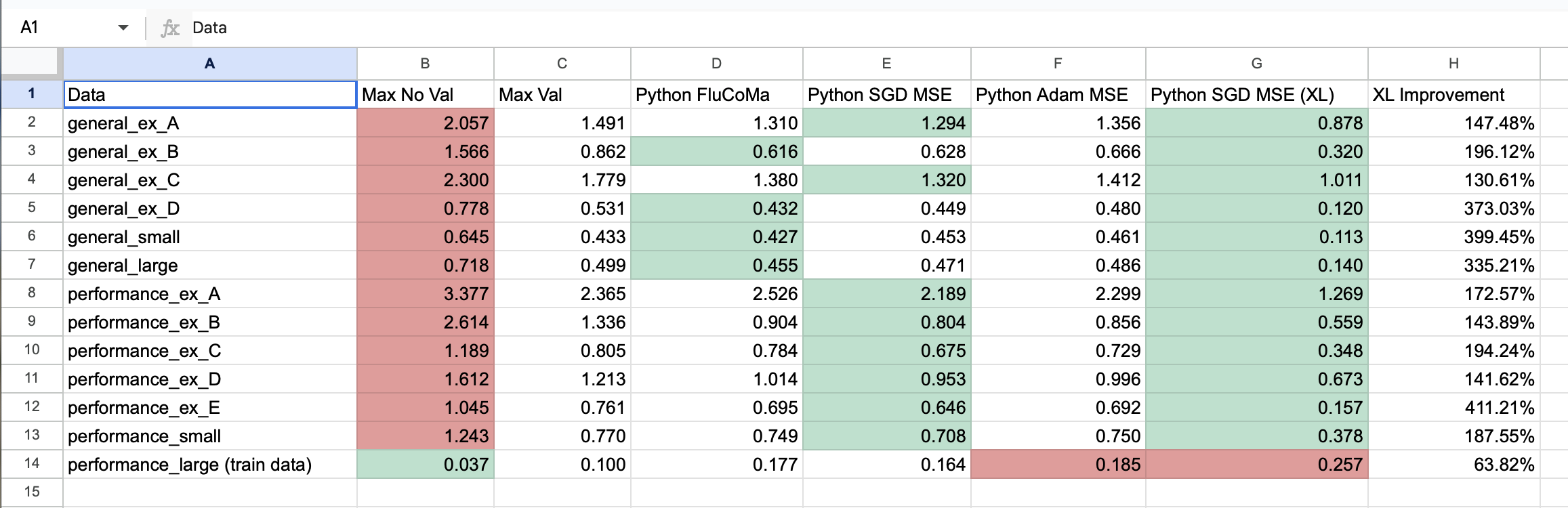
I know this is a bit late in the game for an FR, but this wouldn’t really break things and would make it easier to run big trainings on regressors without needing to pinwheel.
So the main issue is that I, like I imagine many people, do my regressor training in a defer’d loop like this:
----------begin_max5_patcher----------
1949.3oc4ZssjiZCD8YOeEp3YutzcgxS6+QRpov1Z7RBFbA3Y2IoR91SKI.i
Gi4hMimjJT6XVDRp0o6S2RsD+4SKBVm8CSQ.5mP+LZwh+7oEKbEYKXQ0yKB1
G8iMIQEtpErIa+dSZYvR+6JM+nzUdbI56YGS1hVaP6xMQknxLT9wTTQ1dS42
hS2gRh+cCB9uEnu+MStAAMYcTbRAzjWxfmyd0j+RbYIT2kn0GKQwonHzuDjj
kc3WBpkXRbpYS1wTmXYUEdH2T.ipnx3rzmOqF75ZDUtwNJdN2rozCXoFuBuD
wnT6MJ1cSJWgQ+ZUiROtONMwT5fNopv3sN.ms929BEWOpVeb85DSQ7Vi8kzS
sO6XYcGfOqtttzVve8zS1eVNRCvdSQQzNyEFfMIln7fqi1PkvgVszcy8fE4c
CV5kfknC5DV05EeQkucv3EXP.5WuA7cMBlm3Dmjf1kgxRQVJCPXVhfeSQwu.
LKCBTAIugJJyNbvx31jGWZxiiPPSAVX+TnKUYrPGAQPY1aDg+IxDHHDUvGHU
3ZpJ5JD3GgxMfiXQQVerBBV4I+RODcHkwZAwWxRKKh+COu1pAFIxEeFHmrBk
jEsEsMpLpvJwqibNygbt21JUyFv4AeBd+V6MLFwBBi1CnUXGb4ggNTSISOJ.
8gDEnOblDsq34zr78nCYEw1P99GGF2UA+HR5jwM6g.6Ty2AgcIpSNFuc09jC
Mtz+M5qeKd6VSZRzal7BXRL6+9Zzlx3WcyBhXnuBcsM9G3j6tFAuf43Ebrte
8SGzdY25G5U0OKmapwg73SQD5Z5dQkwuZV+ISAB+Lo.fo+fIcqK7VOfTHIs.
