So I’m loving the 10b example! This is exactly the kind of thing that @weefuzzy helped me with ages ago that would take some kind of centile, then a mean of that, etc… The new approach works worlds better though.
I’ve gone and made a reduced version of the patch to test this with a bunch of sounds that I think are problematic.
First, a couple of questions/thoughts.
/////////////////////////////////////////////////////////////////////////////////////////////////////////////
Is the idea with this ‘newschool’ approach of removing entries via fluid.bufthresh~ that when you have a descriptor space, you literally ignore queries that check for pitch if there is no valid entry?
I’ll rephrase that as an example. Say I have a corpus of sounds, and 10% of them have no valid pitch data (via getting zeroed out by fluid.bufthresh~ when creating a fluid.dataset~). I am now feeding it live audio and want to query based on loudness, timbre, and pitch. Will all the ones with no pitch data get completely ignored?
Similar question for the input side. Say my input frame has no valid pitch data, but everything in my corpus does. Will that return no data?
(Obviously code is code, and one can make these decisions, I’m just generally asking about the paradigm/intention of having intentionally malformed entries)
/////////////////////////////////////////////////////////////////////////////////////////////////////////////
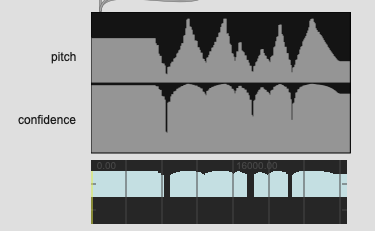
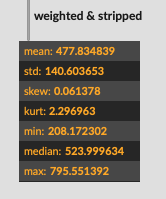
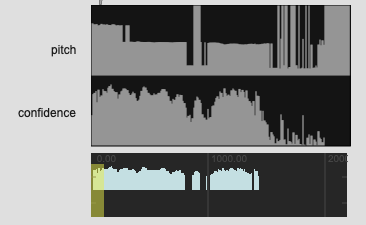
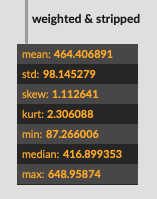
