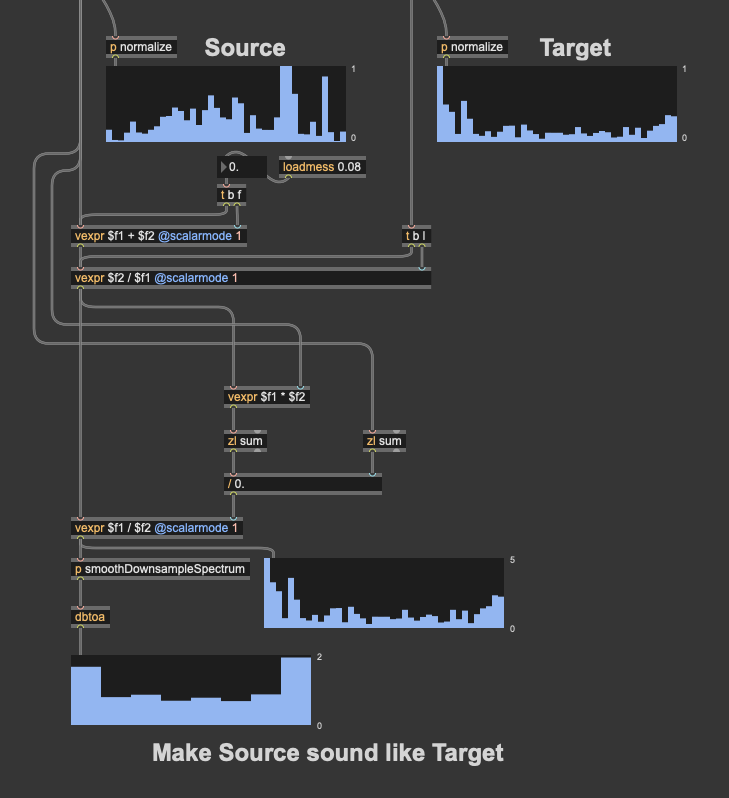
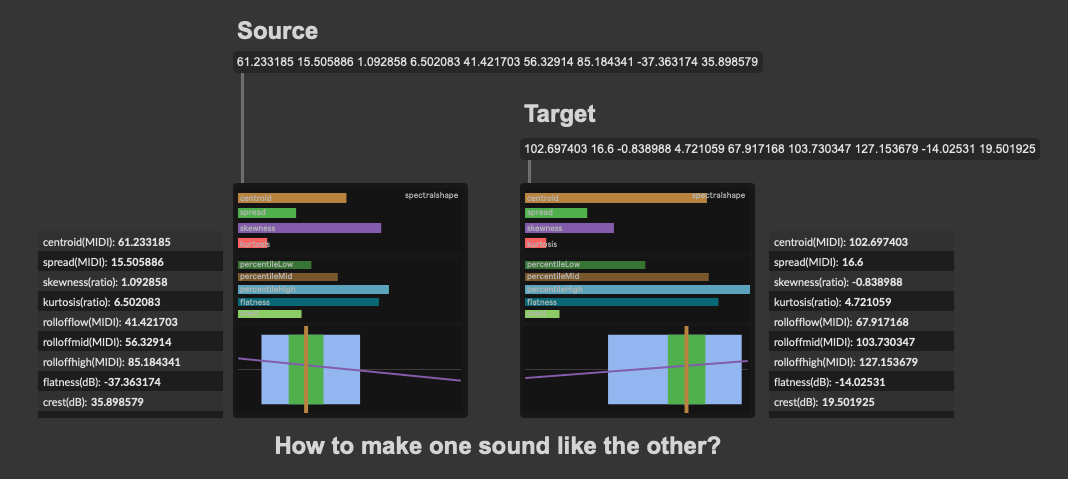
Ok, did some more testing in context.