oZ51Q8mp68P1Pt9Nsgp+CXC436zFJdHfDVgdYV5v3f6WgAu929gwgn7HXoZl
7mMoQUSThuDh7IBw0Qo6lUa413MkMy+f9pY+ZyVDYDdlUqzhwmL28Jy7JtFl
sCQXvEk+lKXa6+ZjocgRUfuB8KfEWkzdHbdkpq0h.rWLNRJ9DLf2PpeCy9FE
6rqV0iVWu2UEaqXXQqKYqVwN0pvVW5knufWQCOqrVMi2LnHxVWJWyTTUqqvV
MS3alqqe2f7KWLDZ0NYS6dWe6Z20Qm5T6tTobczE1zr200NK.8rKuaPkifyU
vyEJhd0r8YfoAb1miJKyiAWb+tCzld3n5sb1f7oL6h17VKO0dcia+x8QGNz7
5mNMnlQeTX0hiw8rNnak64Pq.pqUF+fcO4ix8DXDXBQSzTViehMQAUHUq0b+
kuHA7nlz3V3pEjhf5Du48d3N5FWR3j553cBwXMQPwsnfXMkGp4s6cA3Lvohv
dhKvHJIWQ3MCyuXaFWpArz1MDSvDMixaAGpLTowTR0UWwODRLIThEdORFnlH
7y7RAAqvveMXCJhpwZciNoq3KTLjCFsUO4B4fELgWRRFfIFi1pWwgDshzkes
nIHKlpfQSaEnjyrVryzDLBKDVp+Iuem4fRDRQGphSAovfcjxvgs3HvXSg0r1
zFH1hVGROKhKmAihvF10kgxfNmKvLp3LcKVwCEgp1lLAHKIQdNdTvnOT0wX+
TDOghQ3LgrMykH.dI+L3Pfr+NmeaCUpk3SyL8+j3h9zIq1ij+d7YQWsDFvox
u9TwjWYJ3k8vxSbbfuYyDFdtgZbywSG2T8CC2kY61kX5KYeVKzLGqKu30cNI
GzwZVISMYDaBfyo8tvjfv8N0ek9P3xSgPT8acYccL.WY2gX8lNxxS2+WwljQ
7GDBSbyaRFLk+mY90kfgd8fFZFdTadPmG2yT2kK2tY7Aj8YIZcuT5ZSoGp2P
fZJVMQnVSkma+WKTeYXnx0d2WEYkXxXM7Fw5KIYQyKZ2ZRhdCIwCxhEgtv2h
aXaDv5O8MOw7hIOI66ChRo+n2FBkcYTI3OyPQ6hJGdJXge61kgS2FRHelnKG
5di8LFGgeo21w02.Fo+6XshS7bWFgNAy8QmuEZM6goTfnafL5ANUSuTQiUpw
glWfUgD45A4z1yWJ9VRd31Cds+XRYbQR7VSemfNjVtSIncwiY7pCRWNSazME
23oaOP6x270Tzqh.pIHQ.LmsEsUGCHlv0XBoYSGmSJiM63iw8nszTU6Chcrb
lQprFJluc34Ms9SFMXbQKciM2WMx69Tob.zV94pjhri4ap6p5OcFzIHt0TTF
m5BWzpRRec5TqOZAgePBh8fjibDxwNOAhbmBxk5xfhxE98tAUSuLfrnyfrFC
yysqL2sjBeXRRMFIQ0yfjDOLIwGCi3r5jkamXpdCB+PELoaAStSufQ4wgmGO
N5njU3rHKxnjkdVjEdTx5bM893sGxf7zqlMKjZSY194wnCkZb04bRkD2G6X+
uhQCWIwPAZt6UBl8rsuxqt6Pz5QE1bNBwzPEFPVjYYpmPeuLfQ7iwKbjBG+Q
D6wsKSCK724P8N5qcQjV5FmsJTqXgX+IAwUKqX1W9l61folhW2cJK4nIh2ur
XihKnlMYMrNbNVD4Xh8OGQiGSb+K4D9rKhNb3USdQUkch.xR42xbdY5ktGiS
8O5x7IH27Zbc8ceK.AQ4P5VkPtVGycCqfeH8emTA6y.+0THyLe7B2QaF3RaK
Exqp3PjGGtr6d5ud5eHRJQAK
-----------end_max5_patcher-----------
This works well in that you can monitor the progress with smaller @maxiter sizes, then manually stop the training when you think you’ve gone far enough.
The issue here is that it’s quite easy to overfit the data as there the “early stopping” criteria is ignored by this approach since even if the amount of epochs don’t improve after a bit and the actual fit-ing bails, the new fit message keeps the process going either way.
The version of the patch on the right would work better in that you just run a single huge @maxiter and call it a day. Or manually run it a few times if need be, but the problem with this is that it’s hard to tell if you’ve actually fit things well, especially since the loss range is arbitrary(ish), so you get a single number back, with no context as to whether that’s good or not.
So what I’m proposing here is to add a message output to the regressors where they output a stop message, or maybe fit stop (the former would likely be better as it wouldn’t break any existing patches) when the “early stopping” criteria is met. That way in a loop like above, I can use that to stop the overall training and avoid overfitting.
It would also mean that I could avoid needing a toggle for the loop at all, where it can just train until it’s happy, then bail and let you know how it went.
////////////////////////////////////////////////////
A more fancy version of the FR would be to have any fit message report the loss as it’s being computed, rather than a single time at the end. Or perhaps it can always spit out x amount of loss values per @maxiter such that if you set @maxiter 100000, it will spit out 10 loss values as it is being computed, so you can see if things are improving over that time.
////////////////////////////////////////////////////
Lastly, if there’s a way to do this currently that I’m missing, do let me know.