Fundamentally it will be “short sounds” in on the left, and “long sounds” out on the right.
But I think I was thinking about this incorrectly (and likely still am). I was trying this fork of the process as a way to semi-objectively be able to assess the efficacy of the PCA->UMAP pipeline (for this kind of material) by having the same pipeline/statistic, and importantly fits on each side.
BUT
I think what actually need to happen is to have the best set of descriptors/stats (as determined by PCA->UMAP) for the teeny/tiny samples as the input, and then the output being a different set of descriptors/stats which includes parameters which are not possible in the short time window (hence the reason for doing this in the first place). So the longer windows would likely have better data for some vanilla stuff, but should also include things which have richer morphological descriptors/stats. So perhaps having more derivatives (or perhaps no derivs at all on the short windows), perhaps having all frames of loudness-based descriptors rather than statistical summaries. Including custom temporal descriptors like time centroid, “timeness”, or stuff like what @balintlaczko was doing where the relationship between the attack portion and the sustain is a descriptor too.
So the idea would be to see if whatever best represents the shrimpy samples could be correlated/regressed with the actual richer, more meaningful, analysis that’s possible on the longer time scale.
In either case, the amount of dimensions on either end is quite variable as it’s going through PCA->UMAP to get there.
I’m also hoping to then have some kind of weighted comparison when querying for samples and such where (potentially) the shorter analysis window is weighted more heavily as it’s “real” and “measured”, whereas the longer window is taken into consideration, but only partially as it’s predictive/regressed. But one problem at a time.
///////////////////////
p.s. all of the main FluCoMa crew (@weefuzzy, @jamesbradbury, @tedmoore) have workshop specific suffixes still in their display names (e.g. “tedmoore Oslo Workshop”). I’m always surprised when I the email notification as that’s what shows up first in the text.
I’d be curious to hear what your criteria are for this!
When training a neural network it can be useful to try to imagine what relationship the neural network might be able to learn. So in your case here, if the inputs are stats of the raw descriptors and the outputs are that plus the stats of the derivatives, that might be very hard for the neural network to learn to predict. The inputs will just have no sense of differences across time.
Maybe it could get a decent guess of some derivative based on the min and max (as in, if the range is very big, there must be some change happening), but my gut says that’s tenuous.
It might be possible if the dataset is very particular, such as, if in a dataset the high sounds are always static (low mean derivative) and the low sounds are always changing (higher mean derivative), then maybe a neural network could learn to just predict higher mean derivative when the pitch is lower and vice versa. The problem is that as soon as you try to put in other sounds, the neural network will give poor predictions.
As above. Trying to reason about what relationship a neural network might be able to learn may be a useful guide here.
If you have the longer analysis window, no need to include the short analysis window! (Since you were trying to predict the longer one anyway!?) However, what could be useful is to use the two in coordination as in, the attack portion and a longer portion as you mention above.
Well, wanted to look at numbers seeing if it was “correct”, and how often that was the case. Rather than just trying an arbitrary set of descriptors and going “hmm, I guess that’s slightly better?”. Mainly cuz each new analysis pipeline still takes me ages to set up, so I can’t easily pivot between radically different sets of descriptors/stats to compare a plotting.
In this case they be completely different descriptors/stats. What I’m thinking, at the moment, is running a fresh PCA/UMAP on each pool of descriptors. So it may be that the dimensions may have no overlap whatsoever between the two ends. In addition the longer analysis may include more initial dimensions too.
So the short window may have mean of loudness, std of MFCC3, pitch confidence (,etc…) and the long window may have mean of deriv of peak, time centroid, skewness of pitch(, etc…).
My original original idea was to just have a classifier rather than a regressor such that I would have an accurate analysis of the input sound, and then “some kind of idea” of what the rest of the sound may be based on the nearest match in the pre-analyzed corpus.
The whole reason for this is that I want to do it in realtime, and don’t have 100ms to wait around for the the longer analysis window. So the goal is to take a meager 256 sample analysis, and get some better info out of it than I can presently.
