Ok, looks like there’s details of the workflow here that aren’t clear to me, and that I’d missed that the motivation for using an MLP was with respect to the furthest sensor (although whether or not an MLP could deal with that depends on how the data is junk), rather than as a way of avoiding having to find a closed-form expression for mapping coordinates to arrival times and, possibly, dealing with extra nonlinearities in the physical system.
In my mind, the data flow was just [calculate relative onset times] → [mlp], but something more complex is happening? I’m not sure what the lag map is, for instance.
If the most distant sensor is problematic, then it’s probably worth stepping back from MLPs and looking at that: is it more noisy measurements (so, stochastic in character) and / or added nonlinear effects? Having some idea of what’s causing the dog-shittiness should help figure out what to do about it.
Meanwhile, with respect to the MLPs
Really 10 layers? I used a single layer of 10 neurons, i.e. [fluid.mlpregressor~ @hiddenlayers 10]. But it may be academic if we’ve established that we’re not trying even vaguely equivalent inputs / outputs. In any case, you usually want more observations than neurons (so 9 training points isn’t going to be that reliable), but if it converges significantly worse with more training data then that points to something either funky with the data, or a network topology that isn’t up to the job.
Standardizing will make the job of the optimizer easier, but shouldn’t necessarily make the difference between being able to converge or not.
Can you just send me your raw(est) training data and patches offline? I don’t think I’m going to get a grasp on exactly what’s going on otherwise.
The whole process is such (for the 4 sensor array, but similar for the narrower 3 sensor array):
independent onset detection for each channel
lockout/timing section to determine which onset arrives first and block errand/double hits
cross correlating each adjacent pair of sensors
send that to “the lag maps”*
(find centroid of overlapping area)
The lap map approach is something @timlod tested and I then implemented in Max (with a bit of dataset transformation help from @jamesbradbury).
Basically each a lap map is pre-computed at on a 1mm grid as to what each lag should theoretically be for each sensor pair. In jitter it ends up looking like this:
On the left is the NW pair and on the right is the NE pair.
These were computed in a similar way to you’ve suggested as to what they should theoretically be based on drum size, speed of sound, tuning, etc… So these maps are drum/tuning/setup-specific.
Once the cross correlation values are computed, rather than send that to all four lag maps, it takes the index as to sensor picked up the onset first (step 2 above) with the thinking being that those TDoAs would be the most accurate/correct. That then does some binary jitter stuff to get the overlapping area:
Then some more jitter stuff to find the centroid of the little overlapping area.
So the overall idea is to ignore the furthest reading as the cross correlation isn’t as accurate (nor is onset detection).
The MLPs role is to improve non-linearities in how this approach behaves close to the edge of the drum. This lag map approach is super accurate near the middle and does quite well for a long time, it’s only the furthest hits that get a bit more jumpy/erratic. I(/we) suspect there’s some physics stuff at play near the edge since the tension of the drum changes and energy bounces/behaves differently given the circular shape etc… So the physical model, lag maps, and probably the quadratic version, can’t really account for that. At least with the level of complexity that they are generally implemented at. Nearer the center of the drum it’s just an infinite plane of vibrating membrane, that seems to behave quite predictably.
There’s also the side perk that you also wouldn’t need an accurate physical model/lap map to work from as you could strike the drum at known locations and have the NN figure out the specifics.
Yeah I misspoke. A single layer with 10 neurons.
I’ll send you the data test patches offline (will tidy the patch up a bit first).
Actually this is correct. But getting relative onset times is the hard part here - if onsets detected across all channels aren’t aligned, nothing will work (they could even be consistently wrong - but consistency is the hard part.
Note also that lag maps really are only a thing because numerical optimization (solving multilateration equations) appears to be hard to achieve within Max - that’s why I came up with the approach to pre-compute all the possible lags within a given accuracy, and index into them to get the position of a hit.
So really I’m sure that the issue here is that the onset timings aren’t aligned properly - this means that different datapoints will contradict each other, making convergence hard/impossible. I’ll discuss this with Rodrigo in person soon, so we’ll know for sure!
The 3 vs. 4 sensor thing is more interesting from a technical standpoint here, as the 4-sensor data is easier to align (3 out of the 4 are closer to the actual hit, which yields data more amenable to align with cross-correlation).
