Ok, so I’ve finally pushed this a bit further and have tried getting into the nitty-gritty PCA->UMAP-type stuff.
Took me a bit of hoop jumping to get there, but finally was able to test some stuff out.
So as a reminder/context, I’m trying to analyze realtime audio with a tiny analysis window (256 samples) and then feed that into a regressor to “predict” what the rest of that sound would sound like.
I’m doing this by building up two datasets of the same sounds. The first one being the first 256 samples, and the second being the first 4410 samples (I may experiment with this being samples 257-4410 instead).
I have a few premade hits of me playing snare with various sticks/techniques/dynamics/objects/etc… I’m testing things with 800 hits, though I can see myself going much higher than that for a comprehensive version (and also much lower for a quick-and-dirty-borrowed-snare context).
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////
I spent the bulk of the time trying to create an analysis workflow similar to what I was doing with my LTE idea (adapted from @tremblap’s LPT idea) where I funnel each “high level” descriptor through its own processing chain, with the idea of ending up with a lower dimensional space that represents the higher dimensional space well.
For the sake of simplicity/testing, I did: Loudness, MFCCs, SpectralShape, and Pitch. Quite a bit of overlap there, but it’s easier to test this way then trying to piecemeal things like I was doing in the LTEp patch.
The actual patch is quite messy, but each “vertical” looks something like this:

And the top-level descriptor settings are these:

(the melband analysis is for spectral compensation that runs parallel to this)
At the bottom of this processing chain is a bit that puts all the fluid.dataset~s together, and saves the fits for everything.
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////
I then tried mapping the spaces onto each other, keeping the fits the same, based on @tedmoore’s suggestion a while back. I could have sworn I did this successfully ages ago, but the results now were pretty shitty.
Here is the bottom of each processing chain with a 256 sample analysis window:
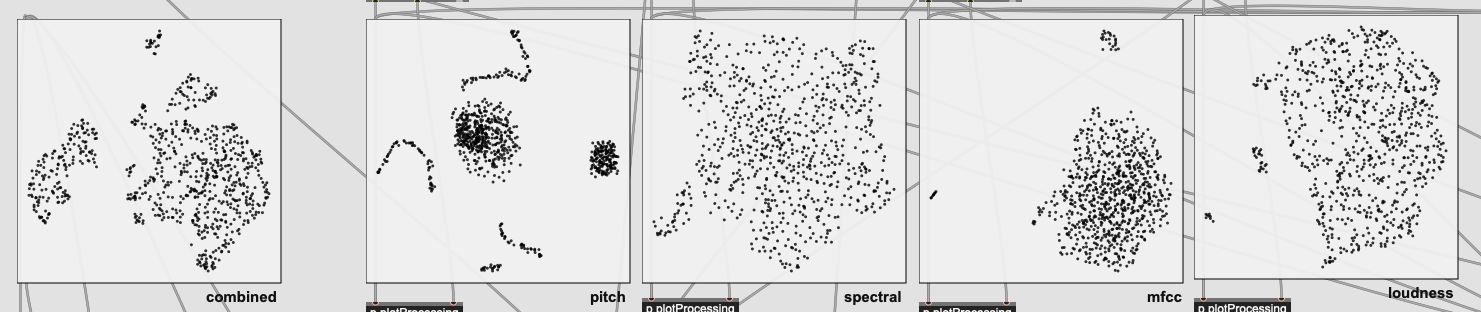
(pitch is obviously not great as these are mainly drum sounds)
And here is the 4410 sample versions, with the same fits:
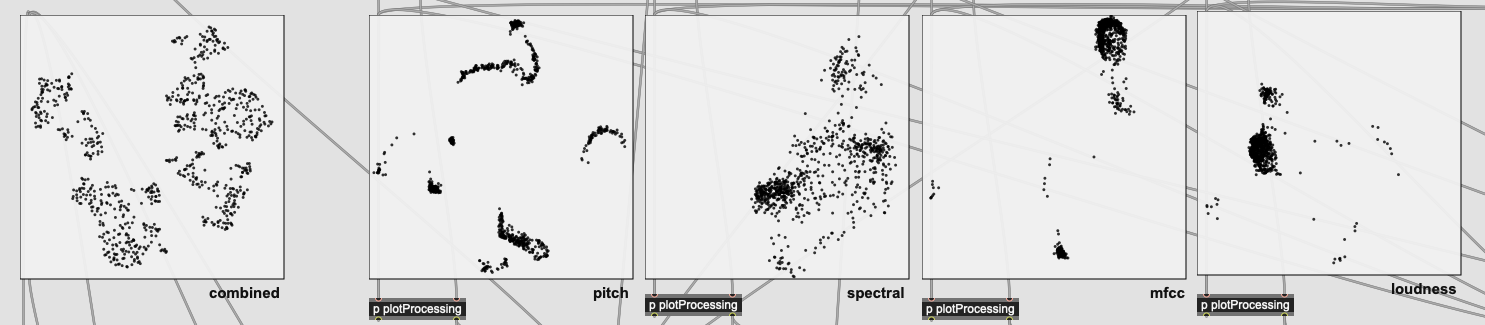
(ignore the combined one on the left, as I didn’t save the fit when doing this as it’s elsewhere in the patch)
I was a bit bummed out about this as I was working under the assumption that each side of the regressor should be able to map onto each other naturally. I was reminded that this isn’t the case when rewatching @tedmoore’s useful video last night:

