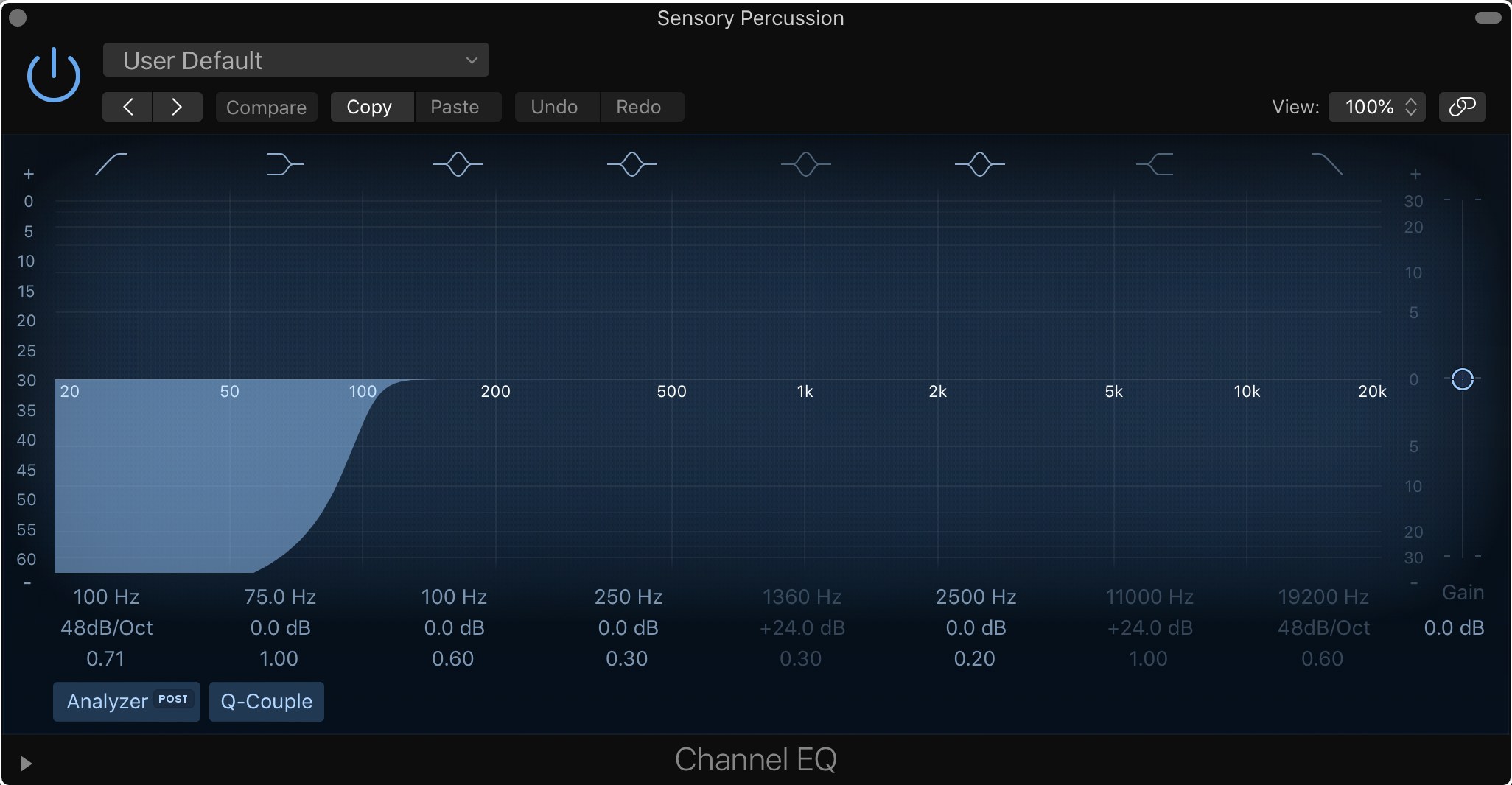
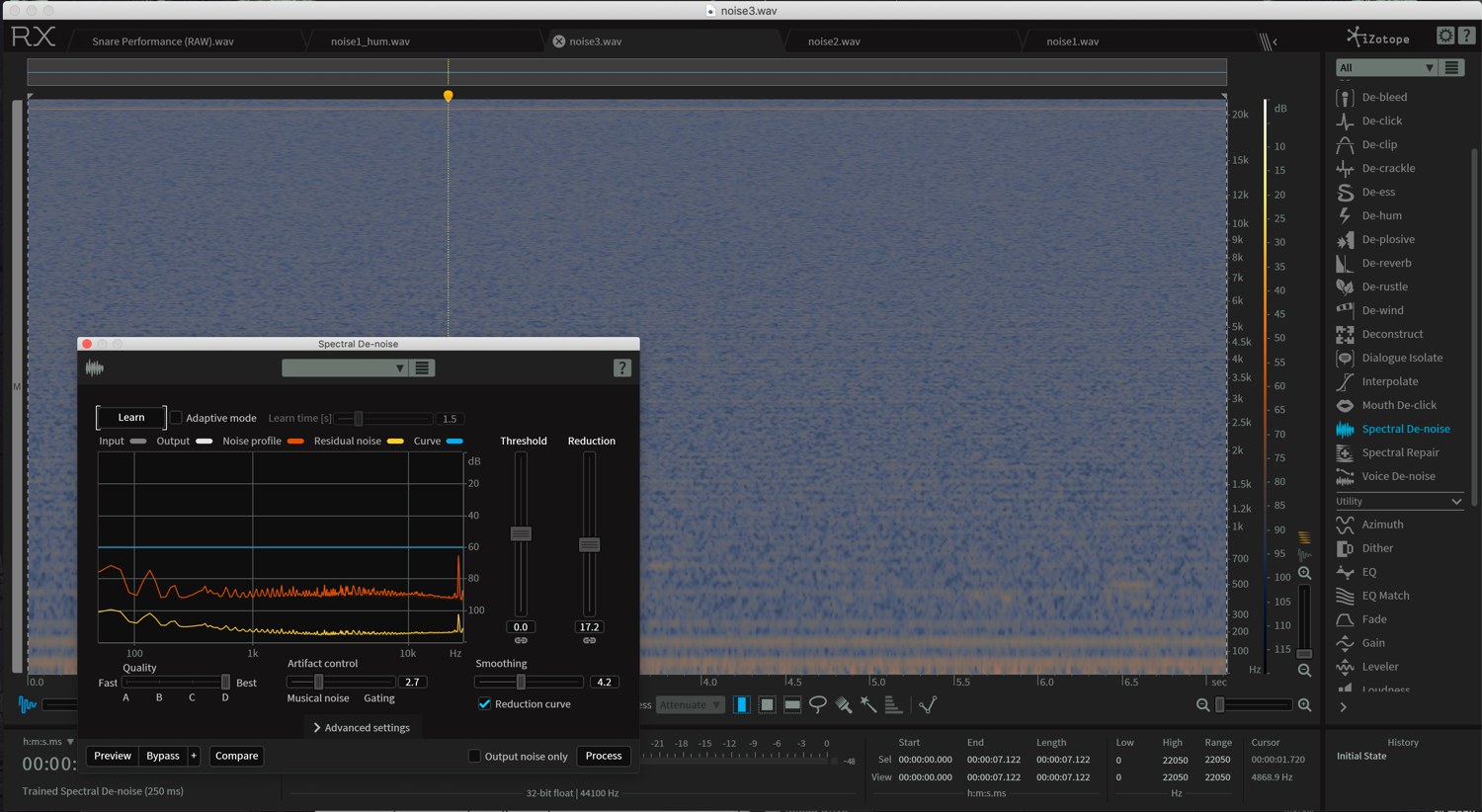
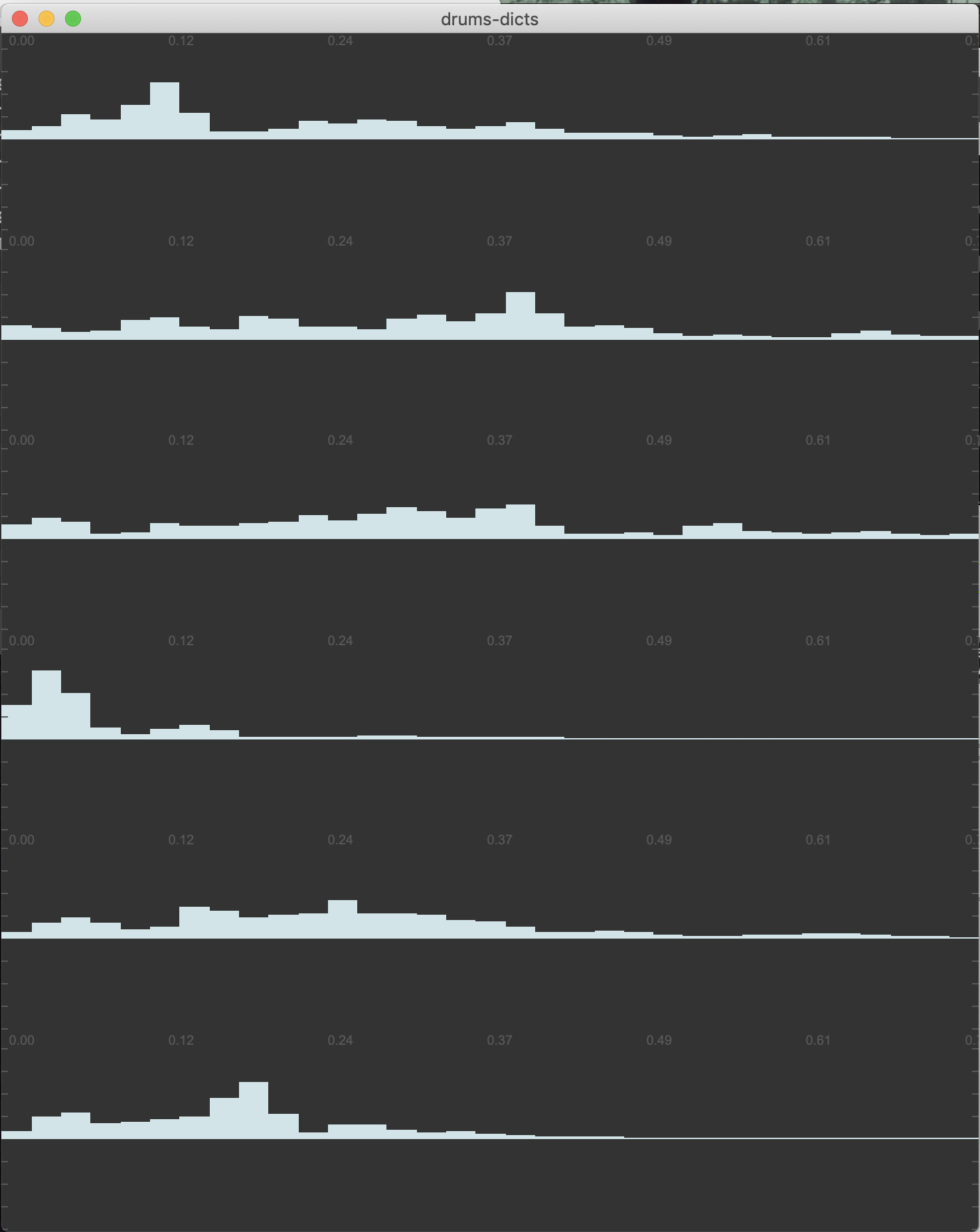
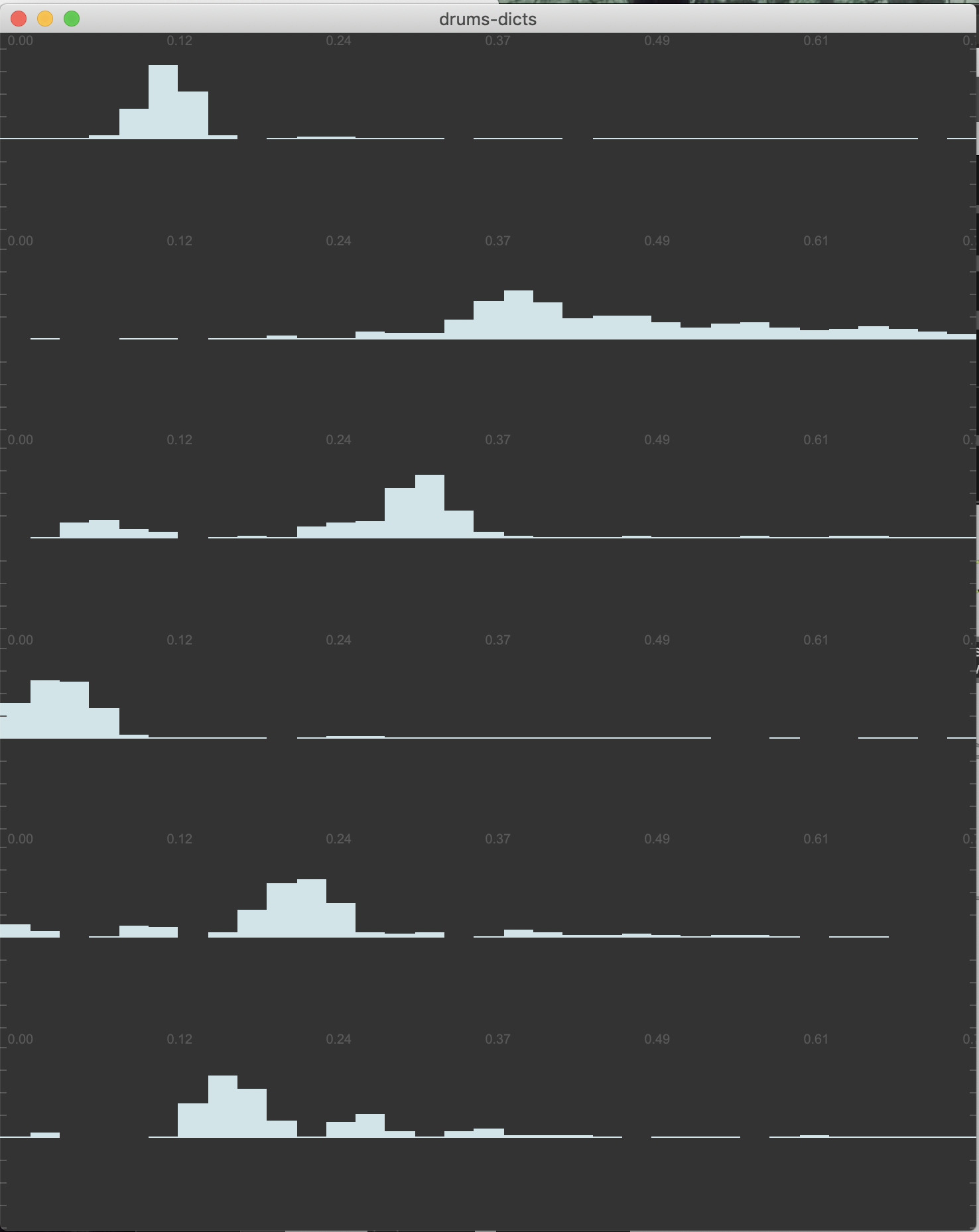
So in the course of preparing files and testing for the processes discussed in the Training for real-time NMF thread, I’ve been using some computationally expensive “off-line” iZotope processing on the audio coming from the Sensory Percussion sensors.
The raw audio from these is pretty noisy, with a fair amount of hiss, and fairly high-mid hyped natural EQ sound. I imagine the frequency, and more importantly, transient, response is part of what makes them effective, but the noise is probably problematic.
So in prepping the files for training, I’ve used iZotope on them to denoise, dehum, along with some fairly high hipass-ing.
This works fine, but in terms of doing this in real-time, there’s probably better ways to go about this.
Below are some examples of the audio (before, and my “after”) so you can hear, but is it just as simple as slapping on some EQing? Is it worthwhile making an IR of, what I imagine is fairly consistent “noise” coming from it, and deconvolving that against the live input?
Basically I need to massage this signal some, and I pretty much plan on using it only in a FluCoMa-y (at the moment, NMF-y) context (only for training/matching, never as “audio”). So I figured I could just massage it in the direction that would produce the most “meat” for the initial classification, and then real-time matching algorithm(s).
Obviously the noise/hiss isn’t useful, but I wouldn’t want to throw out too much of the high end, as there’s useful stuff up there.
Here is the unprocessed “raw” audio:
Sensory Percussion Raw.wav.zip (957.1 KB)
Here’s a nice and cleaned “after” audio:
Sensory Percussion Cleaned.wav.zip (942.9 KB)