I have to ponder this a bit more later, but I think zeroing out the last sensor might work in theory, at least if we don’t use a bias (my example convergence without using a bias). Then again, 0 holds meaning in this case (same distance to sound source)…
There might be something more elegant I haven’t thought of yet - at the worst we could train several networks, one for each configuration.
In PyTorch there’s also a prototype MaskedTensor implementation which might be just the thing for this, although I haven’t used it before.
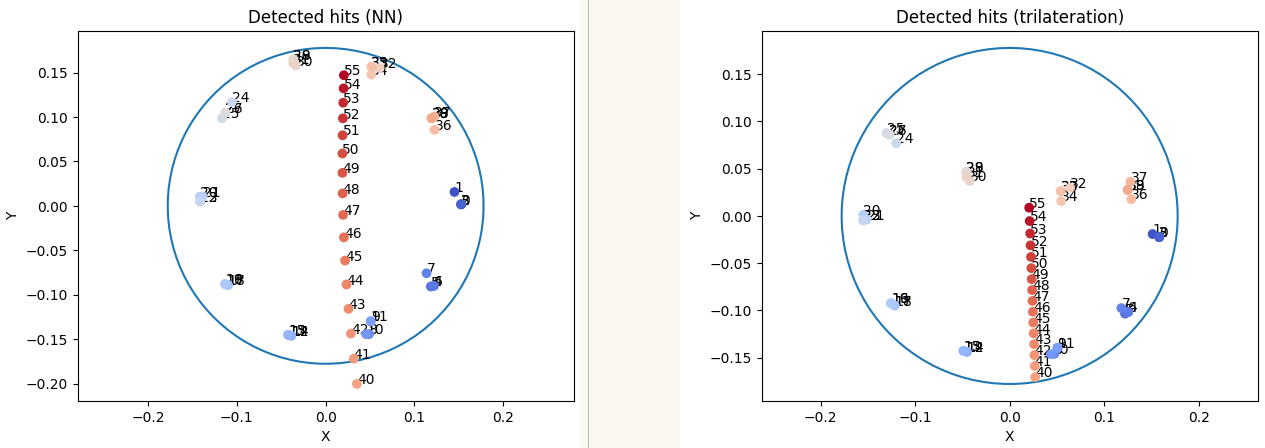
Just a little more context wrt. the nonlinearity we’re trying to solve/the motivation of using the NN - here are results of my corrected air mic data, once using a trilateration (based on calibrated microphone placements) and once based on training a NN on the same lags.
Here you can clearly see how next to the close microphone situated at the top/north end of the drum (the setup is 2 overheads and one Beta57A close) the physical model doesn’t detect hits accurately, whereas the NN solves this pretty much completely (one layer of 11 neurons):
(I had separated this into two pictures, but I’m only allowed to post one, hence this screenshot)
Note that in both cases the later hits going through the center are not real hits, but some theoretical lags I fed it to gauge interpolation performance here - the whole thing is based on just 40 hits (4 at each of the 10 drum lugs).
I’ve still not had a chance to really burrow into this. Just to note that the shape in the right hand picture looks very suggestive of a sign-flip somewhere (which, I guess, is a built-in challenge with solving quadratics)
Huh, thanks for the heads-up.
I know I had some issues with sign in the beginning of the project, but (at least thought that I) solved those then. However, this is already quite some time ago now, and I wouldn’t put it past myself to sneak some error back in
I will double-check this just in case!
Edit: Just double-checked it. There’s no sign flip/the equations are fine.
Actually, in this specific case the calibrated mic placement is very close to there being two solutions along that particular path, with one being the correct one (at the top/towards the rim of the drum) and the other being at the bottom respectively. I think it’s a little bit of a pathological case - in principle, when fixing the z-axis, I thought that there should only be unique solutions, but I guess that with some measurement error I have come across a case where it’s easy for the optimizer to stop at and pick the wrong one (potentially because of the provided initial guess?).
In any case, thanks for pointing this out - I was lazy in not trying to understand exactly what the non-linearity here was (tbf this was the most striking case after fixing my data, leading up to this there was a bunch of noisier results that just looked like ‘hard to generally model close towards the close mic’ on this dataset).
It might help designing the calibration as well as the later optimization a bit better to prevent this from happening! That is if I don’t end up just using the NN for its ease of use.
So re-re-revisiting this topic, but more relating to the original question(s).
Specifically, taking a dataset, and wanting to computationally remove “outliers”.