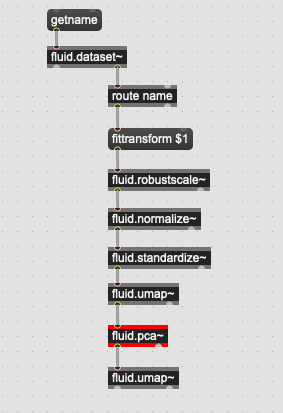
Basically revisiting the PCA->UMAP part of my processing chain now, and it’s super handy to know the variance from the fittransform output, though it’s less clear how to arrive at something like >95% programmatically (without risking stack overflow).
Essentially I want to have all my data->PCA->UMAP “verticals” (i.e. “loudness”, “timbre”, etc…) move forward with 95% coverage from PCA without having me having to stop and massage the numdimensions for each corpus.
Not as it stands – obviously the current nightlies break all the outlets, and the patch was a huge mess anyway. But just getting the cumulative explained variance is simpler anyway. I’ve put a verbose patch at the bottom – no risk of overflow needed
I’m not sure what you mean here. What’s a ‘vertical’ for you? Also, I don’t quite get how you avoid massaging the number of dimensions – isn’t that the point of this exercise?
Also a lot smarter that way. I was initially thinking doing fittransform → [> 0.95] → [counter] → numdimensions and just looping that until it was true.
Not sure what the name for it would be, but at the moment I have independent processing chains for each macro-descriptor (e.g. “loudness”, “timbre”, etc…), so each has its own standardization/reduction, and each has a different (and arbitrary, while I’m tweaking parameters) amount of initial dimensions, so didn’t want to have to dive into massaging the numbers manually for each change I make upstream (i.e. type of descriptor, amount of stats/derivs, etc…).
Be aware that by not naming the fluid.pca~ instances and instead fitting twice (as far as I can work out), you’re potentially doing much more computation than you need to: fitting is much more costly than transforming for PCA.
I think I’d take some more convincing that needing to slice here is as bad as all that. I’m certainly not on board with the idea of only reporting the explained variance for fit and not fittransform.
In this case this is only happening on the corpus-creation side, so cpu usage isn’t that big of a concern. Keeping them unnamed just means I don’t have to #0/— if I want to abstract it later, so the cpu/time is definitely worth the tradeoff.
At the moment fit doesn’t report it at all, it instead sends a bang, ala oldschool interface. So there’s not really parity between fit and fittransform already.
The issue is more that fluid.pca~ uniquely, and specifically breaks the ability to just being able to chain processors.
Obviously this is an absurd processing chain, but there would be no indication that this one object/process needs to be treated differently.
Also, it would keep with the paradigm that the ‘left outlet is for chaining’ and the ‘right outlet is for other stuff’. Amount of variance seems to me to be squarely in the “other stuff” category.
At the moment fit doesn’t report it at all, it instead sends a bang, ala oldschool interface. So there’s not really parity between fit and fittransform already.
So it doesn’t. Which turns out to be because fit doesn’t ‘know’ (or care) about the number of dimensions. Fitting PCA is always a N->N mapping. Which is, IMO, all the more reason not to remove it from [fit]transform or, more generally, sacrifice the idea that messages might return some value as well as filling some output container .
It would also bring into parity with fluid.mlpregressor~ which uses the fit message as a way to query how well it fit.
More than anything, breaking the nameless chaining with fittransform is a bummer since there’s no way to know that this object has a different/specific implementation when processing things as you can literally just chain any of the other objects.
I was gonna post this as a separate thread thinking there may be a bug, but it’s possible there’s something in your subpatch that doesn’t like different preprocessing?
