if you read my 4 point example carefully, until the maths make sense to you, then you’ll see that smaller scale make smaller distance for that dimension and therefore will narrow its range and therefore will make it ‘more important’
but
indeed when you have many dimensions with real, noisy signal, that dimension will always seem very near so if you have huge variations on other dimensions they will seem to have more impact on the change…
I recommend you try real data that you can understand in 2d. pitch and loudness for instance, and try to control the matching. You’ll find out that it works. with more dims, all of different scales to start with, where 1 doesn’t equal 1, you are getting so many problems.
I also recommend trying catart with that ‘feature’ to see how it works ‘as well’ - it is now in the package manager. just to test and see if you get the feel you expect, that is.
I’ve read it and understood it (as far as I can tell).
This toy example is to verify what I’m experiencing with real analysis data. When I make the dimensions big, it matches that descriptor more closely (perceptually). In my realworld example I am replacing the pitch column from incoming drum analysis with a sequence of notes and then matching in a (pitchy) corpus with that. If I increase the dimension size, I start hearing the correlation as I would think I would.
The fake example (in the video above) confirms this.
Here’s the realworld comparison:
In both real and isolated/fake tests, having larger values makes differences in the corresponding columns matter more in the distance matching. Perhaps we are not using “more important” in the same way.
The way that I’m wanting to do it is this realworld example where I want to make it so a certain column (or columns) matter more in the distance matching. In this example making it so the most important feature being matched is the pitch one.
Until you have a 2d real-world behaviour that works, where 1=1, I will wait. There is too much noise in HD - as you know for the many times we discussed the ‘curse of dimensionality’ for instance.
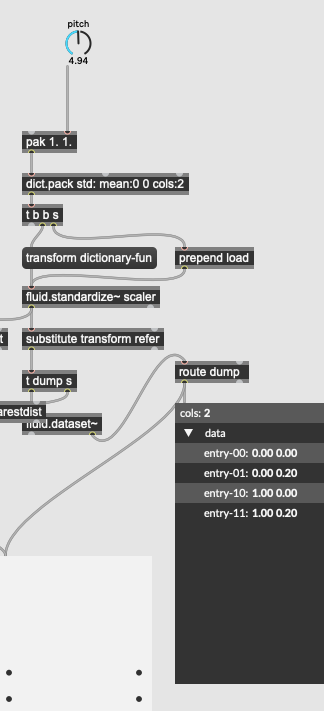
actually, I will spell it out now as you will chase ghosts. you are forgetting to scale the query too, via transformpoint. This explains the strange behaviour you get.
so if you scale up by 10x the 2nd dim as you do (div by 10 under the hood), doing the same to your query point is needed. you can either do it via transformpoint which handles the maths to match the kdtree’d scaled DS, or do it at the query (but divid by 10 there)
What I’m not doing is scaling the original dataset as I fit a scaled one for the comparison but then getpoint the original dataset for comparison.
So I’m scaling both the queried dataset and the buffer going into it.
edit:
I’m doing it manually (with multiply) since it’s just a single point (and not a dataset). In both cases the values being compared are 10x, for the dataset being done with transform since it’s a ton of values, but for the input just being done numerically.
i can see that, but it doesn’t behave like my sc code, so there is a problem in your thinking. if you make 4 points, do you get what you want like I do? doing 100 random points is just confusing.
do 4 points, midicents and db. like 60 -60 / 72 -60 / 60 -48 / 72 -48
query the mid point, ish (like a Eb (63) at -57dB)
mess with the pitch weight. see if you get the behaviour you expect. now this assumes 1dB = 1semitone but that is less bad than mfccs in 13d anyway.
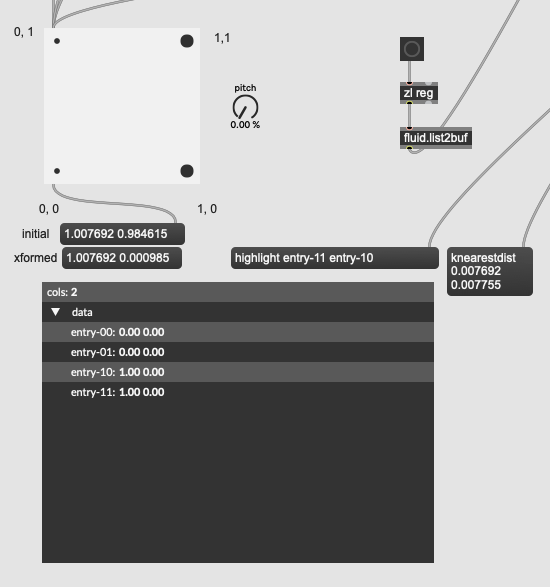
The nearest match in the second column is still 0, and the first column still matches as a 1 as that is closest in both.