Even though there’s a lot of nuance and variability in the overall concept of what an outlier is, I’d like to try doing a vanilla thing like using an IQR-like thing to remove entries from a fluid.dataset~ that do not fall within a certain range.
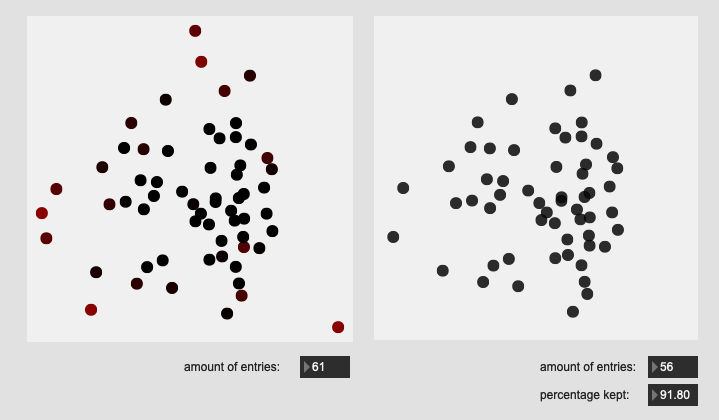
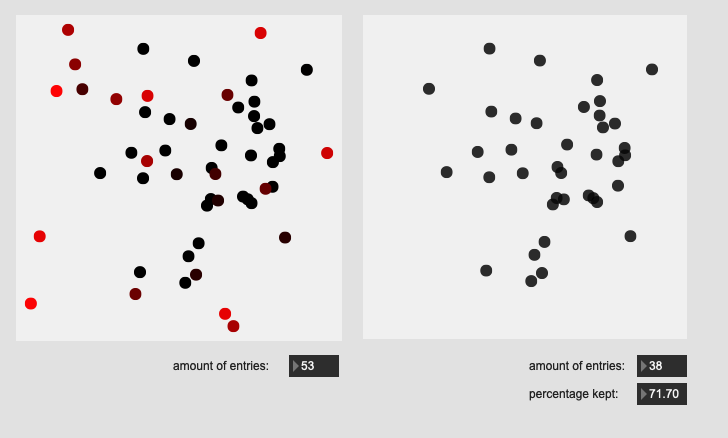
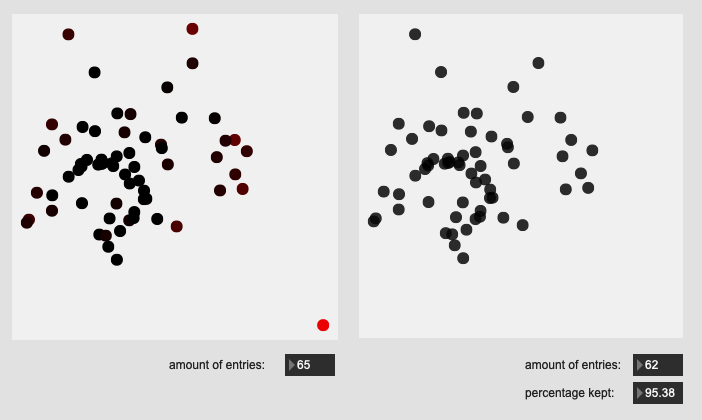
So I’ve got a test dataset I’ve created here of ~50 hits on a drum, with all of them being in the center of the drum, except one.
That looks like this (when reducing 104d of MFCC/stats to 2d with PCA):
It’s obvious there’s a nice big sore thumb sticking out on the left there.
(as a funky aside, UMAP does a really good job of bending around to make the same dataset look more even/consistent):
So that leads me back to these questions from earlier in the year:
Granted, doing this in a more generalized way and/or baking model evaluation stuff into FluCoMa would be amazing, but given the tools as they exist, I’m unsure of how to (computationally) go about this.
My intuition was that using fluid.robustscale~ would kind of highlight what the boundaries are, and then pruning can happen from there, but now that I’m revisiting the idea, I’m less certain that’s the case.
So for this dataset (a single obvious outlier), the dump output of fluid.robustscale~ (after fit-ing) looks like this:
As can be expected, the range is fairly narrow, given that most of the hits are nearly identical to each other. So it would follow to think that when going through each individual point in the dataset, that I the outlier would be the one where the distance from the median is greater than the range for each column…
BUT
that would take each column (in this case, MFCC coefficient and/or stat) as an “island”, independent of the overall datapoint.
