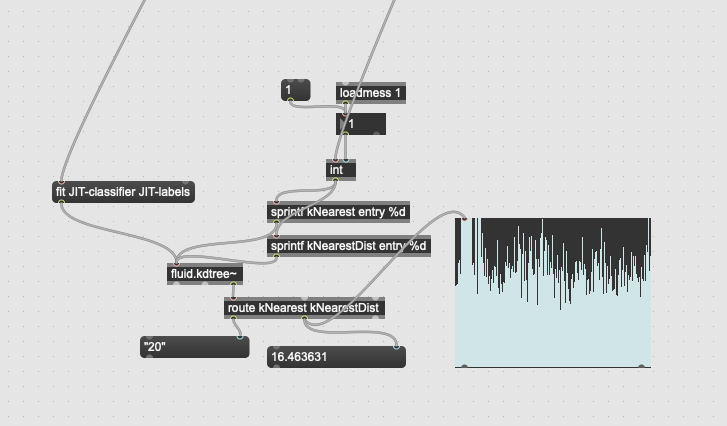
Ok, did some more testing today and the best results I get, by far, are using the Sensory Percussion for onset detection, and the DPA to feed the MFCC machine. I tried all kinds of combinations of highpass, 5k spike, and mic correction on the Sensory Percussion pickup and they were all very erratic (with the same settings and training points across the board).
The best I was able to get out of it was going through the mic correction convolution followed by a light highpass (110Hz), and this wasn’t great.
For my use case I can just do the double mic setup, but I’d like to generalize the approach, towards the end of building a set of tools/abstractions for using this pickup natively in Max-land.
https://twitter.com/r_constanzo/status/1086560091954917377
Indeed…
I’m obviously not thinking this through correctly, but if in this example @tremblap has created a 96 dimensional space, are you saying I should have 2^96 (79,228,162,514,264,337,593,543,950,336(!!!)) amount of training points? I guess if I start now, my great-great-great-grandkids can test it out to see if it works…
In my testing today, I didn’t really notice a difference when querying for anything between 3 and 10 nearest points. Most of the tests were around 100-150 total points, with a 96 dimensional space.
Granted, my testing method was “hmm, this isn’t matching too well…try higher numbers…still not matching well…try higher numbers…fuck it, clear and try again”.
Now given that the sounds of a snare are pretty damn similar, particularly between center and end of drum, I wanted to try to tweak what is being analyzed, to see if I can highlight and/or focus in on what would be different about the sounds.
So I figured I’d play with this part of the patch. And man, the way the descriptors->stats->compose workflow is sooo unpleasant and daunting. It would take me like 15min to make sense of your p extract-FCM-data because I have no idea what each sample…of each channel… is. Every time I’ve had to do this in one my patches it’s a “full fat” thing where I need to sit down, manually peek~ a buffer to find the sample and channel I want, and then hope I got it right.
I know I’ve banged the buffer-as-data drum to death, but out of curiosity, when you were putting this together, you presumably thought, “Ok, I’ll take 12 of the MFCCs and their min/max/mean of main and deriv” and were you able to intuit (or know) what samples and channels all of that data corresponds to? When creating that patch and copying over, did you manually check that you were taking the right data?
I guess when you’re packing “the kitchen sink” into something, it doesn’t matter, but picking and choosing what descriptors, and what stats, is really difficult, confusing (and error prone) at the moment…
Ok, ra(/ve)nt over…
So, I will try to mess with this part of the patch some to see if some better differentiation can be made.