I know at least @tremblap (and perhaps @spluta and @leafcutterjohn? ) is using some FluCoMa stuff with modular synth stuff, so I figured it’d be good have a thread that was specific around that topic with code/examples/etc…
(the scope~s aren’t part of the device they are there to show what’s going on)
I mainly made them to work in Max-land, so along the bottom is a bunch of diff outputs, all signal rate, with the light grey ones being s&h values (driven by the onset detection).
I’ll probably tweak the underlying code a little bit, but the core idea has been suuuper useful for my experiments.
It uses the super useful AudioMix package for all the boring plumbing/mixer-y shit, but with this I have three analysis buses, which I can send out to my ES-8.
I’m also curious about the automatic scaling thing that @tremblap built/showed me a while back, since that would come in handy for certain things I’m building at the moment. (do you have a tidy/shareable version of that @tremblap?)
I also want to revisit the CV->NMF stuff I was playing with around the first plenary:
I’ve not played with it in a while, but I remember it working really well for ‘offline’ stuff, but I never managed to get a real-time version working due to buffer sizes, and downsampling funny-business.
Either way, curious what else others have been up to with this kind of thing.
Interesting post! Let me try to make my answer not too long… first, a few other people who have openly been interested in this in the plenaries are @tedmoore and @rdevine1
Secondly, I have to say that I’ve done a few things along those lines in since 2009 but they usually in bits that are used ad-hoc in a piece or a project, then shelved until I can have access to more potent technology or that my brain catches up with what is available. They are usually in the same idea, which came around when I was exploring descriptors in a way to control descriptor browsing. When working with CataRT at the time, and modifying it for sandbox#3 the fascinating Diemo Schwarz told me of a project that was going on in the few years before, where they used a robot to iterated through complex physical modelling patches to describe them and then navigate them in descriptor spaces… that put me on fire, and I did a first few attempts with modular then, not super successful. That frustration led to the FluCoMa project Since then, some public version of such iterative software have emerged, like this
In parallel, I did one that worked better for me in 2014, which I have reused since then a bit… it was based on @a.harker 's descriptor and entrymatcher. I was interested to control the pitch of a very chaotic synth, to resynthesize an audio stream. In the end, I found it more effective to do a single control via CV, and sample 1000 points iteratively. Then I would use a stream of 3 descriptors (pitch, centroid and amplitude) from my target(control) and match each to a different pitch through entrymatcher controlling the chaotic synth, then a simple mapping to an LPF and a VCA for the other 2, and the result was quite potent enough for me to have fun with a training time that was manageable… you can hear a local bird recording (a willow warbler) I’ve resynthesized here: https://soundcloud.com/pierre-alexandre-tremblay/oiseau-solo1 the patch is very ugly creative-coding-in-composition-time-messy but I can share it if someone wants to have a peak…
Now for the immediate future, I am interested in more than one dimension at a time, with machine-learning, both from a live stream of descriptors (bass) and from segmented targets, but this is work in progress and far from finished. I had a first poke at this idea with the fantastic Wekinator last year, then with a basic neural network my son has coded a few weeks back (proud dad moment here) for which I’ve done a quick demo with a virtual chaotic synth… I’m happy to go in more details on any of my plans for both ideas (real-time control and segmented targets) if that could interest anyone.
Ah yes, forgot about @tedmoore and @rdevine1. I imagine @rdevine1 in particular will be doing loads with that when the next concert (eventually!) happens.
You’ve shown me the patch a couple of times but I didn’t remember if it was based on discrete points (it is I guess) or if you mapped a continuous space. I remember the ‘scanning’ part of the patch being quite clever and efficient too. So are you using distance calculations to do some kind of interpolation between the sampled values or is it all quantized? (from the sounds of the soundcloud demo there’s some steppiness)
I was wanting to build/test something simpler where I would map something like centroid to a filter (or filter-y thing) response, so I was going to do some kind of one-to-one mapping just taking measurements along a point and just plotting it on a function object to interpolate between the rest.
Obviously this wouldn’t work in a one-to-many or many-to-many, not to mention getting all ML-y, but it seemed like a reasonable place to start.
My version you saw is based on discrete points, and I take the nearest. The version I tried with Wekinator was testing various interpolation but for non-linear synths, that was not conclusive then. Then trying the MLP stuff with Édouard gave me something fun to embrace the non-linearity, but I have not tried the new plans, which are with 2 many to many mappings in an assisted learning fashion…
Yeah I remember the non-linear stuff really complicating things.
Did you ever try just plotting the points on separate function objects (one per dimension) to see if that gave you anything useful?
Would still be good to see your code, for the sake of the thread/discussion, but also to see about the jumping around the register and sampling cleverly (though for linear measurements, it doesn’t matter too much either way).
This kind of model (training sweet spots and then navigating a 2d space) doesn’t interest me too much, but this could be interesting with some of the self-organizing map stuff and/or doing some training via “resynthesis” models (i.e. feeding it sounds, and using those as training points).