So this surely has to be something that takes the whole datapoint and checks that againt an overall percentile. So I guess it’s an IQR-y but not implemented in the same way.
Now since fluid.robustscale~ isn’t throwing out any data, I guess it’s fine that each column is treated/scaled independently, and as such, I imagine the computation internally goes no further than that.
So what would be the steps to go about doing something similar but, um, “manually”?
I guess I want to know the overall percentile but as some kind of average across each point?
The multidimensionality of this kind of confuses my brain here.
Ok, so what you’re describing in plot is a sort of geometric idea of what an outlier is. The intuition with using robust scale to try and something out about the distribution of data is good, but these global statistics don’t give enough information to determine how a point sits with its neighbours.
It’s quite common to use k-NN for removing outliers based on this idea, but then the usual caveats about dimensions apply: what makes the curse of dimensionality cursed (ok, one thing) is that distance measures have progressively less meaning as d increases: everything is just far away. Also, these approaches can be expensive because lots of distances between points need to be taken.
Anyway, I was curious enough last night to see if a k-NN approach could be implemented in FluCoMa and how it would do for your test problem here. What I opted for was a scheme called ‘Local Outlier Probabilities’ that we can implement around a kd-tree; it’s nice because it gives results – an outlier probability per point – on a predictable 0-1 scale, which many other k-NN based schemes don’t.
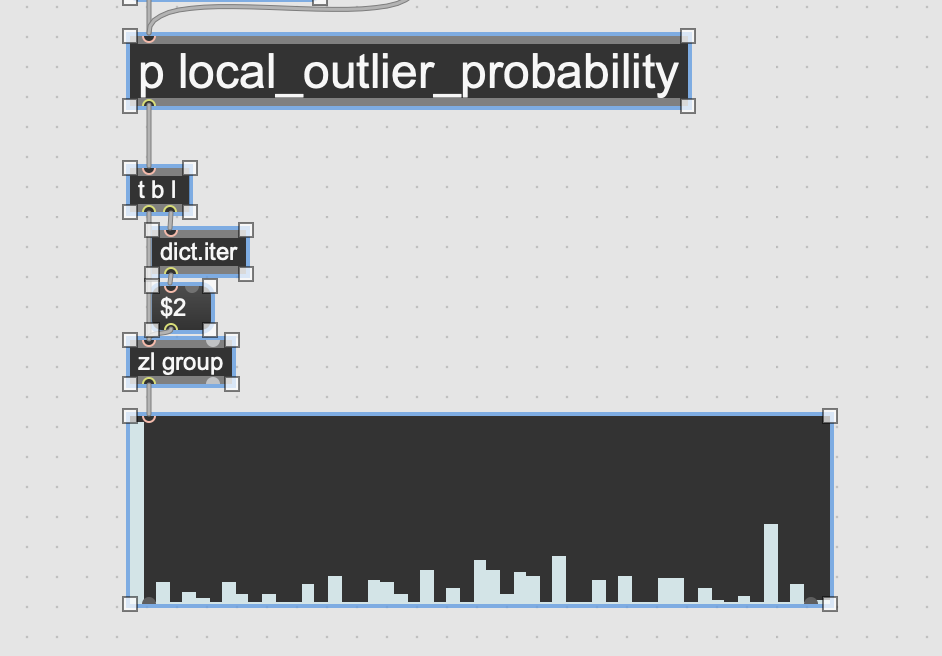
It works by trying to gauge how dense the area around each point is by doing some basic statistics on the k-nearest distances between points. Seems to work OK, even on your 104-d data
In that [multislider] is the 0-1 probaility for each point in your dataset, no other preprocessing. That 0th point is nice and clearly more outlying than the others.
It also seems a lot more understandable than I thought it would. Don’t get me wrong, I don’t think I could connect the dots of that paper and a bunch of Max code, but walking through it all, I can follow what’s happening.