The reason I’m asking is because with some of my examples (code and audio below), there isn’t great pitch data, but sometimes there still is pitch data. So I was thinking of taking stats for the confidence and finding the max of that, and then adjusting threshold based on that (and perhaps std). So basically trying to get the “best” pitch information out of that frame.
Where I can see this being problematic is the “best pitch” for that segment may actually be shit as compared to another entry in a dataset which may have the same final number(s).
Perhaps a solution to this would be having a summary confidence statistic. A straight mean would be shit for lots of reasons, but perhaps something like what % of the length is above the given threshold. If it’s 5% (or 0.05) then I know that even though I have the most representative pitch from that sample, I have a low confidence that it is in fact that pitch.
This confidence-confidence (would that be a derivative of confidence, or is that specifically limited to change-over-time) would be a metadata-esque value that can be used in the query but not in an LPT descriptor space.
/////////////////////////////////////////////////////////////////////////////////////////////////////////////
This one is a more technical question.
Harmonics…
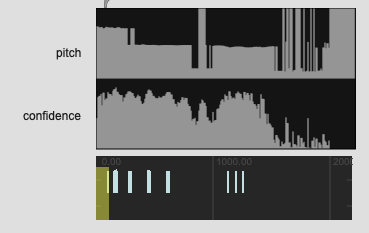
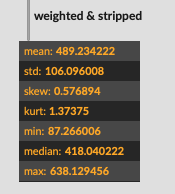
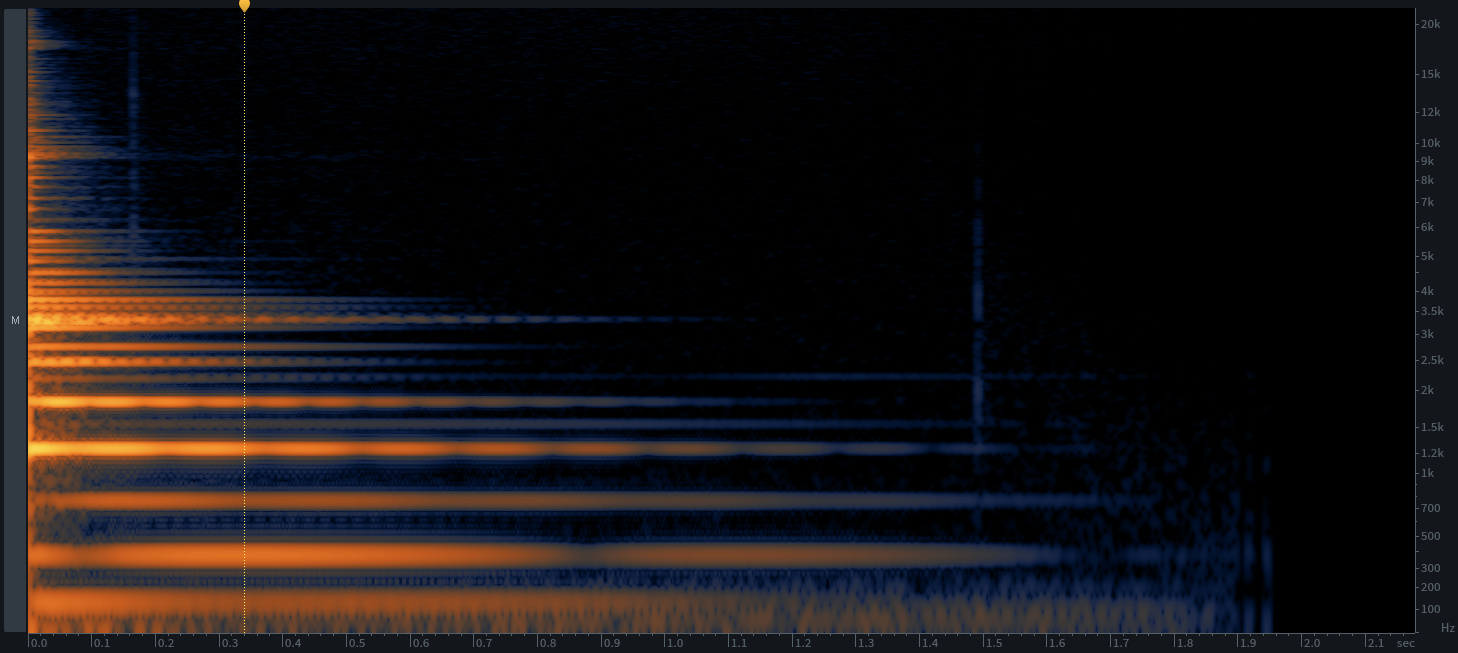
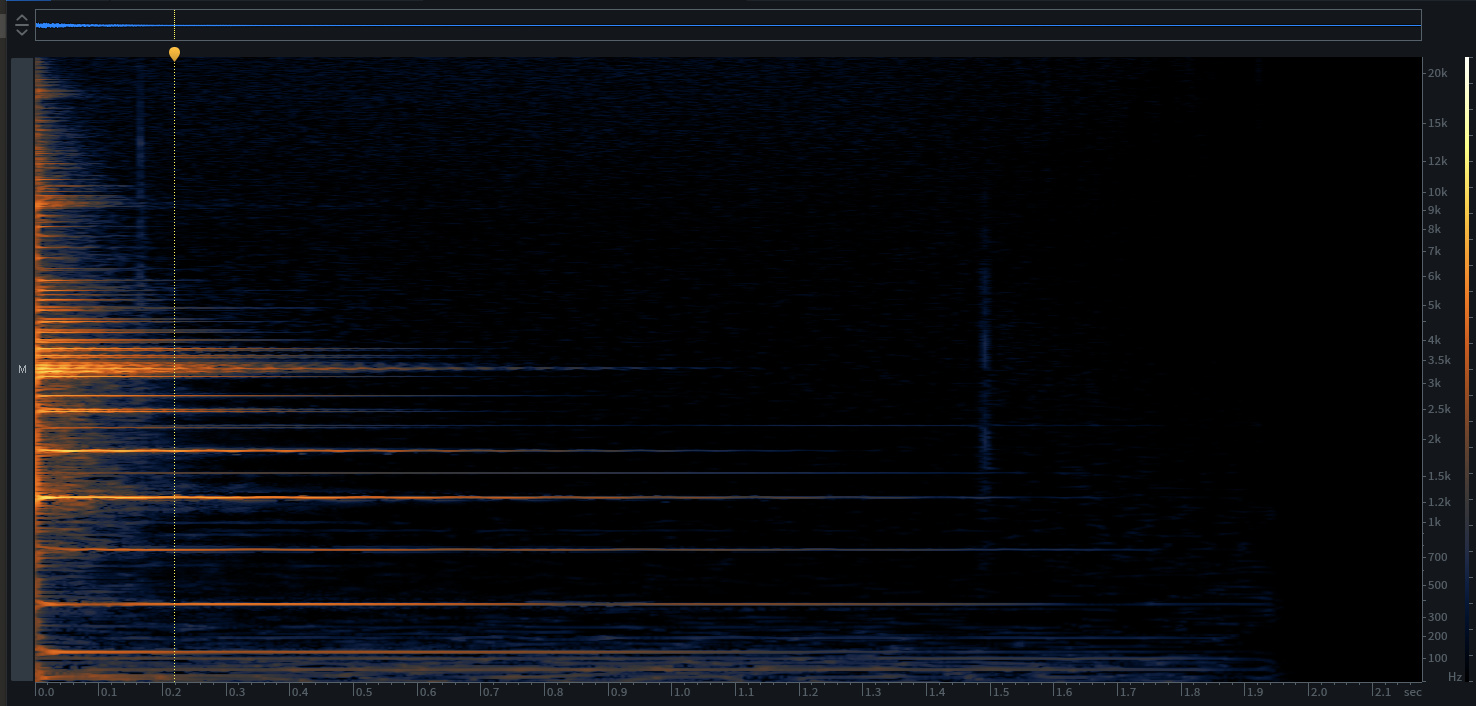
I’ve gotten mixed results with this so far, so I’m thinking it might be an even/odd harmonic thing as some of the metal sounds I’m testing with have funky harmonic structures.
