On a semi interesting note here, both actually speed up with the fully separated timing. So the ratio is slightly better, it’s still only by a factor of 0.3
This is the “bad” timing method for 10k/8d:
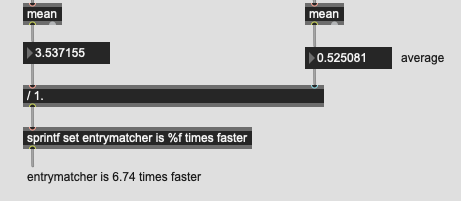
This is the “good” timing method for 10k/8d:
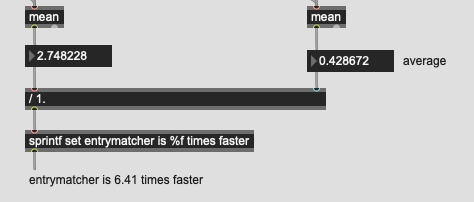
I guess we’ll see in due time, but I’m curious if this holds true as you go smaller. Like does it only start becoming equal around 10k?
Perhaps there’ll be an algorithmic sweet spot that below a certain amount of points brute force is faster, then it gets into KDTree land, with perhaps something above that (that maybe isn’t super useful for corpora-level numbers).
I’m specifically thinking of an immediate/obvious use case for me being the time-travel/prediction stuff where I want to find the nearest distance on a pre-trained set of data asap, before moving on to more wiggly/complex querying. At the moment my test corpus for this has been <1000, but that will likely change when I build the proper version of that. It would still be in the few thousand range though, at most.