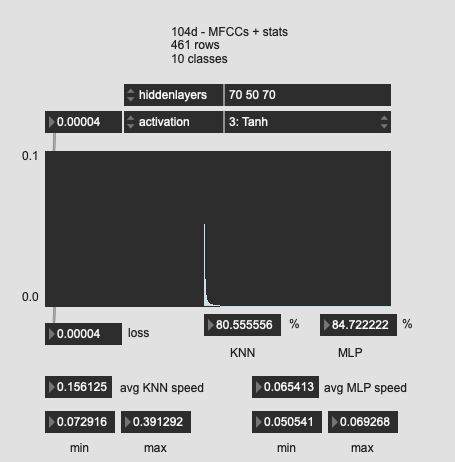
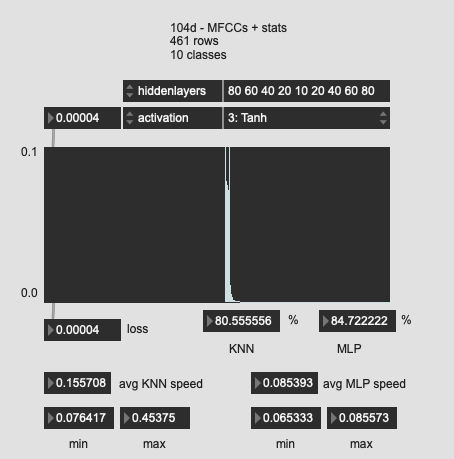
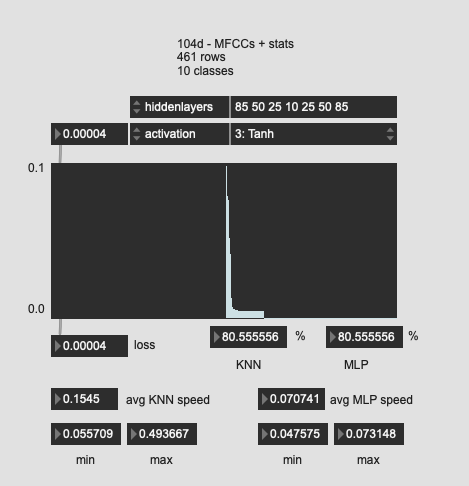
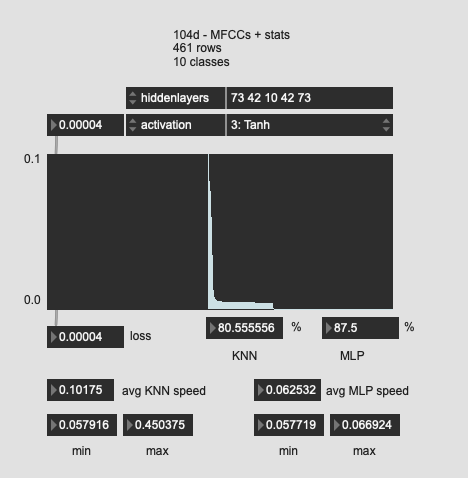
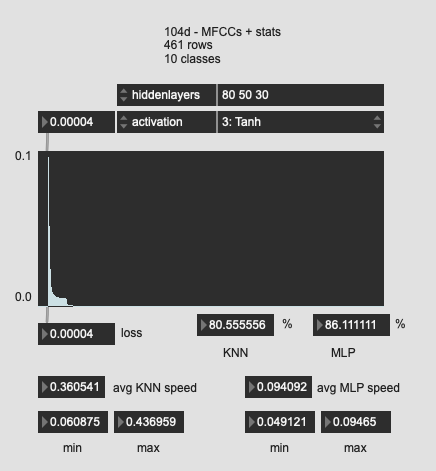
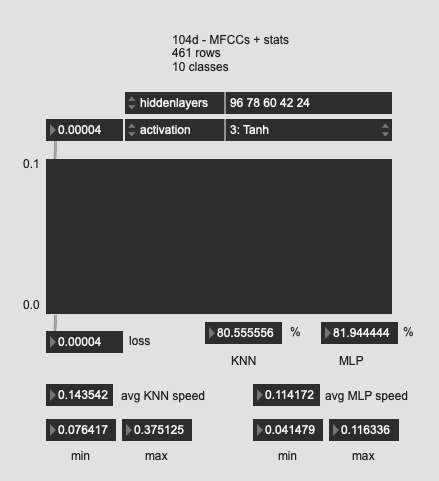
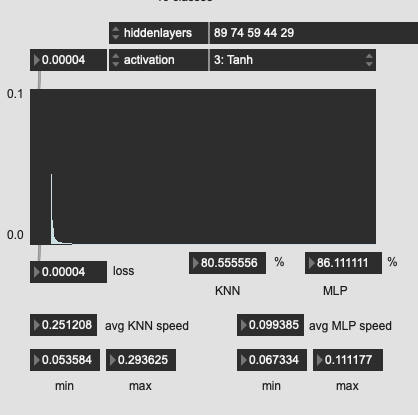
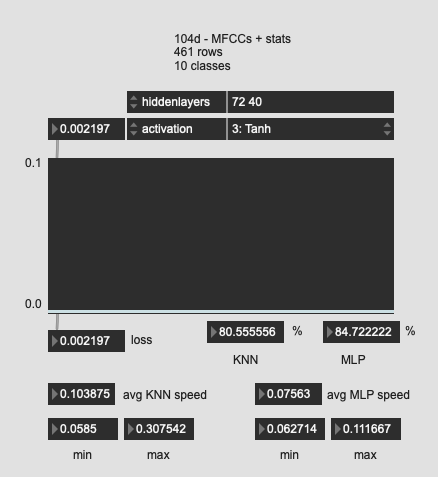
Tried a few more oddball shapes here, with much worse results. So I guess the “funnel” is the way to go?