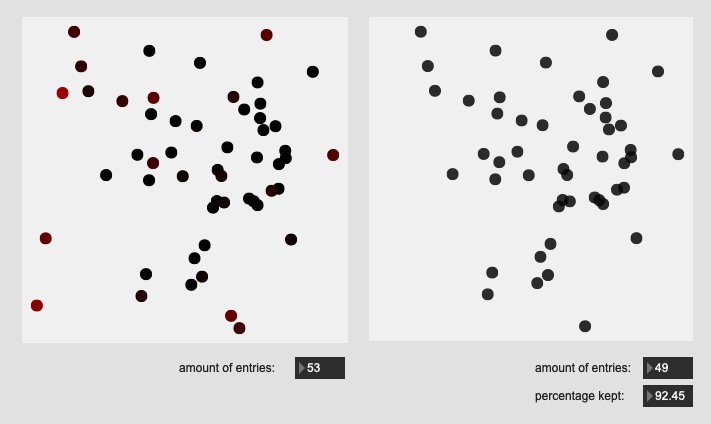
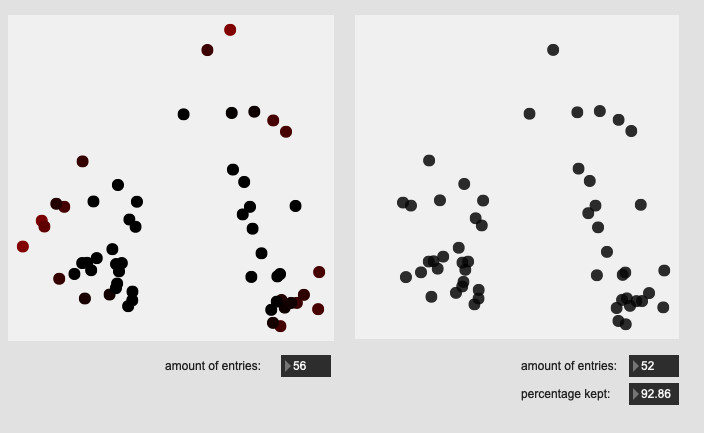
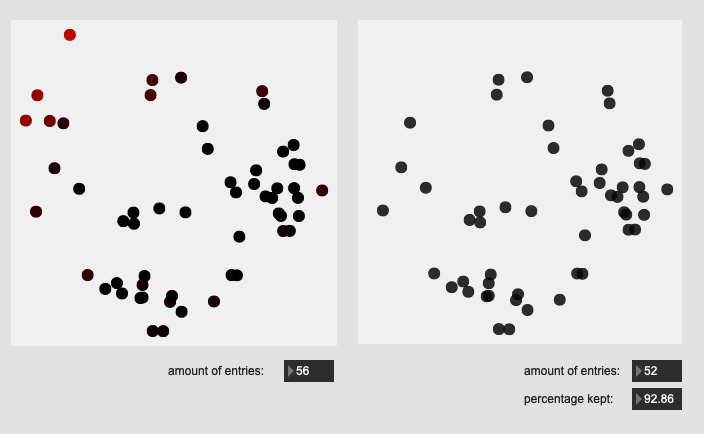
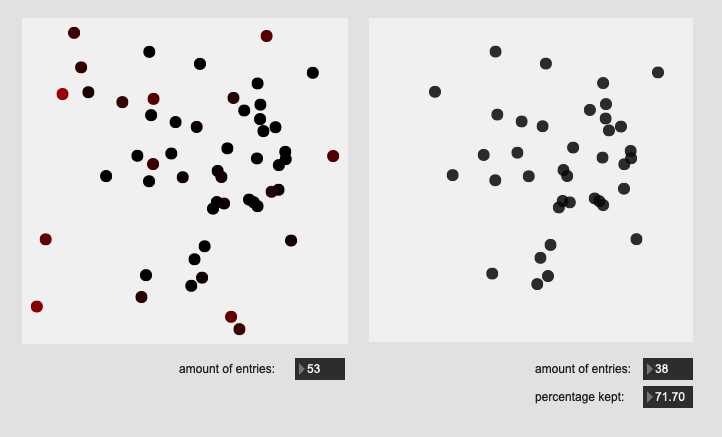
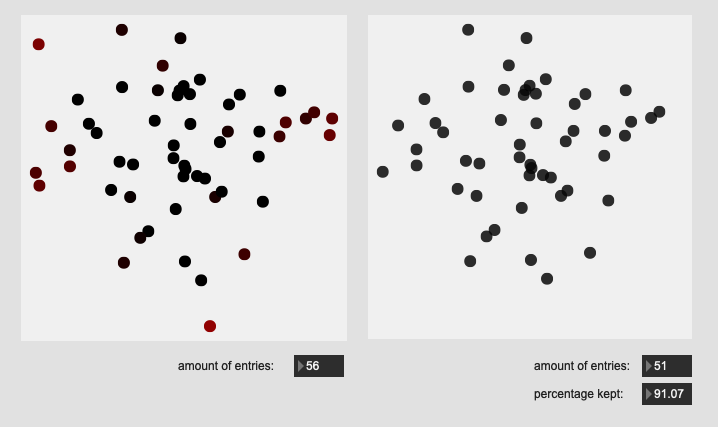
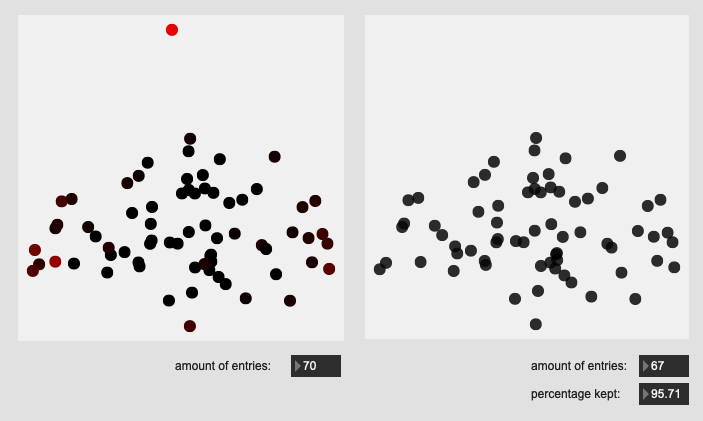
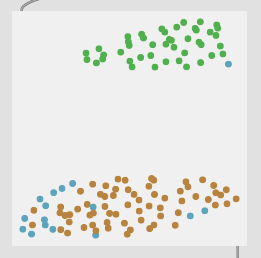
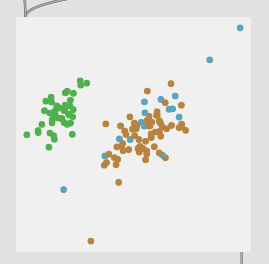
Here are some results on more real-world datasets where each class represents a bunch of actually similar sounds. The dataset above is one of these but with a single hit from a very different sounding class to act as an obvious outlier.
I’m really pleased with the (visual) results. I look forward to testing this across a few ongoing researchstrands.
All of these are doing the outlier maths on the 104d space, then applying plotting and removing points from a PCA 2d projection.
I’ve yet to do testing to see how this effects classification accuracy, or the ability to “interpolate” between classes, but it looks like a reasonable amount of data to prune, and clustering still looks decent enough.
So a couple of follow up questions based on the patch/code.
With regards to the numneighbours for the outlier probability computation. You say:
Size of neighbourhood for measuring local density. Has to be eye-balled really: there’s a sweet spot for every dataset. Too small, and you’ll see ‘outliers’ everywhere (because it finds lots of small neighbourhoods), too big and performance starts to degrade.
Is the only danger of “too big” being a computational hit? In looking at the code, it looks like this parameter just caps the amount of neighbors to search by, so if numneighbours > entries it does nothing. In my case I rarely go over 100 entries (per any given class) or a couple hundred in a really freak case, so would it be unreasonable just to have that value topped out at a couple hundred?
