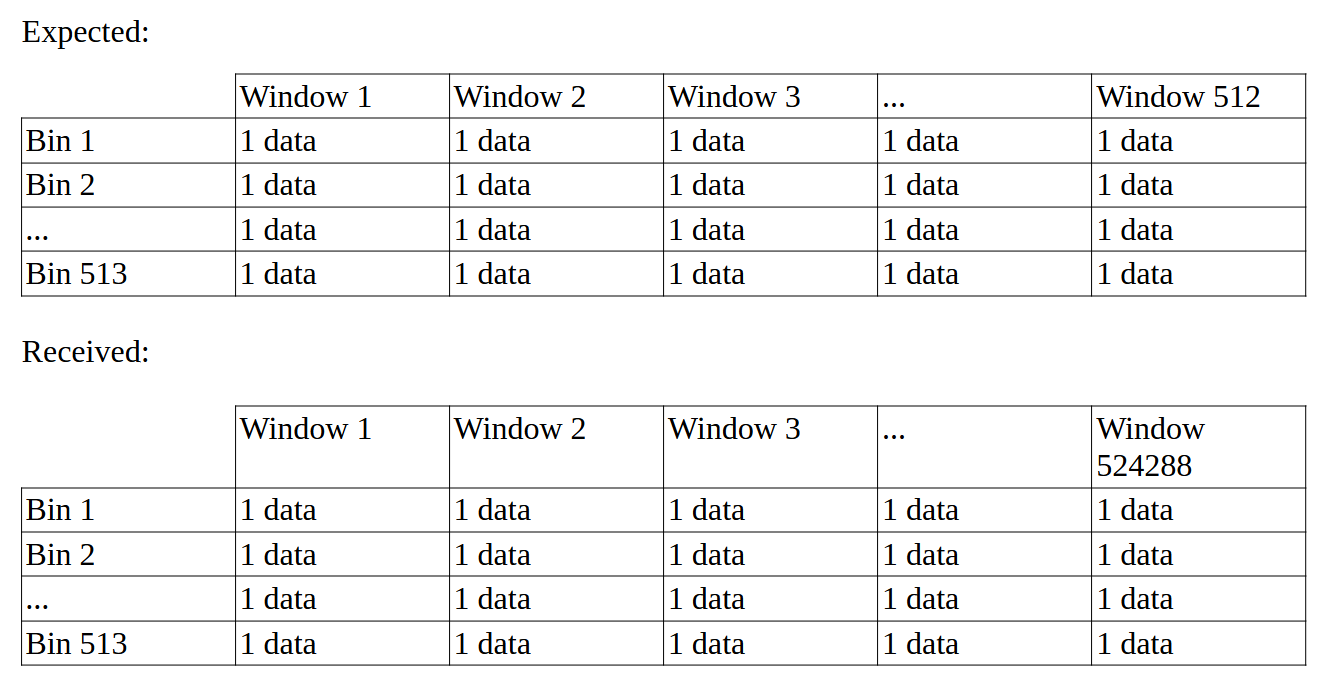
If my buffer has a length of 524288 samples and I perform an FFT of 1024 samples with a full-window hop-size and without padding, why do I have 513 times 524 288 samples at the output, that is 268 959 744 data whereas I was expecting only 513 * 1024, that is 525 312.
I understand the 513 channels, that’s because of the Nyquist band. But why do we keep the same length on the output buffers as on the input buffer??? It’s as if there were no windowing, which is supposed to reduce the number of samples to a -smaller- amount of windows.