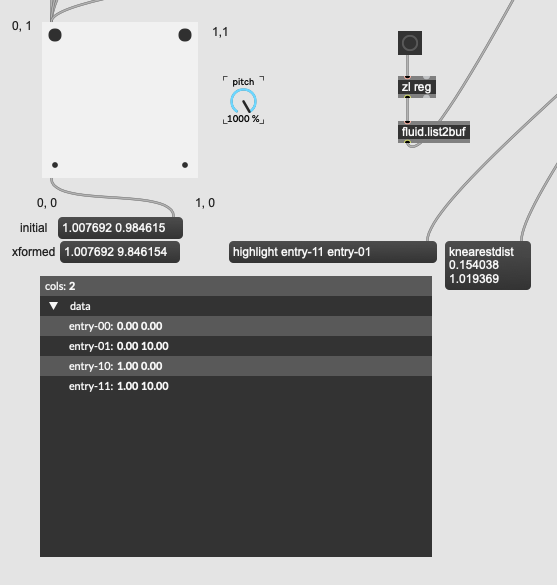
However, if I scale the values up to make them large, I now get the nearest matches of [1, 10] and [0, 10] (entry-11, entry-01), meaning that the large 2nd dimension overpowers the distance in the first column:
This fits with my expectations (and synthetic/realworld examples above) where even though the distance in the first column is larger, the distance matching cares less and overrides the identical match in that column opting for the 0 match there.
It’s worth mentioning that it gets confusing with the 0011 approach since the closest match never changes.
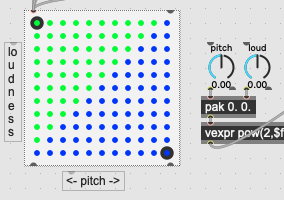
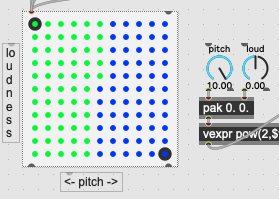
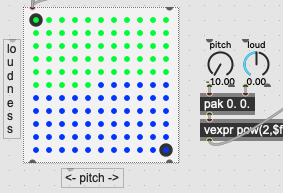
we can see that most of the space between the 4 dots will be separated on the X axis, so it means the Y (pitch) is less important, with a large number at the top (and smaller distances on that axis)
(sigh again)
I’m making a Fiebrink-style visualiser now to visualise it all. watch this space
arghhhhhh I’m so confused now. Why isn’t the first NN the right one post-scaling is where it is wrong. but I don’t know why yet. there is something fishy.
for me, if I cannot make sense of 4 points in 2d, I keep on trucking on the maths. There is something wrong in my reasoning here… but I’ll get to the bottom of it.
ok i remembered a similar issue when we thought there was a bug in KNNRegressor, years ago. And also discussions about distances when we taught them.
Obviously, large scales are more important than short scales.
equidistant toy examples are dangerous without real-world reasoning.
#1 is clear when we spoke about the problem of MFCCs normalising. Not normalising means lower, wider range have more weight then they should, but normalising gives details too much importance. Even more when using derivatives.
#2 is even simpler - I just had to find in my old brain an example when I used weighing in Sandbox#3 loooooong ago. So here goes, from scratch, to see if the explanation is good and clear.
We need to scale distances both in the target and the query. amplifying distance makes them more significant. for instance, a piano sampling with 2 shots:
shot1: C4 @ 60dB
shot2: C#4 @ 61dB
What would be the best answer if I query a C#4 at 60dB?
If I care more about pitch, it would be shot2.
If I care more about loudness, it would be shot 1.
To achieve that, here is a little patch to visualise the zone, the hommage to Fiebrink. @rodrigo.constanzo please make it beautiful.
And to solidify my understanding, having the larger values (as in how my synthetic/real examples above do it) is, in fact, making those columns weigh more?
")
")