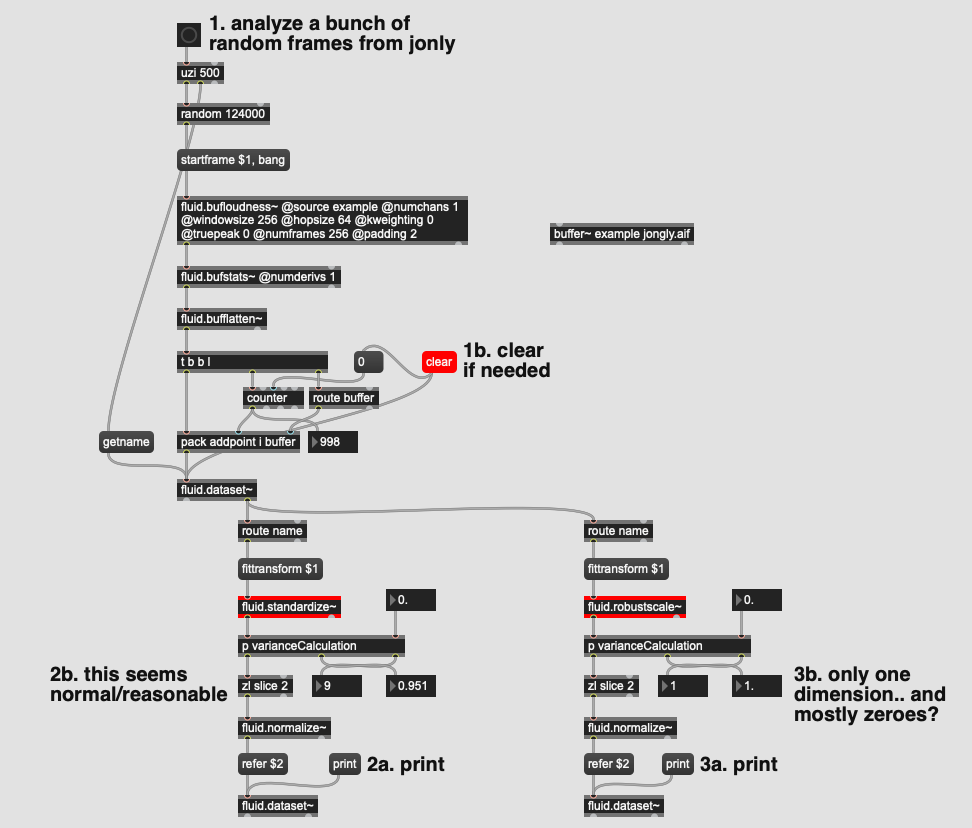
Basically if I go: loudness -> *standardize* -> PCA -> normalize
Everything is happy pappy.
However, if I instead go: loudness -> *robustscale* -> PCA -> normalize
I get some fucked looking data (basically it tells me 1d is enough to get 100% coverage, and that dimension consists of almost exclusively 0).
Something* about that robust scaled data makes PCA explode as a process. Exactly the same happens if I process it using sci-kit learn’s PCA in Python: the first singular value is absurdly huge (~4e16) and this swamps everything.
[*] Something turns out to be an extreme value of -1.1121164977963008e+16, which would explain it
I initially thought that my input data was super outlier-y and when removing all that the algorithm was like “most of your signal is zero, bro”, but this random/jongly example shouldn’t produce weird outliers like that as it’s random(ish) selections.
Makes me a bit dubious of robustscale as now I gotta double-check what I get further down the line.
On a whim I decided to try leaving out the true-peak channel for the loudness calculation ([fluid.bufstats~ @numchans 1 @numderivs 1] instead in the above example) and it’s not blowing up PCA. In fact, if I do only true-peak stats, it blows up.
This is what print on the first dataset looks like if I do @numchans 1 @startchan 1:
Ok, it’s a scaler bug when the range of a column is zero. In the case of robust scale it can be hard to spot up front because the range in question will be the difference between the selected quantiles (so a col could have valid min / max but mostly zeros and end up like this).
Fix in process.
Meanwhile, question: do you find, empirically, that there’s much value in using both average loudness and peak together? They will be very strongly correlated (as will most of the derived stats), so it seems like you’d end up producing quite a lot of redundant data.
Most definitely not. I was just playing with settings and for the sake of simplicity it’s easier to have the fluid.bufstats~ object be the same across the board. If/when I can just @select loudness I’ll likely never see a true-peak again in my life!
Also in testing today, fluid.dataset~ won’t take a name that isn’t a symbol in the first place. It reports: fluid.dataset~: Shared object given no name – won't be shared!
Which is odd as it’s possible for it to have no name now anyways.
But since the name has to be a symbol, perhaps the fluid.datasetprocess~ objects can do a type check on expected dataset name inputs and if it sees a float (which can only come from the output of fittransform $1-ing fluid.pca~, it can ignore the float part of the output and interpret fittransform u235352353 0.9352533 as being a <command> <buffer> <unrelated info which I can ignore>.