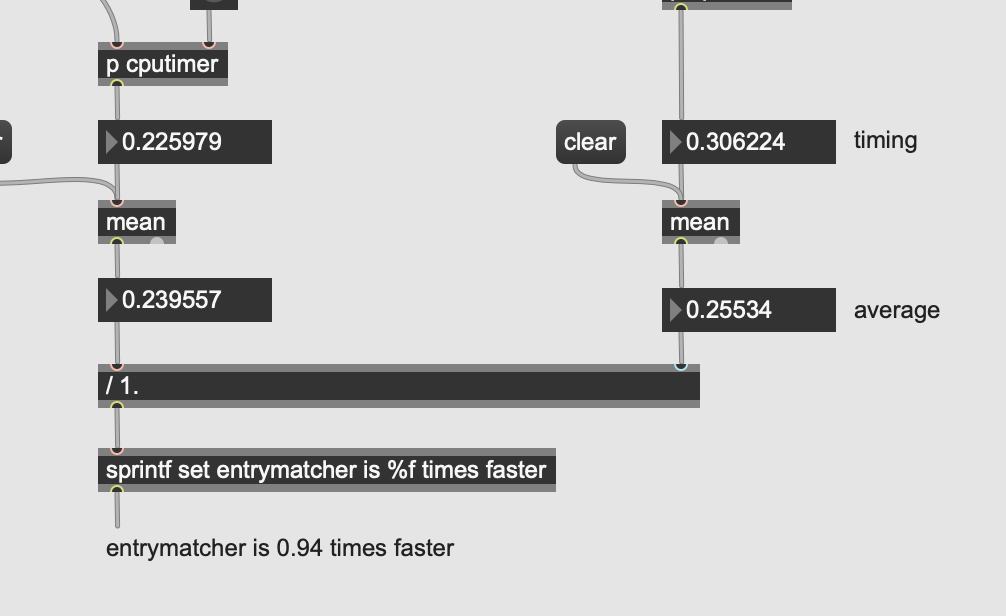
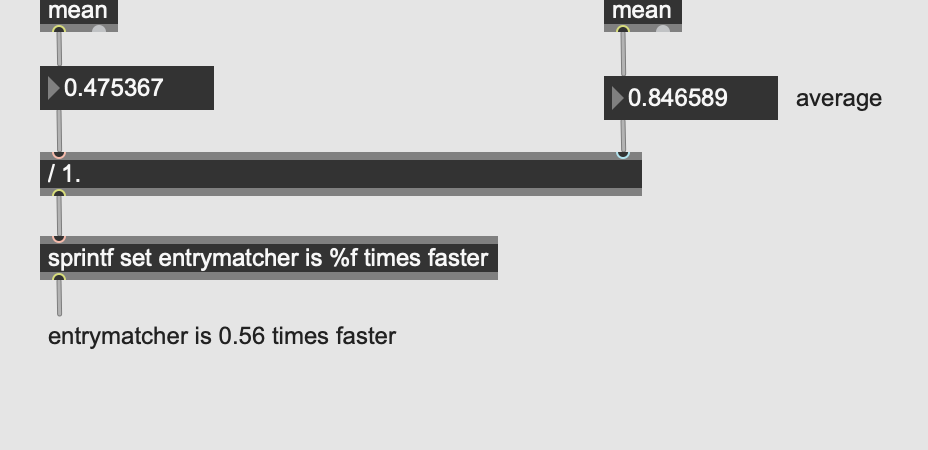
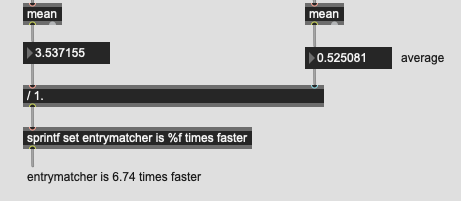
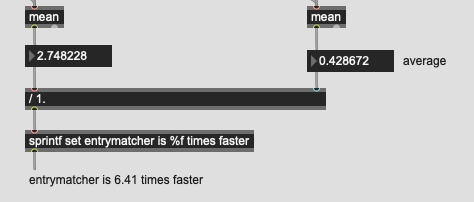
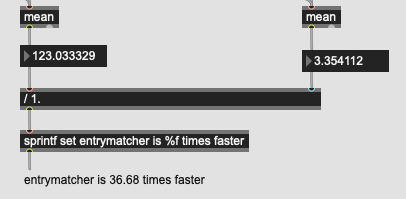
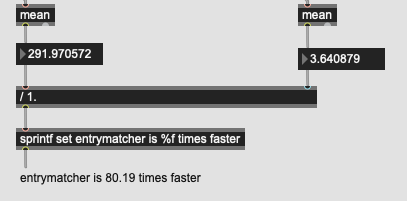
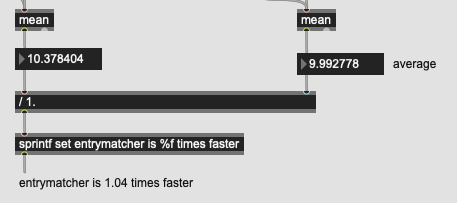
As stated above, I understand very well what you are trying to do, it is not far from where I come from… you saw and was inspired by Sandbox#3 after all  Take for granted that we hear your bottleneck in your use-case and that the copying of dataset might not even be the bottleneck, since optimisation require thorough profiling which will happen in due time.