I guess the whole idea is that the numbers on either side don’t have a clear connection, and it is the regressor that has to create one.
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////
Now over the last few days I’ve been playing with fluid.mlpregressor~. I still find this profoundly confusing as nothing ever converges, the settings are opaque, the documentation/reference is thin, and I’ve forgotten all the “common practice/lore” stuff that’s been said on the forum over the years.
Other than doing a test/simple thing (e.g. the help patch), I don’t think I’ve ever successfully fit something! (well, barring the details below).
So at first I tried feeding the results of the robustscale->PCA->UMAP->normalize processing chain and was getting dogshit results. My loss was typically in the 0.3-0.4 range.
That was using fluid.mlpregressor~ settings of:
@hiddenlayers 3 @activation 1 @outputactivation 1 @batchsize 1 @maxiter 10000 @learnrate 0.1 @validation 0
I would run that a handful of times, and the numbers would go down slightly, but not by any meaningful amount. They would also sometimes go up.
After speaking to @jamesbradbury he said that that was probably an ok amount of loss since the amount of points/data is pretty high (8d with 800 entries).
On a hunch, I decided to try something different this morning and instead feed the network 8 “natural” descriptors. As in, mean of loudness, deriv of mean of loudness, mean of centroid, etc… So 8 “perceptual” descriptors, with no post processing (other than normalization so they would fit the @activation 1 of fluid.mlpregressor~. That instantly got me better results.
I tried again using only 6 descriptors (leaving out pitch/confidence) and that was even better!
Here are the results of the tests I did, along with the network size, and what was fit first:
@hiddenlayers 3
6d of natural descriptors (no pitch): 0.096001
8d of natural descriptors: 0.160977
8d of pca/umap (256 fit): 0.325447
8d of pca/umap (4410 fit): 0.463417
@hiddenlayers 4 2 4
6d of natural descriptors (no pitch): 0.092399
8d of natural descriptors: 0.155284
8d of pca/umap (256 fit): 0.317485
8d of pca/umap (4410 fit): 0.44022
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////
This was pretty surprising I have to say. If it holds up (I’ve run the tests twice and it has), it would be even more useful for my intended use case (analyzing “long” windows in “realtime”) since the numbers on either side “make sense” and are relatively scalable. As in, I know what the mean of loudness is, and can do something with that from the predicted version, as opposed to 1d of a slurry of PCA/UMAP soup.
I still need to have a think on what I want to do with the results of the regressor as my idea, presently, is to use that to find the nearest match using fluid.kdtree~, with the idea being that with the longer analysis window I can have a better estimation of morphology (and pitch). That being said, it is a predicted set of values, rather than analyzed ones, so I’d want to weigh them accordingly, something I’m not sure how to do in the fluid.verse~.
Additionally, I’m not sure what descriptors/stats make the most sense to match against. Perhaps some hybrid where I take “natural” descriptors for loudness/pitch, but then have a reduction of MFCCs in the mix too? I do wish fluid.datasetquery~ was easier to use/understand, as I could just cut together what I want from the datasets below, but each time I go to use it I have to spend 5 minutes looking through the helpfile, and then another 5 figuring out why it didn’t work, and another 5 making sure the actual data I wanted was moved over once it does work.
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////
SO
I welcome thoughts/input from our resident ML gurus on things that could be improved/tested, or the implications of having “natural descriptors” regressing better than baked/cooked numbers.
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////
Here are the datsets I did my testing with if anyone wants to compare/test.
NATURAL_6d.zip (113.7 KB)
NATURAL_8d.zip (113.7 KB)
PCA_UMAP_256fit.zip (123.9 KB)
PCA_UMAP_4410fit.zip (123.9 KB)