I guess this comes down to the underlying algorithm, but when averaged over time, or more specifically, when taking confidence as a weighting factor, it may decide that what it hears as a harmonic is more confidently heard than a fundamental. So almost the opposite problem that could arise if doing loudness-weighted pitch analysis.
A similar thing would potentially be the case if there are multiple pitches (or a gliss?) within the analysis window. The confidence may be high for many of those pitches, and a mean may produce a…well, mean value which may not actually be in the set of pitches.
For all my tested in my example I’m using median to hopefully mitigate against that, but the problem still stands.
So is there a way to perhaps balance loudness and confidence to get at the fundamental?
Or perhaps does the YIN (or other?) algorithms spit out a list of harmonic peaks, and then that could be weighed in together with the harmonics.
/////////////////////////////////////////////////////////////////////////////////////////////////////////////
Ok, enough chat. Here’s the code example:
----------begin_max5_patcher----------
2165.3oc4asraiaCEccxWAgPQWT3Jv2TLqxxtn+ACJFnHS6nLxRFRx4wLn4a
ujTOhcr7XJYJiAnAH1NzR5xy4d48EY9ws2D7Pwqpp.vcfu.t4leb6M2XGxLv
Ms+8MAaheMIKtxdYAIEa1nxqCVz7c0pWqsiSBAayheCjVCdHN4ace+ph7573
MJ607WprmU0oIw6+sqhSreKpcr7caRyyT0U6O3135jGSyW+0RURcyzkIiBgK
.LJ07FhBMug4gPv+r2SuJ861mN1708BnXWcmD5FMcocJV7vS+IGEXF6eu8Vy
KKtPhAGpIj70f5BPbdb1a54yryMRogLn1WwPl+XFnOYFTHH4wcIeCrJMSUAR
yAOpJuBrClgLLBGS7M+vjSgedI9Y0phxMu2AtG1sZkprG7aS0PH7EU55G0Rd
HvxNMXivxvHBgPITo8GFaAfDwBERIRRoPBQxkRtlAXbKsP2iHNDw71QaFp9s
spFYDrJqHVqe+oeHKsx9dP+CeehiMEhKW8h9lOxtRKwkaTUUfm+dQwFfV+Ag
H.JLXrqhHhPDmyYbFz9CUScHINDhDPbjPFQfHJinGjgs1P3SRcnSQcCSGdcc
VikiZI32AU0koa2pVN3hr+NttvGquDTKswgc+Hz9hzK1jTMmg3PFTxnRpl1P
BKsgNIsMvZLDSLExYYZRc3yopWFqU.25kfxjgFsOF0DsYTSYAdecRRQVQYyy
19vfgBnLBRjXDiGwwByPHIGJhnDDQf0j0BfUf9aMhkN1pCTC1nhyuSaXrT+x
2TubG3a6JquCnIG8KpkoluU+DuaPdSbNdSipP5m06XgXpKWLy6zh73x2Fbgi
f3Q+H6xepPGTRLMKFhNwjHAQJIZGGXJGa7dPvvyf7nS5nXwO42A4B5kyEOG+
QXnUY6RWFpiMgMtx+B4eNhvN7J.22DGCzD+ppNttJryWT3m8DMNxEKEg3iBf
IHd0KLmOEBrtX85LUvn8YBONLMKBFhQhH8nRpDRoLsuArMeWLc7fLUGaXHbR
kA8SrRs1tVU9UUd7CY1aD5uETqiqUuOHyfGIyzl6FGNUEdU5Zcx3CSGSJ9h5
6KiS7D3DHSrFJqIvyXhzP4dz+2e7tIPzngTDZHKY7wVxzYQ64yLISdKIaBVr
Cx.5vAGy.j4fAnWO6WVjsFSNWFJvZjo8XoSWQHnhIZ+Rtdtbam6Lgrygpmcq
huRtUM8c48llKTkVAtOqnXK.MQ5n0yJhbtJZvmwzTmVhouGCSMyR8MyZQMTh
s53AqblEMkxX3W0xXnHq2VJL534+zppgK+eXUMszHgQGJ+yYqrF3u.k0zAcs
Chi6cjjc8pqAMq00ftn5ZlHoNb8LXgWqmgH8nUTOmXw+6f6qJ1UlnZHE8eYF
cPFBbeamLAmuulmuNPHNDQkLo.CQbYDUFo8wQOWrKxo3MaDq86Z4vDIdNHx5
GKUUOdDStTUUmlGabObHiAtu4NJxVpcsFY47R82GmO9f+MrIR6UioycSFwgP
MWhMtnom0q1kxlQ+JXV12PhSXeBt2.uTUYUxt5hUqzgtXSzlkNPxxLIZdYYt
vmobkTjuJcoJOY7M5fgGX+HzIWcj6OdicGbTcZU5STZM.FM.0YHdD.Msl5H.
