@tremblap sent out the link to @b.hackbarth’s (http://www.benhackbarth.com/)'s talk on AudioGuide out via email the other day, so I imagine most people got it, but figured it was worth making a post as there are lots of interesting ideas here.

Here are some thoughts I had, somewhat unpacked.
////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
It was interesting to hear the thinking and discussion on normalizing vs standardizing, and whether this is per dimension or across all dimensions. Definitely resonates with a lot of the sanitization stuff being discussed with the FluCoMa bits.
It was particularly interesting with regards to pitch, as you can match direct matches, but that leads to potentially problematic things (which @tremblap offers some interesting workarounds for in his paper from a few years ago). OR just matching the overall trajectory, which is useful for certain circumstances.
////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
This was a passing comment, but it was interesting to hear him mention that having too many (similar) descriptors tends to give shittier results and drifts towards a median where you get an “ok” match for each descriptor type, as opposed to a good match for any. So kind of a (curated) less-is-more approach.
I wonder if that still holds true in the context of dimensionality reduction, or is part of the idea with the reduction stuff, that the algorithm(s) iron out and throw away useless information, letting you take a more more-is-more approach to descriptors/stats?
////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
His multi-pass approach is also super interesting, and similar to the workflow(s) I’ve been using in entrymatcher and am trying to work out in fluid.land~ here. Even putting aside stuff like I mention in that thread about meta-data-esque searching on duration or other conditional queries on “simple” descriptors (e.g. loudness > -20dB), the fact that queries can be chained seems like it could be super useful still.
Say you have like 150 dimensions, and like 40 of them relate to loudness-y things, and the rest are timbral ones. To have a query where you find the nearest neighbor(s) for loudness, and then from that small pool, search for the best timbral match etc…
I guess you can do stuff like that with fluid.datasetquery~, but the speed of that is pretty slow (for real-time use anyways), and it seems more like trying to shoehorn that way of thinking into the current tools/paradigm (a single long-thin stream with no tags).
////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
I’m not entirely sure I understood what was happening with regards to time series, but unless I’m mistaken, I think he was saying that rather than (only) taking average statistics for each segment (ala fluid.bufstats~) he will take numbers per frame, to retain the temporal aspects of the sound.
Is that right? If not, how does he retain such a clear temporal shape in the matching?
Some of the LPT approach is a way to mitigate this I guess, where you manually segment a segmentation (both via fixed durations) and use the summed statistics for those windows to inform a temporal shape.
I’ve personally not tried this (yet), but is it a thing to take all the analysis frames for a given window/segment and query that way? I could see that being an insane amount of numbers very quickly.
////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
Sadly, the briefest part of the video was the discussion on how layering works, as I was trying to conceive some of how that works in this thread.
So my take away from this is that his implementation is (much!) simpler than I was initially thinking, where you would compare every possible combination ahead of time and then query based on that. From my understanding, AudioGuide does a normal query, finds the nearest match, and then subtracts the amplitude from the target and then searches using the remainder of that.
It also seems that when doing layering, that samples can be mosaicked and offset from the start, which circles me back to the matching-per-frame thing mentioned above.
The part I especially found interesting was the way timbral descriptors are treated. Where “weighted sum of the weighted average” (?) gives you an idea of how the timbral descriptors might sound when summed.
So does that mean that if I sum two samples:
centroid = 800Hz, loudness = -20dB
centroid = 1200Hz, loudness = -10dB
I would presume that the results of summing them would be:
centroid = 1000Hz, loudness = -15dB
(or maybe the centroid would be 979Hz instead if the summing/averaging happens in the log domain):
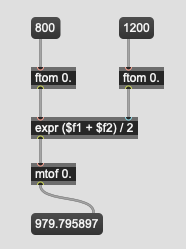
And something similar would also apply to rolloff, flatness as well? (also including spread and kurtosis?)
So in summary, my (poor) understanding of the layering is that it will make a first pass like it does for normal matching to find the nearest sample (via whatever descriptors/method/whatever).
That then leaves a remainder (based on amplitude only?).
It will then query all the potential matches again on how they would sum with the best match based on the maths above, and select that. Then this process would repeat for as many layers as are requested/desired.