(I can imagine this mattering a lot more if you have tens of thousands of points you are trying to sort through)
In playing with the tolerance, I’m unsure what the impact on the outliers as compared to the thresholding being applied at a fluid.datasetquery~ step.
As in, making the tolerance smaller gets more selective at the algorithm stage, with a similar thing happening at the query stage. Is there any benefit to messing with tolerance at all vs just being able to tweak the thresholding afterwards?
Here’s a comparison of the same data with different tolerance and < sttings, giving the same exact end results.
If these are computationally the same, I’d be inclined to leave the tolerance as a fixed value, and use the more precise thresholding afforded by < to to the pruning after.
So for the examples above, I’m applying the outlier maths to the full dimensionality, and then visualizing that in a 2d space.
Now I’m still experimenting with the accuracy of this in general, but I found I was getting slightly better classification results using PCA’d data to feed into the classifier. Similarly, I got better results for class “interpolation” on the dimensionally reduced data.
In a context where there will be data reduction happening, is it desirable (as in a “best practice”/“standard data science”) to apply this outlier rejection on “full resolution” higher-dimensional space, or the “actually being used in classification” lower-dimensional space.
I can smell an "it depends"™ a mile away here, but just wondering if there’s any established way of doing this and/or a meaningful reason to do it one way vs the other.