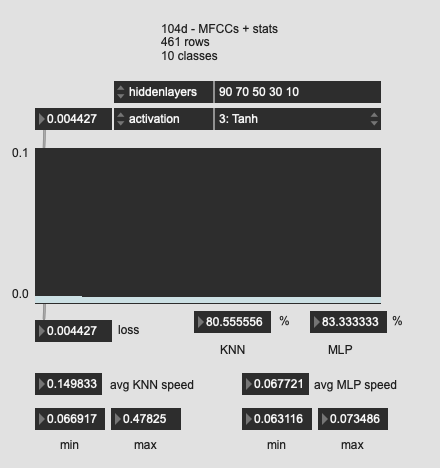
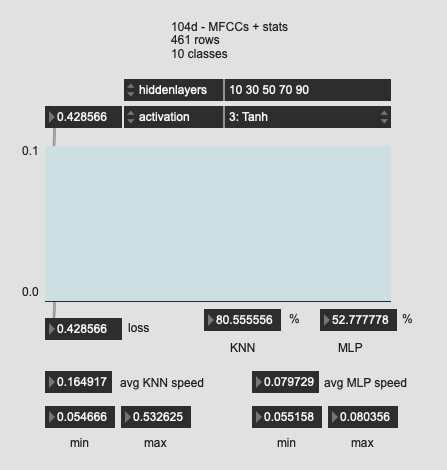
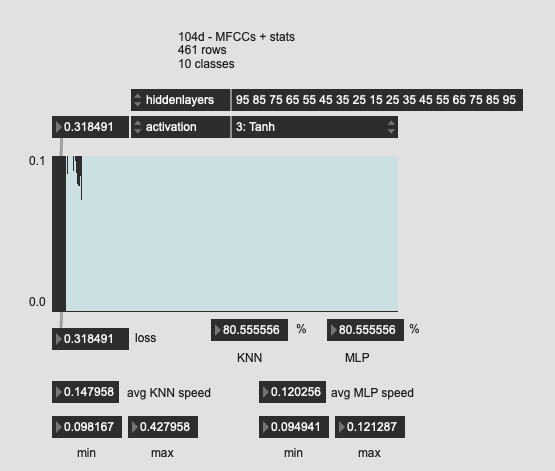
Perhaps worth mentioning that when trying to fit this last one (with the super long network structure I got an insta crash (Max just disappeared, no pinwheel (that I remember)).