Take for granted that we hear your bottleneck in your use-case and that the copying of dataset might not even be the bottleneck, since optimisation require thorough profiling which will happen in due time.
So for now, and for everyone’s benefit including yours I hope, as it opens a lot of other potentially exciting options, let me focus on the toolbox design decisions vs “black boxing” the process, and the advantages of both.
First, let me say that blackbox is a wrong metaphor. It is more about how opened or closed an interface is. Both have advantages. For the rest of this message, the tltr is: if entrymatcher works for you, or any other querying object, keep on using it for now if speed is what you need most. If you want to understand its limits and why we do not do it that way and what a more granular interface offers, keep on reading.
The long version:
When we do query on a dataset, we have various consecutive processes to do on the said dataset that require it to be reliable in shape or form for the said sub-processes to be valid. Sorting, adding, pruning, querying are all destructive edits to the dataset integrity in the memory space. There are ways around this. An all-in-one approach can get away with doing them if all of them are within a single ‘blackbox’ object, but if one wants to explore the various subprocess impact, either by changing the type of process or their order (or many other options, see below) one needs to create a granularity of such processes.
To illustrate this, I will provide a clear example not far from your intention: a simple query that has many conditions.
Here is a dataset of 10000 items with loudness, pitch and centroid, give me the nearest item where loudness is within 6dB, pitch within a semitones, and centroid is within an octave.
This in effect needs to have
1 - a dataset at a given moment
2 - sieve it with absolute masks to reject the items not fulfilling the conditions
3 - sort the remaining items (if any) by calculating distance in a certain way (sorting or else)
To allow to change stuff in there (the order, the conditions, the dataset itself, etc), one need to know the state of each element. The all-in-one approach has that advantage. If you add an item to any of those, or renumber, or sort, the object will know and this can be made fast. This might be the desired behaviour when the order of tasks is known and curated: you can trust that the things you point at yours only.
Now, if we separate the tasks, we lose such advantages, but we gain other advantages for musicianly investigations of data mining. For instance, in the same workflow above, here are a few ideas that are possible to try:
step 1 (aka dataset at a given moment)
1a. the same datasets can be used in many other tasks/processes (see the whole list of algorithm available)
1b. subdatasets can be pre-processed independently, removing outliers, scaling, extracting features, clustering, trending, etc
step 2 and step 3 can be swapped (you can do that in entrymatcher by changing the order of the query IIRC)
step 2 and step 3 can do conditional queries in programmatic ways. For instance:
2: Give me all items within a semi-tone. if none, make it a tone (or use centroid).
2: Give me all items with pitch confidence high, within a semitone. Depending on results, give me more or less tolerance
3: give me all items within a given euclidian distance (after you have normalised/standardised/reobustscaled them) then give me the one that has the nearest pitch only
3: give me only the 10 nearest items, then check with binary masks (#2) if any are within the tolerance.
Forking: if my query has high pitch confidence, give me material within a semitone (binary) then the nearest timbre. Then I will pitch- and loudness- correct the entry I’m given
Class: take that timbral space, make 100 classes. Sort them by their centroid. Then give me the nearest match with the timbral class is the same +/- 1, etc etc
MLP: find trends in the timbral space by using an autoencoder and shrinking it to 2d.
step 3: kdtree can be replaced by brute force sorting, or just sorting on one dimension, or whatever else.
I could go on for ages. These are possible in realtime at the moment with our interface, but not just-in-time at press-roll speed yet since we want to sort interface questions, then optimise. We are aware that there are improvements in how to make the workflow of how we move around these queries at the moment too.
Even more fun is possible now: one can experiment with all that data preprocessing and feed it to entrymatcher. Or one could try the order swapping in non-real-time with AudioGuide then code the workflow more dynamically to tweak in FluidLand. The granularity and json/dict interface allows for this. You can even do an entrymatcher sorter for more involved query down the line. The limits are quite endless (apart for my diary)
I hope this opens up possibilities of programmatic corpus manipulation/query for you. After all, I feel you are trying to find musical context for things and maybe there are other ways than single transient analysis.
p