Somewhat tangentially, a comment you made towards the bottom of the patch
Not implemented, but once fitted one could use this to test new incoming datapoints for outlier-ness in terms of the original filtted data
made me think of something like this potentially having implications when trying to “interpolate” between trained classes. I did a ton of testing in this other thread, but one of my original ideas was to compute the mean of each class, then use an individual points distance to that mean to indicate a kind of “position” or “overall distance”, but that ended up working very poorly.
Part of what seem to make this kind of outlier rejection work is that it’s computed across all the neighbours in a way that doesn’t get smeared/averaged like what I was getting with computing the distance of a bunch of MFCCs/stats to a synthetic mean.
If I were to take two classes worth of data and then figure out the outlier probabilities across all the points (or I guess doing it twice, once per pair?) would it be possible to compute a single value that represents how “outlier”-y a point is relative to one or the other class?
In short, is there a magic bullet to “interpolation” buried in this outlier probability stuff?
Does something bad happen if you arbitrarily create gaps in a fluid.dataset~/fluid.labelset~? As in, if I use this outlier rejection stuff, and remove a bunch of entries, so I now have a dataset with non-contiguous indices, does that mess around with classification/regression/etc…
I wouldn’t think so, but then again I’ve never “poked holes” in a dataset that way.
Yes – I would think that for more complex clumpings of data it will matter more. Like if you’ve got a bunch of clear bunches and stuff scattered between them and only want to get rid of the scattered stuff, you’ll need to tune.
More broadly, yes there’s a CPU hit associated with more neighbours too, especially in higher dimensions, and (according the the graphs in the paper), accuracy steadily goes down once you’re past some sweet spot for the data in question (but not abruptly).
So, if you can live with the CPU cost and it still does what you need for a given job, don’t sweat it, otherwise use for finer-tuning.
Is there a benefit of adjusting both toleranceandfluid.datasetquery~ threshold independently?
They’re not completely equivalent because of the non-linearity in the way the final scaling works (clips at 0, meaning you have a class of points that are definitely inliers). However, for practical purposes you can probably usually leave at a value that gives intuitively sensible results for your purposes. As you show, when it’s lower, you get some points marked as possible outliers within the main bunch; sometimes that might be useful for surgical stuff – so, again, perhaps good to twiddle for fine(r)-tuning in difficult cases.
Should outlier rejection happen pre or post dimensionality reduction?
As a rule I’d say pre-, especially if the DR is just being used for visualisation and the actual classification will be done in higher dimensions. Nonlinear DR like UMAP, in particular, is quite liable to reduce the outlier-ness of points at some settings (which you showed above), because it’s trying to preserve the topology of whatever you give it. Because it also uses a kNN for part of its work, the two things could interact in surprising ways.
So, the it depends version: generally before, except when that doesn’t work
Does an approach like this have any useful implications for computing class “interpolation”?
Don’t know. Will need to remind myself of what you’re trying to do there and think more about it. But just have a play in the meantime and come back with Qs.
Can anything bad happen in the fluid.verse with disjointed entries in a fluid.dataset~?
Nope. They’re not actually disjointed (the order of entries isn’t coupled to the IDs).
I’ll experiment and plot more classes to see how it responds to this. Based on what you’ve said, and on the ones I’ve plotted, most of it should be relatively even/clumpy given that, by definition, they are meant to be examples of the same sound.
I have noticed that with some hits (e.g. rim tip), it does more of a sub-cluster-y thing, but still in an overall dense space.
Also sensible.
I’m mainly thinking of what parameters to expose for tweaking since it can be pretty overwhelming, and often somewhat dangerous, to expose a bunch of interconnected and obtuse parameters!
Right now I’m leaning towards exposing all of it in the code/reference, but only mentioning an overall toggle/enable and threshold parameter in a helpfile.
In my case the classification may happen on the DR data, but I think what you’ve said will likely hold true either way.
Was mainly thinking of where this should go in the data processing pipeline, and “near the start” is the answer.
Thankfully I already built a bunch of plumbing to take apart and reprocess data/label pairs from a larger dataset (what a pita!) , so can just slide this into that.
Indeed. That will likely be the first real-world stuff I test with as I suspect (hope) that it will have some meaningful impact there, just by making the “gradient” between what a class is and isn’t more defined. If/when I end up with some concrete questions, I’ll be sure to bump the appropriate thread!