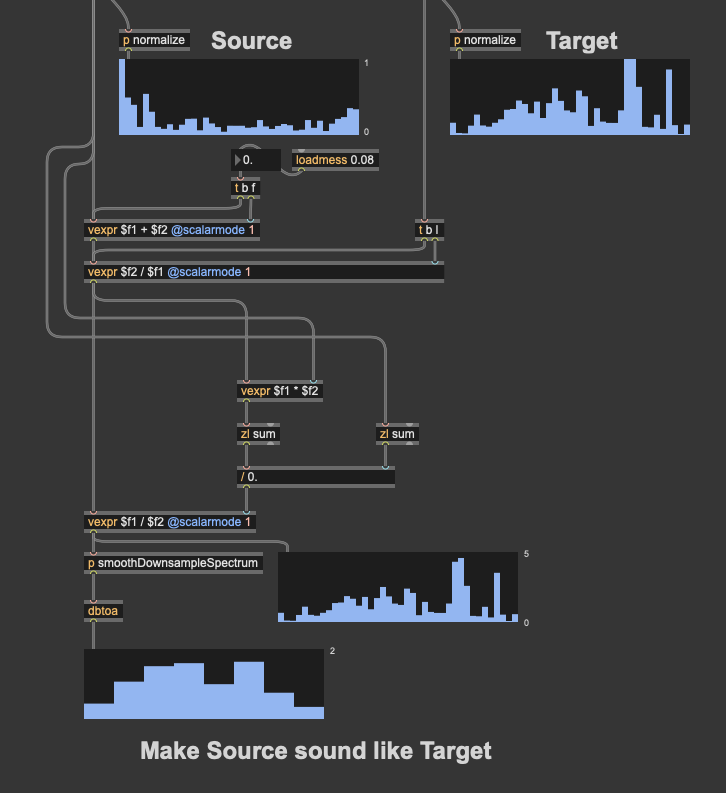
Since I’m querying based on on descriptors, for the most part, the source and target are kind of similar, so fairly mild filters are produced.
Things like these:
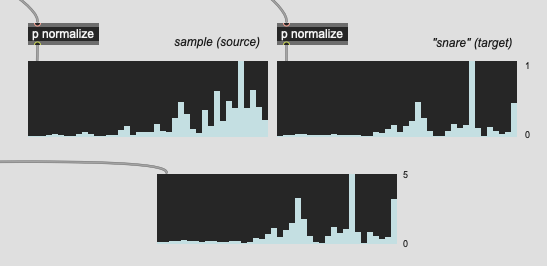
(the normalization here is for display purposes only)
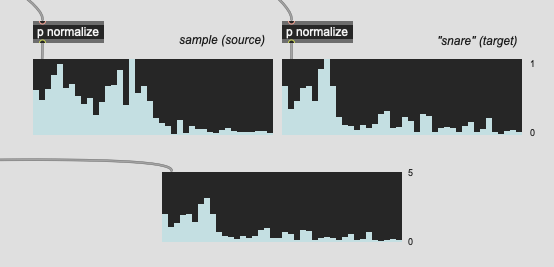
Since the corpus is finite, however, it means that sometimes I get stuff like this:
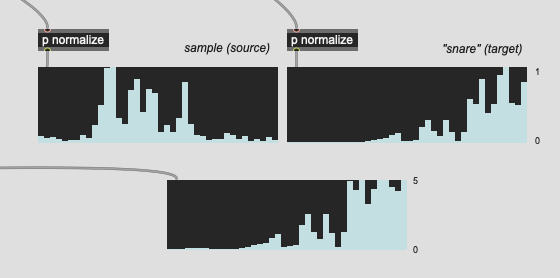
Where I have a linear amplitude (per band) of like 9.0, which is pretty chunky. I’ve cracked up the regularization, but I’m not sure what the limit to “a little bit” is, so the highest I’ve gone is 0.50, which is waaaay higher than the 0.08 I was initially using. Don’t know if this starts to fuck the numbers too much at some point or if there is such a thing as overregularlization.
So my options are regularize more and/or clip the compensation filter, but I’m thinking that I may want to try to compensate spectral shape, but decouple it from the amplitude compensation.