crash report:
classifier crash.zip (17.9 KB)
relevant bit (I think, it’s from the crashed thread at least):
12 fluid.libmanipulation 0x1320628dc Eigen::DenseStorage<double, -1, -1, -1, 1>::resize(long, long, long) + 80
13 fluid.libmanipulation 0x1322763d8 Eigen::internal::product_evaluator<Eigen::Product<Eigen::Transpose<Eigen::Matrix<double, -1, -1, 0, -1, -1> const>, Eigen::Transpose<Eigen::Matrix<double, -1, -1, 0, -1, -1> >, 0>, 8, Eigen::DenseShape, Eigen::DenseShape, double, double>::product_evaluator(Eigen::Product<Eigen::Transpose<Eigen::Matrix<double, -1, -1, 0, -1, -1> const>, Eigen::Transpose<Eigen::Matrix<double, -1, -1, 0, -1, -1> >, 0> const&) + 108
14 fluid.libmanipulation 0x132276048 void Eigen::internal::call_dense_assignment_loop<Eigen::Matrix<double, -1, -1, 0, -1, -1>, Eigen::Transpose<Eigen::CwiseBinaryOp<Eigen::internal::scalar_sum_op<double, double>, Eigen::Product<Eigen::Transpose<Eigen::Matrix<double, -1, -1, 0, -1, -1> const>, Eigen::Transpose<Eigen::Matrix<double, -1, -1, 0, -1, -1> >, 0> const, Eigen::Replicate<Eigen::Matrix<double, -1, 1, 0, -1, 1>, 1, -1> const> >, Eigen::internal::assign_op<double, double> >(Eigen::Matrix<double, -1, -1, 0, -1, -1>&, Eigen::Transpose<Eigen::CwiseBinaryOp<Eigen::internal::scalar_sum_op<double, double>, Eigen::Product<Eigen::Transpose<Eigen::Matrix<double, -1, -1, 0, -1, -1> const>, Eigen::Transpose<Eigen::Matrix<double, -1, -1, 0, -1, -1> >, 0> const, Eigen::Replicate<Eigen::Matrix<double, -1, 1, 0, -1, 1>, 1, -1> const> > const&, Eigen::internal::assign_op<double, double> const&) + 40
15 fluid.libmanipulation 0x132275b34 fluid::algorithm::NNLayer::forward(Eigen::Ref<Eigen::Matrix<double, -1, -1, 0, -1, -1>, 0, Eigen::OuterStride<-1> >, Eigen::Ref<Eigen::Matrix<double, -1, -1, 0, -1, -1>, 0, Eigen::OuterStride<-1> >) const + 136
16 fluid.libmanipulation 0x132275880 fluid::algorithm::MLP::forward(Eigen::Ref<Eigen::Array<double, -1, -1, 0, -1, -1>, 0, Eigen::OuterStride<-1> >, Eigen::Ref<Eigen::Array<double, -1, -1, 0, -1, -1>, 0, Eigen::OuterStride<-1> >, long, long) const + 344
17 fluid.libmanipulation 0x1322743bc fluid::algorithm::SGD::train(fluid::algorithm::MLP&, fluid::FluidTensorView<double, 2ul>, fluid::FluidTensorView<double, 2ul>, long, long, double, double, double) + 2060
18 fluid.libmanipulation 0x13229ec8c fluid::client::mlpclassifier::MLPClassifierClient::fit(fluid::client::SharedClientRef<fluid::client::dataset::DataSetClient const>, fluid::client::SharedClientRef<fluid::client::labelset::LabelSetClient const>) + 1748
19 fluid.libmanipulation 0x1322b29f8 auto fluid::client::makeMessage<fluid::client::MessageResult<double>, fluid::client::mlpclassifier::MLPClassifierClient, fluid::client::SharedClientRef<fluid::client::dataset::DataSetClient const>, fluid::client::SharedClientRef<fluid::client::labelset::LabelSetClient const> >(char const*, fluid::client::MessageResult<double> (fluid::client::mlpclassifier::MLPClassifierClient::*)(fluid::client::SharedClientRef<fluid::client::dataset::DataSetClient const>, fluid::client::SharedClientRef<fluid::client::labelset::LabelSetClient const>))::'lambda'(fluid::client::mlpclassifier::MLPClassifierClient&, fluid::client::SharedClientRef<fluid::client::dataset::DataSetClient const>, fluid::client::SharedClientRef<fluid::client::labelset::LabelSetClient const>)::operator()('lambda'(fluid::client::mlpclassifier::MLPClassifierClient&, fluid::client::SharedClientRef<fluid::client::dataset::DataSetClient const>, fluid::client::SharedClientRef<fluid::client::labelset::LabelSetClient const>), fluid::client::SharedClientRef<fluid::client::dataset::DataSetClient const>, fluid::client::SharedClientRef<fluid::client::labelset::LabelSetClient const>) const + 96