Is that stuff in sp.tools or something? Would be useful to review, see all the stuff you’ve discovered you need and think about what could be folded into the main distro or a sibling utility package. Obviously we need iter equivalents for dataset and labelsets, maybe group equivalents as well. At least in Max/PD, ergonomic challenges in SC might demand something different.
If this outlier doodad proves useful in the medium term, it might become an external one day too.
I’m certain there’s more efficient ways to do that by not going into coll for the heavy lifting and just doing whatever is needed in dicts, but for me the most confusing/challenging bit was breaking up a fluid.dataset~ into separate chunks based on a fluid.labelset~.
It’s kind of a data uncanny valley/blindspot in the fluid.verse where the fluid.dataset~ is a monolithic thing, but when working with classes (or lots of other use cases), there are subsections of it that carry significance and would be handy to break apart.
Hell, just being able to use a labelset in the context of fluid.datasetquery~ would help a ton, even with hose tricky to parse that object/syntax is. Beats dumping/iterating endlessly!
Absolutely! Could fit into the ecosystem quite nicely.
I took a crack at this. It’s in a subpatcher here. It pulls out all the IDs of each class and collects them into a zl group. Then enables iterating over the IDs and playing them back to hear each cluster. There’s also a subpatcher that additional sorts by distance from the cluster’s mean.
Ah nice, will have a more in-depth look, but it looks like in this case you had a known/finite amount of clusters, so could make somewhere to receive them all.
In my case I wanted it to be more generalizable to deal with an arbitrary amount of classes, so everything had to be iterative/dump-in-place kind of stuff.
I remember running into a similar issue ages ago for merging datasets (also quite faffy), and @weefuzzy came up with an abstraction I still use in a bunch of places (I never remember what I called it!) that just juggles the merging (A+B → C, etc…).
It’s a shame that stuff like fluid.dataset~ didn’t happen earlier in the process to have some of the iteration/breaking-in that other stuff did, as other than having fluid.datasetquery~ (and even with that), it’s really hard to do anything with the data once it’s put in there.
Ok I ran a bunch of varied class trainings I had on hand just to see if anything didn’t work within this context.
Some slightly surprising results.
Firstly, a beat boxing corpus, which has quite a lot of variety within each hit (much more so than the snare hits). The amount of hits per class is also quite a bit smaller.
I’ve yet to do any qualitative testing with this, so not sure how this impacts the accuracy/matching at all as I’ve just been staring at plots and massaging numbers. I’m curious with sounds like this that have a lot of natural variance if it’s better to prune it down aggressively or little at all. I’d believe either.
I was trying to get a bit of variety here as you don’t always line up the stick in the same spot, which I suppose is represented in the little cluster islands, but one of them is right out there!
So my overall takeaway here is that maxing out numneighbours seems to work out already for the most part here. At least across the types of material I’m testing here.
I will check it on some other sound sources (actually quite curious how the cymbal stuff behaves as that’s a quite different contour than all these “hits”) and then do some actual accuracy testing with things like the beatboxing and rimshot hits where the “class” is actually quite varied in how it can sound. So curious to see if keeping an overall tighter cluster works for the training, or if it’s better to have a larger, perhaps sloppier, representation.
I see some of this inquiry leading back towards ideas of regularisation and perhaps quick/dirty data augmentation to perhaps address any funny business, but one rabbit hole at a time!
Couldn’t help myself. Here are some cymbal classes.
(it’s worth mentioning that I’m still struggling to differentiate three classes from cymbal audio. I can get any combination of two of classes playing nice, but combining all three gets shitty accuracy)
It’s not as straight forward to swap out al the plumbing, but just looking at the pitch confidence for each of the same hits (as well as the mean), and there’s definitely a bigger difference there:
Image is kind of small so the relevant deets are:
Bow mean: 0.107778
Bell mean: 0.221442
Edge mean: 0.068012
From the look of the distribution I likely wouldn’t trust that single dimension to carry the weight of it, but it does look like it does capture that variance.
But what is a lowly single descriptor to do in the face of 104d of MFCCs/stats? I would imagine that a classifier trained on 105d is unlikely to behave very differently, particularly given that pitch confidence is 0. to 1.
I guess I can try and come up with a separate recipe differentiate these hits more precisely. MFCCs does seem to capture the difference between bell and bow quite well (as well as seeming to work across most other sounds I’ve tested it on).