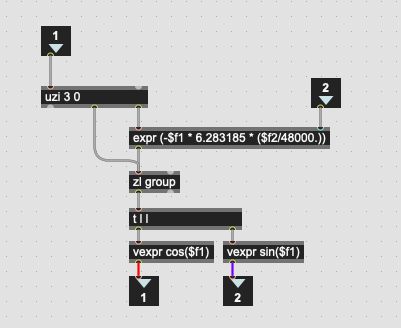
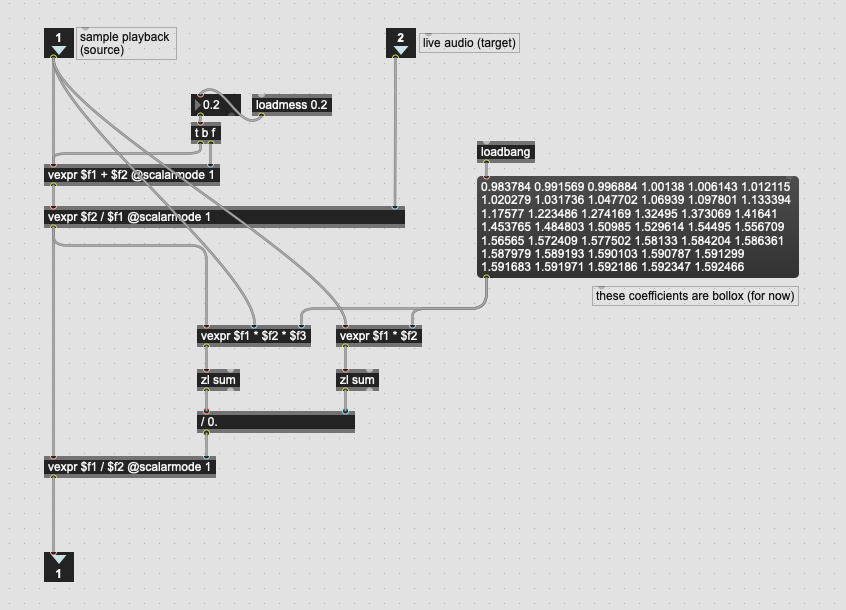
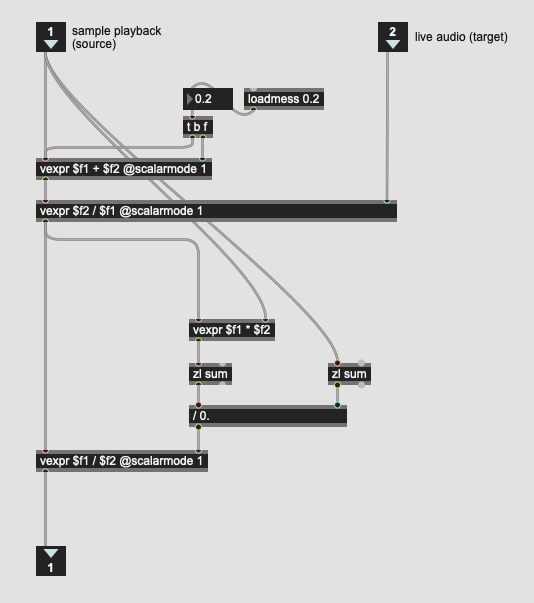
The last version of the maths that @a.harker posted estimates the loudness of the playback with and without the applied filter, weighted by the k-weighting, which I guess includes an overall loudness compensation already?
If I want to remove the loudness compensation part of that filter, would I then normalize the resultant filter in a loudness-weighted way (doing something like maxgain + an additional pass of k-weighting… weighting) to get a filter shape that would be the same loudness as if the filter shape wasn’t applied? Then do loudness compensation in a completely separate way.
I tried a couple of permutations of this, but I kept running into a weird/crazy bug that I’ve seen with vexpr a lot over the years, where I get stack overflows without any feedback. defer seems to fix the problem, which leads me to believe that under certain circumstances vexpr doesn’t like getting numbers from a high-priority thread, but I’ve never been able to isolate this problem (even though I can 100% reproduce it in a larger patch). All that is to say, it’s been tricky figuring out the normalization step as half of the things I try result in a stack overflow.