20 fluid.libmanipulation 0x1322b27e0 fluid::client::Message<auto fluid::client::makeMessage<fluid::client::MessageResult<double>, fluid::client::mlpclassifier::MLPClassifierClient, fluid::client::SharedClientRef<fluid::client::dataset::DataSetClient const>, fluid::client::SharedClientRef<fluid::client::labelset::LabelSetClient const> >(char const*, fluid::client::MessageResult<double> (fluid::client::mlpclassifier::MLPClassifierClient::*)(fluid::client::SharedClientRef<fluid::client::dataset::DataSetClient const>, fluid::client::SharedClientRef<fluid::client::labelset::LabelSetClient const>))::'lambda'(fluid::client::mlpclassifier::MLPClassifierClient&, fluid::client::SharedClientRef<fluid::client::dataset::DataSetClient const>, fluid::client::SharedClientRef<fluid::client::labelset::LabelSetClient const>), fluid::client::MessageResult<double>, fluid::client::mlpclassifier::MLPClassifierClient, fluid::client::SharedClientRef<fluid::client::dataset::DataSetClient const>, fluid::client::SharedClientRef<fluid::client::labelset::LabelSetClient const> >::operator()(auto fluid::client::makeMessage<fluid::client::MessageResult<double>, fluid::client::mlpclassifier::MLPClassifierClient, fluid::client::SharedClientRef<fluid::client::dataset::DataSetClient const>, fluid::client::SharedClientRef<fluid::client::labelset::LabelSetClient const> >(char const*, fluid::client::MessageResult<double> (fluid::client::mlpclassifier::MLPClassifierClient::*)(fluid::client::SharedClientRef<fluid::client::dataset::DataSetClient const>, fluid::client::SharedClientRef<fluid::client::labelset::LabelSetClient const>))::'lambda'(fluid::client::mlpclassifier::MLPClassifierClient&, fluid::client::SharedClientRef<fluid::client::dataset::DataSetClient const>, fluid::client::SharedClientRef<fluid::client::labelset::LabelSetClient const>), fluid::client::SharedClientRef<fluid::client::dataset::DataSetClient const>, fluid::client::SharedClientRef<fluid::client::labelset::LabelSetClient const>) const + 80
21 fluid.libmanipulation 0x1322b255c _ZNK5fluid6client10MessageSetINSt3__15tupleIJNS0_7MessageIZNS0_11makeMessageINS0_13MessageResultIdEENS0_13mlpclassifier19MLPClassifierClientEJNS0_15SharedClientRefIKNS0_7dataset13DataSetClientEEENSA_IKNS0_8labelset14LabelSetClientEEEEEEDaPKcMT0_FT_DpT1_EEUlRS9_SE_SI_E_S7_S9_JSE_SI_EEENS4_IZNS5_INS6_IvEES9_JSE_NSA_ISG_EEEEESJ_SL_SR_EUlSS_SE_SW_E_SV_S9_JSE_SW_EEENS4_IZNS5_INS6_INS2_12basic_stringIcNS2_11char_traitsIcEENS2_9allocatorIcEEEEEES9_JNS2_10shared_ptrIKNS0_13BufferAdaptorEEEEEESJ_SL_SR_EUlSS_S19_E_S15_S9_JS19_EEENS4_IZNS5_ISV_NS0_10DataClientINS8_17MLPClassifierDataEEEJEEESJ_SL_SR_EUlRS1E_E_SV_S1E_JEEENS4_IZNS0_11makeMessageINS6_IlEES1E_JEEESJ_SL_MSM_KFSN_SP_EEUlS1F_E_S1J_S1E_JEEES1N_NS4_IZNS5_INS6_INS3_IJNSZ_IcS11_N9foonathan6memory13std_allocatorIcNS_17FallbackAllocatorEEEEENS_11FluidTensorIlLm1EEEllddldEEEEES9_JS14_EEESJ_SL_SR_EUlSS_S14_E_S1X_S9_JS14_EEENS4_IZNS5_IS15_S1E_JEEESJ_SL_SR_EUlS1F_E_S15_S1E_JEEENS4_IZNS5_ISV_S1E_JS14_EEESJ_SL_SR_EUlS1F_S14_E_SV_S1E_JS14_EEES1Z_EEEE6invokeILm0EJRNS0_24NRTSharedInstanceAdaptorIS9_E12SharedClientERSE_RSI_EEEDcDpOT0_ + 144
22 fluid.libmanipulation 0x1322b1ef8 decltype(auto) fluid::client::NRTThreadingAdaptor<fluid::client::NRTSharedInstanceAdaptor<fluid::client::mlpclassifier::MLPClassifierClient> >::invoke<0ul, fluid::client::NRTThreadingAdaptor<fluid::client::NRTSharedInstanceAdaptor<fluid::client::mlpclassifier::MLPClassifierClient> >, fluid::client::SharedClientRef<fluid::client::dataset::DataSetClient const>&, fluid::client::SharedClientRef<fluid::client::labelset::LabelSetClient const>&>(fluid::client::NRTThreadingAdaptor<fluid::client::NRTSharedInstanceAdaptor<fluid::client::mlpclassifier::MLPClassifierClient> >&, fluid::client::SharedClientRef<fluid::client::dataset::DataSetClient const>&, fluid::client::SharedClientRef<fluid::client::labelset::LabelSetClient const>&) + 360
23 fluid.libmanipulation 0x1322b17a0 void fluid::client::FluidMaxWrapper<fluid::client::NRTThreadingAdaptor<fluid::client::NRTSharedInstanceAdaptor<fluid::client::mlpclassifier::MLPClassifierClient> > >::invokeMessageImpl<0ul, 0ul, 1ul>(fluid::client::FluidMaxWrapper<fluid::client::NRTThreadingAdaptor<fluid::client::NRTSharedInstanceAdaptor<fluid::client::mlpclassifier::MLPClassifierClient> > >*, symbol*, long, atom*, std::__1::integer_sequence<unsigned long, 0ul, 1ul>) + 172