RnS.fSZwhY2PhWqNBfUp58ikM1p+FbukFbCRhn9MR1jJx+opcoiUaNHDwDwP
aelLTeg5baa20iH4OOk5NoZ18yiSFwjie3S8gEcjWD9tjyG1UWWjOMGcL3kU
X8IKejPtRUV2qMrKO9HZxG0ZuREWuSGEFLIeEsgcgMd53x4MD.1mtNJUayzk
RC9sQ2fPRSe+DZ2ellcx7pmgI4dbYYwVypvwp9ZQBmaQhzZnyPiuiImNn8Ln
wFq5By46ARZjecj6wT+ZhjsWivPZmviUk1hVcRYMa2KYpcAqeo3I8hMoxXiq
qKGeTLFFexpkPLWaCuQ1My9CxDdbgnPWQX2t9r0+5D.ZeAViDi3Yvr1q6hZj
r0yE73Skg11X9L5wxYiZlXiDZoBVjcS2PH4LB9nqjcwTMGz0hX3.FaF4.5bw
ASUwSIFPKlQLiN.y1qHHKM+yG7V6bzL9gDQSNmsBqsgIK.eLM2qAQ6eQ3lKZ
Px1UIgvtHoHOHoqlfDT8CgcFIQoGLcJJWpJOcoEtJZFzEPJ7.H4BWjDaN.oo
1ryJZeXaRbwj4SDQOFQyO8x4ygn0oO4NpuHI4hSFjuVPdNAIH9RRHWjDxGRB
6hjv9PRDWjDwGRh5hjnWCWzVIw78xKqn4tHZ9kBRW7SJ7giRgKtLDPeIIjKR
B4CIgcQRXeHIhKRh3CIQcQRTeHIlKRh4CIwcQRW75IWRtxbjUt7jq3trdh5C
I4ff7QNwToCBh5ijJntj4DcVxbxcQi7cNwTlq76k5Wj5RxTcSmKSRtj9M0GQ
UntrxlRlEaFmEs2sYHtrlT3iDvIrqUYoNUx1m.tunyIUMSSqZh2t8YUYU6Ea
EQvl3mZNti1y0Vvlz7l+z1uofR0yocWu8eZxf3xjGSqUIlMKz1WnW4zflasP
Cv7cosVqZvoEYU8aYet8P86Q7l3W4l1kYAiFKqh2kUeH96OQleMM2L2aoBXy
Iyr6k82ppGV+4Sv4Gu.C+HYg3jDU99m1SXXj4JhLmzSd+49jdvY6bQqtpTeq
VnYwQK.1nm8ocZ380sG.XaK89YP9foDESXXoY1zcRSggXAkg78z5fMaye5hU
oYY8.5l9mk9g012wf0kwKS+3PqzheTuNw7Ofo8L2d7m1STs2Ft61DQQZlawf
e53aq6tvRHRZ08jVcu4S5gPe5thyW2PxXQ++U0ZEPYw1hxtEi5aU1e86pK5A
ZmOflEmmT8c3pC2zhM8z0YqKqNipMqfX6mrmy4IaY03jw1qayjpZa6IT21R7
a+2a+OLaTE4G
-----------end_max5_patcher-----------
And here are a handful of files that I’ve picked that show off different problems I’ve talked about.
examples.zip (856.3 KB)