and again, XKCD has the answer with Friday’s graph:
Yeah that’s a bummer that. I guess with data reduction you (potentially) lose some of how differentiated things are.
Sadly this appears fucked. I downloaded it (AudioStellar) and set it up, and it just sits on 0% initializing or gives me an “error path not found” whenever I try to load samples.
@jamesbradbury’s example isn’t online anymore either.
I created a mini set of samples so there are 20 of each of center and edge hits, all 512 samples long.
tiny samples.zip (44.1 KB)
Hmmm. At the moment I’m getting pretty solid differentiation when I train sounds that are actually different (e.g. center and rim), but for most of the sounds that are actually different, there’s not really a middle ground or ambiguous space as there’s a different surface involved. I did try training hitting the rim with nearer the tip of the stick vs nearer the shoulder, and that worked without any mistakes. I didn’t test to see where that difference started though.
The center to edge, I guess, is the hardest one to tell, in terms of regular snare hits, since they sound the most similar. Perhaps this is not the case, but my thinking is that if I can get those working smoothly, the rest will be a piece of cake.
I plan to rectify this soon as its going to be part of a potential journal submission. Stay tuned…
2 Likes
I recommend reading this paper we published under the indisputable authority of @groma … or just look at the graphs, it’ll tell you what you want to know: indeed you always loose and the various reductions will give you various pros and cons, various affordances, hence proposing in that paper to compare them and see which one fits your needs. As @weefuzzy said, 'It depends’™
I was reminded today of the oldschool NMF-as-KNN approach I was experimenting with early in the process, and came across this post which shows how effective @filterupdate 1 was at refining the filters and selections.
Pre @filterupdate 1:
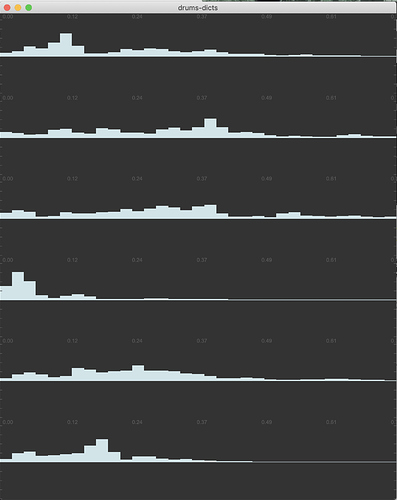
Post @filterupdate 1:
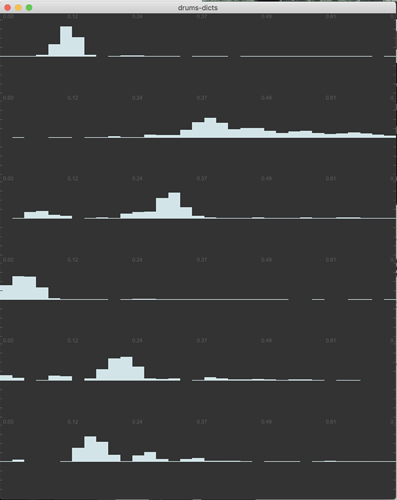
I’m (fairly) certain this is a naive question, which is probably not possible given the algorithms at play, but is there a way to train some points, and then run arbitrary audio through to have it refine the selections based on the input?
Obviously one can add more points to each classification, but perhaps something like this could help catch or fix the edge cases. (Would be amazing if there was a 2d view where the arbitrary audio that it was fed is mapped, and you could go through and say “this point is A, this point is B” and have the network update accordingly.
Yes you can with machine learning. Soon. You train, add points, train with problem point and/or tweaking parameters. @weefuzzy will confirm but this is what is happening under the hood anyway in nmf, reducing the error by iteratively training… @groma and him keep telling me that nmf is a sort of unsupervised yet seedable classifier… now they will correct me here if I say stupid(er than usual) things
1 Like
Great. I’ll wait on the next release to push this further, or rather, refine this further.
It just seemed like an obvious way to refine the selections without “start over and hope for the best”.
maybe the one after. We are devising packages. stay tuned!
1 Like
I decided to revisit this, as I’ve learned a bunch from the melbands range and smoothing/reduction in this thread, as well as some problematic fft settings in this thread.
After some quick initial testing (took me a bit to figure out the new syntax/messaging) I still get better results from the MFCCs vs the melbands. I did, however, now get good results from the MFCCs when using a smaller analysis window of 256 (using @weefuzzy’s suggestion of @fftsettings 256 64 512). I think I get slightly better matching using a larger analysis window of 512 but the tradeoff in latency isn’t worth it.
So at this point it’s looking like I’m going to be extracting every bit of juice of those 256 samples (“normal” descriptor stuff/stats, 40 melbands, 12mfccs+stats), each for a separate functions later on.
Also wanted to give a bump to this section. I don’t remember any specific mention of the semi-supervised tweaking/updating in the last release(s), but the objects have been refactored, so it’s possible it could have happened and I didn’t notice.
not yet. this is a new series of objects that will replace the quick and efficient KNN with neural nets… slower but cleverer. Stay tuned!