I did something similar comparing the few nearest neighbours, but the thing was that they were at opposite places of the space…
You need to use your imagination a bit… if you can map to 2D you can map to anything. MLP is actually good as a classifier, you just pick whichever score you get on the data you get out… for instance look at the other classifiers we have done so far in the example folder, you can make, with many inputs, the bassdrumness, snareness, and highhatness values, train with 10 of each from a bunch of inputs, and you will get values out… I’ll do more example once we have something along those lines in our toolset, but the ideas are in the Kadenze class of Wekinator if you don’t want to wait
I get the idea, it’s more of the interest and how I like to approach things creatively. And actually, to put it in the form of anecdote, when I was younger, my mom asked me what I liked to have as a snack. I told her I liked apple sauce, as I was into it at the time. And she bought a ton of it. Needless to say I got tired of it and didn’t like apple sauce anymore. So that’s all to say that I don’t like making decisions about what I like, because then I don’t like it anymore.
So this paradigm of “this is a specific sound I like, give me more like it” doesn’t interest or inspire me. Which is also why after watching all the ML Wekinator I didn’t install or test any of that stuff out because it’s all (pretty much) based on, map this spot to this, and this spot to this, and now train…
Yeah I can see that being the case.
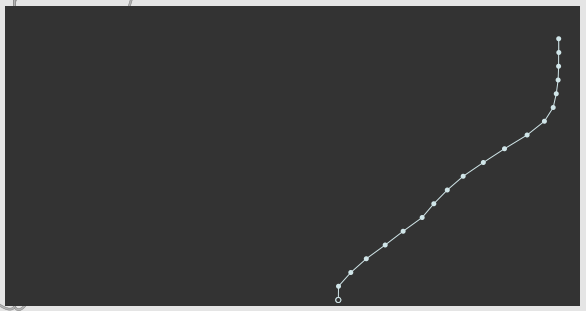
I just put together a simple thing (manually) where I took 20 measurements off an LPG (LxD) while pumping some Disting pink noise through it (can you believe I don’t have normal noise in my skiff?!) and then ran the centroid analysis off the scratchy turntable stuff and have created a simple resynthesis of it! Granted the sounds here are fairly straightforward and linear-ish, but it works as a first initial test.
Here’s the response (visual scale is 0.-1. / 0.-127.):
So linear for a big chunk until the end.
And here’s a comparison (the “real” snare audio is highpassed 110Hz whereas the noise is unfiltered (other than the LPG)), which sounds pretty convincing! It “feels” right too, not to laggy or unrealistic, which is quite weird given it’s a synthetic sound. It sounds really badass if I hard pan them too since I get a faux-stereo effect going.
The crossfader is also being sent to a VCA with the same signal-rate control I use when chopping up the direct snare audio.
that is the main difference between our use. Yours is very linear. Imagine mine is something like 440Hz is at 0.1 and 445Hz is at 0.5, but in between you might have anything like 220 and 880 around 0.2 and 0.3 so interpolation is much harder. it is not random, so there might be a way, like the spirals in this fun learning toolbox but very hard to find out with the right combination of descriptors…
anyways, I’ll show you more when I get to something more convincing with my non-linear patches…
ok, I completely forgot this since I got excited on other similar threads… here we go, very dirty and undocumented, as I like my private patches. I had to spend a few minutes to remember how it works, which is not so bad for a patch from 17 Nov 2014
The audio return is on the [adc~ 11] on the left, and came from the synth from the expert sleeper via adat. The single control out is done in the middle of the patch [dac~ 11] going again to the expertsleeper via adat. Just beside this you have a switch which is off at load time (make sure you doubleclick that loadmess if you copy/paste the code)
In mode 0 (analysis) you can play first manually the float object above the switch between 0 and 1000, where 0 is outputing DC -1 and 1000 is outputing DC +1. If that modulates your patch, then you press the bang at the top and the clever 3 pass FFT re-setting is happening, scanning 1000 points for pitch with @a.harker descriptors and entrymatcher.
Once the sample is done, flick to mode 1 (playback) and you can play the keyboard or the funny sequence on the bottom right.
You can see the interpolation questions I had at the bottom. They generated my desire to be able to do data processing in Max… which generated FluCoMa grant app. Here we go
Don’t know how much you tidied before posting, but it’s pretty readable for a PA patch. Obviously some confusing bits in the middle, but it looks like I may be able to get it to work (will report back).
do I detect 2 almost real compliments in 2 posts in a row? Are you ok?
yeah, if you are more patient, you could mod the patch to enter 10k points of which 100 at full resolution, that should give you more precision… but i’m never that patient replacing entrymatcher with knn in there would be good, so we could check clustering too (in relation to our other thread)
then take more time by changing the multiplier of FFT size in the middle of the patch, before you change the number of points. that will allow unstable pitch to settle.
My next steps for this are along the lines of bringing statistics of time domain windows like in LPT and other patches like fluid corpus map, to allow even more chaotic material to be musaik’d) (wow that is an ugly past participle)
Not using FluCoMa stuff at the moment, but in working on the (epic) Kaizo Snare blog I’m recording and added other bits of related media to the project.
This is expanding on some of the stuff I did in Kaizo Snare where I take a bunch of secondary controller streams from the fader (overall activity level, distance between direction changes, time between direction changes, “velocity” from that (distance/time), etc…) and use these to control the whole patch. So 8 streams from the ES-8 controlling everything from the single fader.
Would be interesting to gestural decomposition either in an NMF-y way like that CV stuff I did at the start (which I never got working in a real-time manner) or something like that Heretic thing from the other thread.
Even some “simple” novelty stuff to send triggers when new material is detected.
The funny thing is I set off to try to get as much from a single fader as I could, and that shit fills up real quick!
 Since then, some public version of such iterative software have emerged, like
Since then, some public version of such iterative software have emerged, like