Here are two tables summarizing what is puzzling me:
Amen to there being better information about this: it’s the bit of the Max / PD abstraction that’s most consistently leaky, insofar as people run into problems with it all the time. IMO, uzi is almost always the right choice, but – as with any iteration in Max – it requires some care about threading in order to keep the order of execution unsurprising:
uzi will always execute on the thread that it’s triggered from, so a leading defer can be needed if you know that all the work needs to happen on the main thread (as with jitter)
correspondingly, you need to make sure that there aren’t accidental thread changes in the ‘loop body’ (so, avoiding objects that ‘promote’ off the main thread or vice versa), otherwise using the middle outlet to signal that work is complete will be unreliable
none of which means that it’s still not possible to overflow the Max scheduler with really complex workloads. Sometimes, in that case, the only option really is to use a counter + feedback set up, but this will always be slower, and all the same caveats apply. Although, I’d generally try and avoid that by refactoring the workload and staying with uzi where possible
I don’t quite follow. Which of your output buffers in that patch are you looking at?
input_mag, which is what fluid.bufstft~ writes to has 512 frames and 513 channels (with @padding 0). Is that not what is expected?
Here’s a version that uses the @numchans, @numframes, @startframe attributes of bufflatten in the matrix filling subpatch, instead of doing one big flatten and then having to unravel it (so, essentially, it does the annoying counting for you, and cuts down on data copying). Turned out that using fluid.bufflatten this way was ergonomically better than fluid.bufselect in this instance
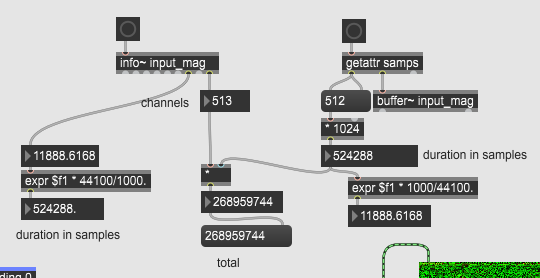
The literal size of input_mag – the number of total samples it contains – is
channels * samps
=> 513 * 512 = 262656.
This is a little over 524588 / 2 because of the nyquist bin.
What I don’t understand is why you multiply the product of the number of windows with the hop size (which gets you, reassuringly back to the duration of the source) by the number of channels. All this tells you is that if you had a 513 channel file at the same sample rate as the source, then it would be <whatever that large number is>.
I try to make sense of the contradiction between the data sources :
indeed gettatr reports a duration of 512 samples but I’ve never used this type of query so…
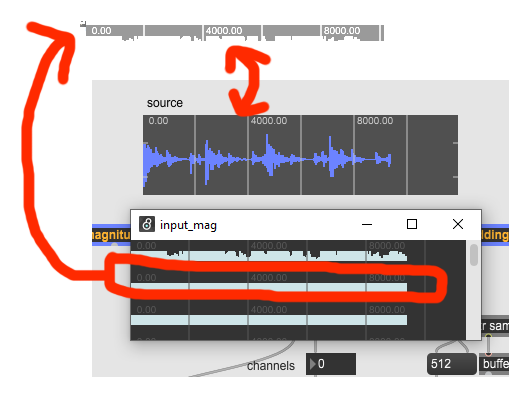
when info~, which I use quite often, reports a duration of 524588 for the same buffer, I am more inclinated to believe it
also : if you double click on the input_mag or input_faz buffer~, the timeline (in ms) duration matches the duration of the input buffer~, so it supports the idea that these buffers have all the same duration (it’s very hard to see it so I’ve duplicated the timeline of the input_mag in my picture editor and have increased the contrast to make it readable).
The value returned by the @samps attribute is the ground truth: i.e. the literal number of frames in the buffer, and this is what max stores. When you use info~ or look at the ruler in waveform~ then the figure you see in milliseconds is calculated using the samps attribute value and the sample rate of the buffer~.
All our descriptor objects adjust the sample rate of output buffer~s so that they’re accurate: generally source sample rate / hop size. As such, if you then look at one of those buffers in waveform~ or whatever, the duration you see should indeed match the source’s.
I’d send a demo patch, but I’ve currently got Max paused in a debugger Try checking the sample rate outlet of info~ for one of the output buffers: it should be a lowish number (like 40-something if your source is 44k and your hop is 1024)…
and to add to this: that sample rate is right: it is the rate at which that sample needs to be played at to be at the right speed, one hop at a time. I think that @jamesbradbury has a demo patch of that somewhere…