A question about the interface for this*.
I’m trying to recreate the analysis window and timescales from my main patch, in order to compare the different types of descriptors and stats.
In my original I have 256 samples that I can analyze (from the JIT rolling buffer), and I’m using @fftsettings 256 64 512 (zero padding the end as per @weefuzzy’s recommendation).
In my present patch, I have this:
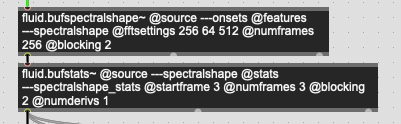
Which gives me 7 frames of analysis total. I ignore the first and last few and take the middle ones, since I don’t want the pull from the zero padding on spectral descriptors (mirroring would be great! (but different story/post)).
I know I can’t do the selective start/numframes in the comparison patch, which is fine, but I have no idea how I’m supposed to designate that I want to create the same type of analysis.
If the -comparison patch, if I put in the correct @fftsettings (manually adding the 512 at the end), I can’t seem to select an amount of frames that corresponds with what I’m doing in my patch.
This seems the closest, but I don’t think this is right:
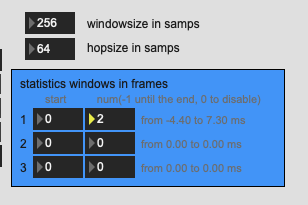
If I put in 7 frames, which is what I’m getting in my patch, I get this, which is waaay off:
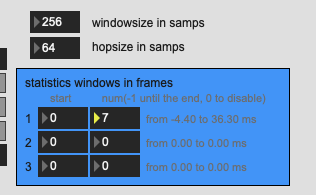
So either I’m not understanding the maths here, or the maths is wrong (i.e. windowsize vs hopsize being multiplied for the ms conversion).
And to be clear, I’m earnestly confused here*. I would actually like to know what I’m supposed to put into this interface to correspond with @startframe 0 @numframes 256 @fftsettings 256 64 512. (The purpose of this is to use the same settings I’m doing in my actual patch, I just want to be able to compare the different descriptors/stats to see what works best, and 256 samples is all I have, and those fft settings are what works best with those few samples).
*I promise this isn’t me trying to be difficult or bust balls, but I actually don’t know what I’m supposed to enter here.
