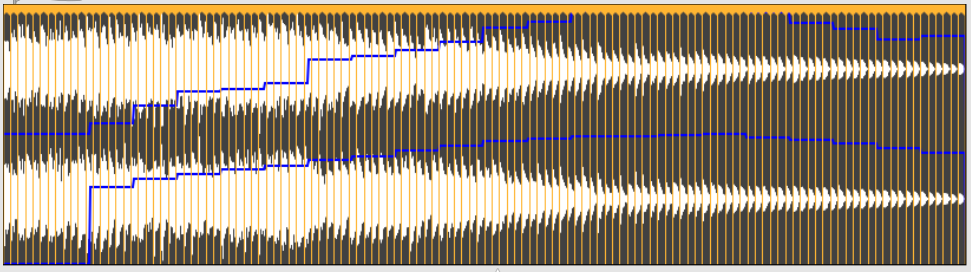
In your patch the buffer that you’re plotting on top of the waveform – pitch – appears to be the result of a single analysis, not the overall pitches for everything. So, whilst it’s clearly struggling to sort by the pitches we hear, that plot isn’t helping to reason about why (globally).
is pitch analysis still such a difficult task in 2023?
It is! I mean, the two useful algorithms in fluid.pitch are pretty old – yinfft is from 2006, and hps is from 1969 – but I’m not aware of anything that’s ‘solved’ the problems of pitch detection meanwhile. It’s hard because the ways that people resolve pitch isn’t fully understood, but is pretty complex: people appear to be able to draw on different forms of ‘evidence’ in auditory perception, and our attention and cultured history of listening also play a role. There’s a good discussion of the physiology / psychology in Rick Lyon’s Human and Machine Hearing, but I don’t have a reference for the social-cultural aspects off the top of my head.
Meanwhile, most pitch tracking algorithms approach the problem in terms of trying to estimate periodicity and (sometimes) trying to combine that with some harmonic analysis of the spectrum. The latter of these is quite error prone in a (discrete) FFT setting (sometimes constant Q transforms work better). Meanwhile, reliable periodicity analysis on real signals turns out to be really hard because most things are only quasi periodic, and things like autocorrelation measures are very easily confounded by harmonics etc.
The sounds in your corpus are both very short and quite inharmonic (especially in the lower registers), neither of which is going to make things easier.
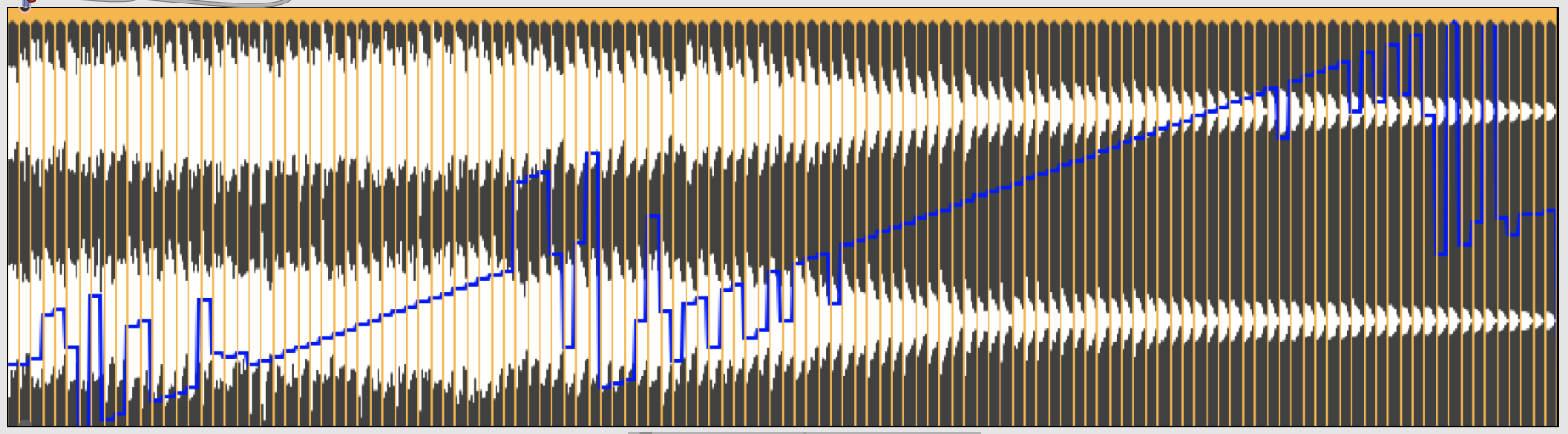
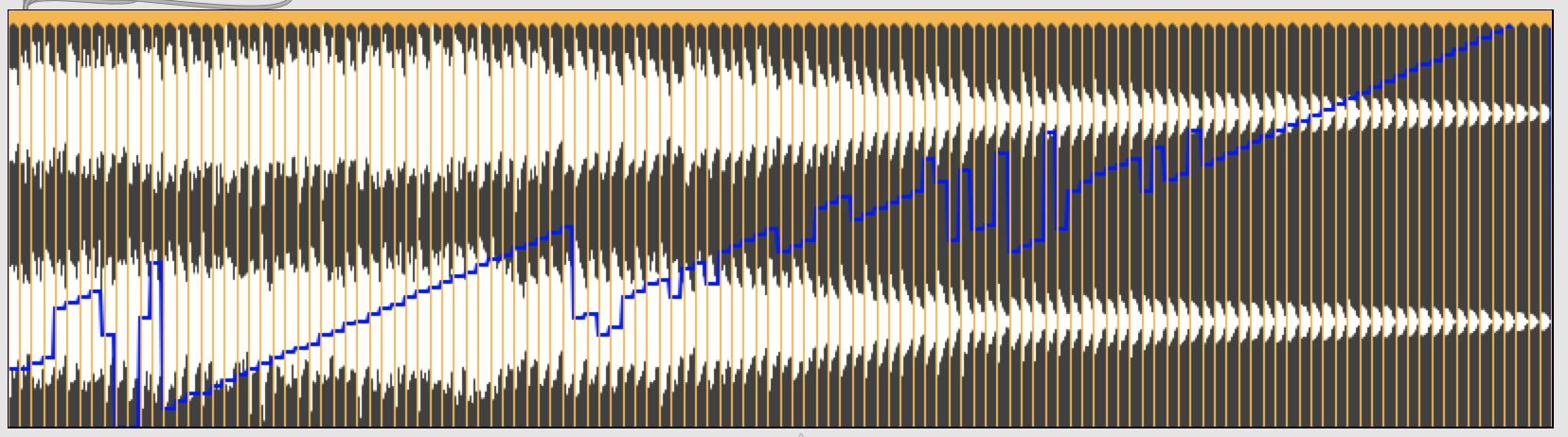
Using @unit 1 to output MIDI note numbers, and taking the median over slices, here’s the overall trajectory with
- YinFFT
- HPS
Both have similar pathologies. They struggle with the very lowest notes (probably a function of the duration: lower frequencies take longer to resolve (and need a nice big window). Then there’s the same sudden shift about a third of the way up (which is probably an octave shift?). HPS then falls apart for a while, but does ok (or at least, is consistent) at the top, whereas YinFFT falls apart for the highest values.
What I’d suggest to try and work out some settings that work across the range is to audition with the real-time fluid.pitch and the sounds looping (if they can). It might just be that 11025 samples is insufficient (given that each sound also has an onset transient). It might also be that to deal with the extreme ends of the range, different settings are called for.